こんにちは。
みなさんは、MAGELLAN BLOCKSの文書検索エンジンというサービスはご存知でしょうか??
文書検索エンジンとは、あらかじめ質問と回答のデータを登録しておくだけで、ユーザーが日常会話の自然言語で質問するとその質問に最も適切な回答を自動で抽出・回答してくれるAIサービスです。
今回はこちらの文書検索エンジンの業務応用例として、ビジネスチャットツールのSlackと連携したChatOps(チャットオプス)の構築事例を紹介します。
(注意)
最初にお断りしておくと、本ブログはSlackから文書検索エンジンのAPIを実行してChatOpsを実現する内容が主となっており、回答予測を行う文書検索エンジンの構築・構成などは内容に含まれていません。
なぜ文書検索エンジンでChatOpsなのか・・・?
そもそもChatOpsとは、チャットインターフェースのボットを介して特定の命令をすることで業務を自動で行ってもらい業務改善につなげるというものです。
例えば、Slackでボットに対して、
@bot command-deploy
と投稿するとプログラムをデプロイしてくれるといった感じですね。特にIT部門やテック系企業での活用が盛んです。
しかし、一般的なChatOpsはUIこそチャットですが、命令自体は非常にシステムライクでビジネス部門からは難色を示されるケースが少なくありません。
しかし文書検索エンジンを利用すれば「経営レポートを見せて」や「MAGELLAN BLOCKSの文書検索エンジンについて教えて?」といった感じで、我々が普段業務で使っている自然言語でボットに対して命令をすることができます。
もちろん、単純に命令にしたがって処理を実行するだけでなく、文書検索エンジンの最も得意とする質問に対して適切に回答するということも行えますので、同時にFAQや問い合わせサポートの機能も備えることができます。
このように文書検索エンジンを利用したChatOpsは、システム部門だけでなくITリテラシーのさほど高くないビジネス部門の業務改善にも適しているという特徴があります。
今回の構成
今回の構成は以下のとおりです。
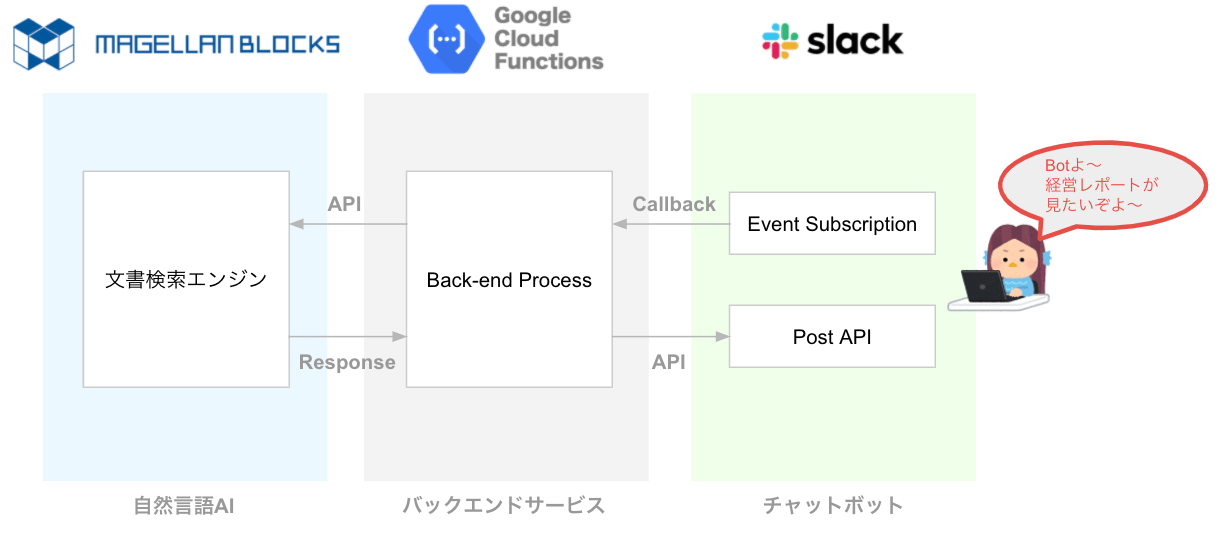
チャットUI・チャットボットはSlack、チャットボットからの処理を受け付けるバックエンドサービスはGCPのサーバレスな関数実行環境であるGoogle Cloud Functions、そしてAI/自然言語処理はMAGELLAN BLOCKSの文書検索エンジンを利用します。
なお、文書検索エンジン以外は自社の利用ツール・アプリや環境に合わせて変更可能です。
チャットUI・チャットボットであればMicosoft TeamsやChatworkなど。
バックエンドサービスはAWS Lambdaや、サーバーレスでなくともオンプレミス環境のWeb/APサーバーでも問題ありません。
文書検索エンジンの設定
では具体的な実装に入っていきましょう。
まずは文書検索エンジンの設定です。
なお、文書検索エンジンの構築は完了している前提とします。
今回は文書検索エンジンに登録するデータとして以下のデータを準備しました。
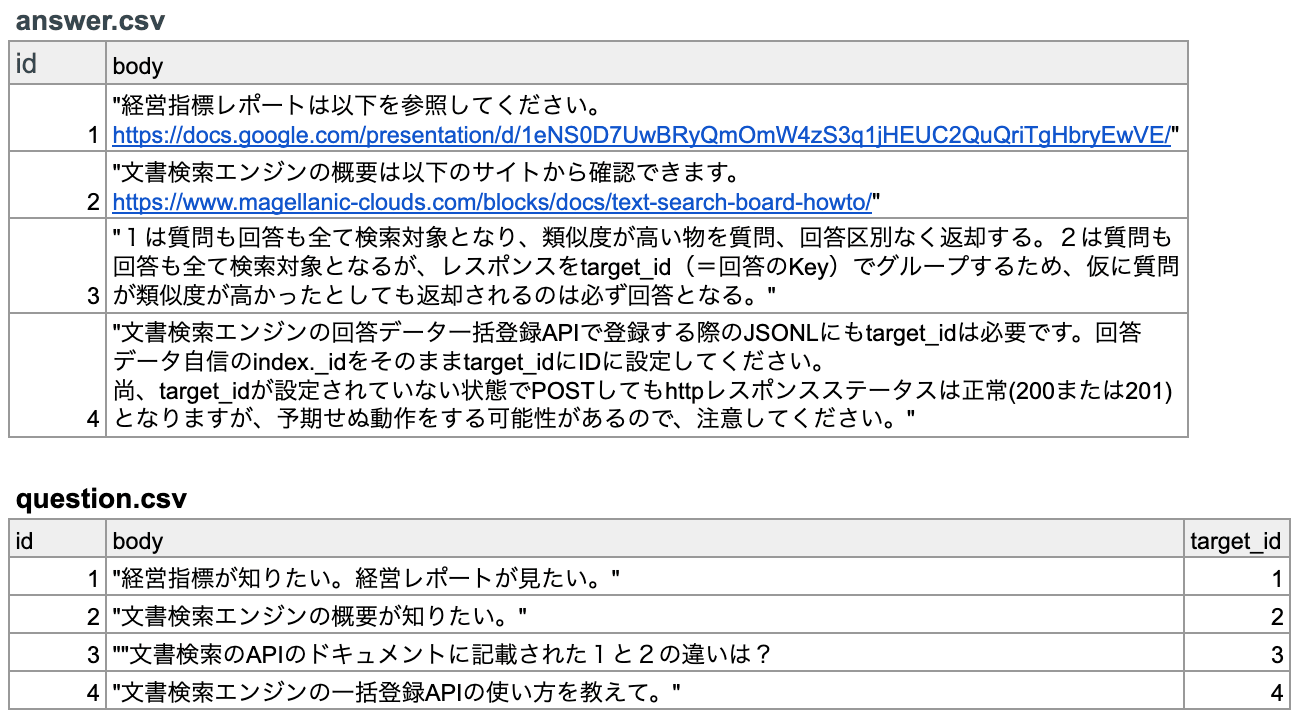
回答、質問1番が「経営指標のレポートを見たい」という質問(命令)に対する回答です。
回答、質問2番以降が文書検索エンジンに関するFAQ機能という想定です。
これらのデータを文書検索エンジンに登録すれば、Cloud Functionsから文書検索エンジンのAPIを実行して質問に対して最も適切な回答を取得できます。
Google Cloud Functionsの実装
次にGoogle Cloud Functionsでバックエンド処理を実装します。
今回はNodejsで実装しました。
javascript
const request = require('request');
// main処理
const onRequest = async (req, res) => {
let payload = req.body;
// SlackのBot User ID
var bot_user_id = payload.authed_users[0]
// Slack Bot のO Auth Access Token
const slack_bot_user_token = 'xoxb-[Slack BotのO Auth Access Token]'
// 文書検索エンジンの設定
const docsearch_ip = "[文書検索エンジンのIPアドレス/ポート番号]"
const docsearch_index = "[文書検索エンジンにインデックス名]"
const docsearch_url = `http://${docsearch_ip}/${docsearch_index}`
// Slack BotがmentionされてEvent Subscriptionされた時の処理
// Slackに対してhttp200を返却
res.sendStatus(200);
// 改行を半角psaceに置換して質問文を生成
var question = payload.event.text.replace(/\r?\n/g,' ');
question = question.replace(`<@${bot_user_id}>`, '');
// 文書検索エンジンAPIのリクエストボディ(今回は上位1件のみ回答IDを取得)
var options = {
"url": `${docsearch_url}/target,hint/_search`,
"method": "GET",
"headers":{
"Content-type": "application/json",
},
"timeout":3000,
"json": {
"_source":{
"excludes":[
"body"
]
},
"size":1,
"query":{
"match":{
"body":question
}
},
"collapse":{
"field":"target_id"
}
}
}
// 文書検索エンジンに対してリクエスト実行
request(options, async function (error, response, body) {
if (error) {
console.log(error);
return res.end();
} else {
var json_str = JSON.stringify(body);
var json = JSON.parse(json_str);
// hit(適切な回答数)が0件でないかどうかの判定
if (json.hits.total != 0) {
// 回答用の配列の準備
var target_id_array = new Array();
var answer_array = new Array();
// 取得した回答の上位1件まで取得
for (i = 0; i < json.hits.hits.length; i++) {
target_id_array.push(json.hits.hits[i].fields.target_id[0])
}
// 取得したtarget_idの回答文を検索
for (i = 0; i < target_id_array.length; i++) {
answer_array.push(await syncGetAnswer(`${docsearch_url}/target/` + target_id_array[i]))
}
var options = {
"url": "https://slack.com/api/chat.postMessage",
"method": "POST",
"form": {
"token":slack_bot_user_token,
"channel":payload.event.channel,
"text": answer_array[0]
}
};
request(options, function (error, response, body) {
console.log(body);
});
} else {
var options = {
"url": "https://slack.com/api/chat.postMessage",
"method": "POST",
"form": {
"token":slack_bot_user_token,
"channel":payload.event.channel,
"text": "該当する文書がありませんでした"
}
};
request(options, function (error, response, body) {
console.log(body);
});
}
}
})
return res.end();
}
// 回答IDから回答文を取得して返す同期関数
const syncGetAnswer = async (url) =>{
return new Promise((resolve, reject) => {
var options = {
"url": url,
"method": 'GET',
"timeout":3000
}
request(options, function (error, response, body) {
if (error) {
console.log(error);
reject(error);
} else {
var json = JSON.parse(body);
resolve(json._source.body)
}
})
});
}
exports.docsearch_bot = onRequest;
コードの20, 21行目でSlackに入力された質問文を取得しています。
コードの23行目〜50行目で上記質問文をパラメータにして文書検索エンジンに対してリクエストを実行しています。
まず「質問から回答IDを検索」のAPIを実行し、62行目〜65行目で質問に対して最も適切な回答の回答IDを取得し、次に66行目〜69行目でその回答IDをKeyにして「特定の回答を取得」のAPIで回答文を取得しています。
最後にコードの70行目〜79行目でSlackのchat.postMessage APIを利用してSlackに対して回答を送信しています。
ソースコードのデプロイは以下のgcloudコマンドで実行します。(gcloudコマンドのインストールはGCPのCloud SDKのサイトの手順に従ってください。)
gcloud functions deploy docsearch_bot --runtime nodejs10 --trigger-http --region=[デプロイ先のRegionを指定] --vpc-connector=[サーバーレスVPCアクセスコネクタを指定]この際、注意点が一つあります。文書検索エンジンのAPIは同一VPCからしかアクセスが許可されていません。そのためCloud Functionsからはそのままでは文書検索エンジンのAPIを実行できません。
GCPにはサーバレス環境からVPC環境のリソースにアクセスするための、サーバーレスVPCアクセスコネクタというサービスがあり、Cloud Functionsのデプロイ時に利用するコネクタを指定することができます。
サーバーレスVPCアクセスコネクタの詳細や設定方法はGCP公式ドキュメントを参照してください。
Slackの設定
最後にSlackの設定です。
Slackでチャットボットを実現する方法はいくつかありますが、今回はSlackからCloud Functionsへの通信はSlackのEvent Subscriptionという仕組みを、Cloud FunctionsからSlackへの通信は上述のとおりSlackのAPIを利用します。以下の画面のとおりSlack Appの設定を行ってください。
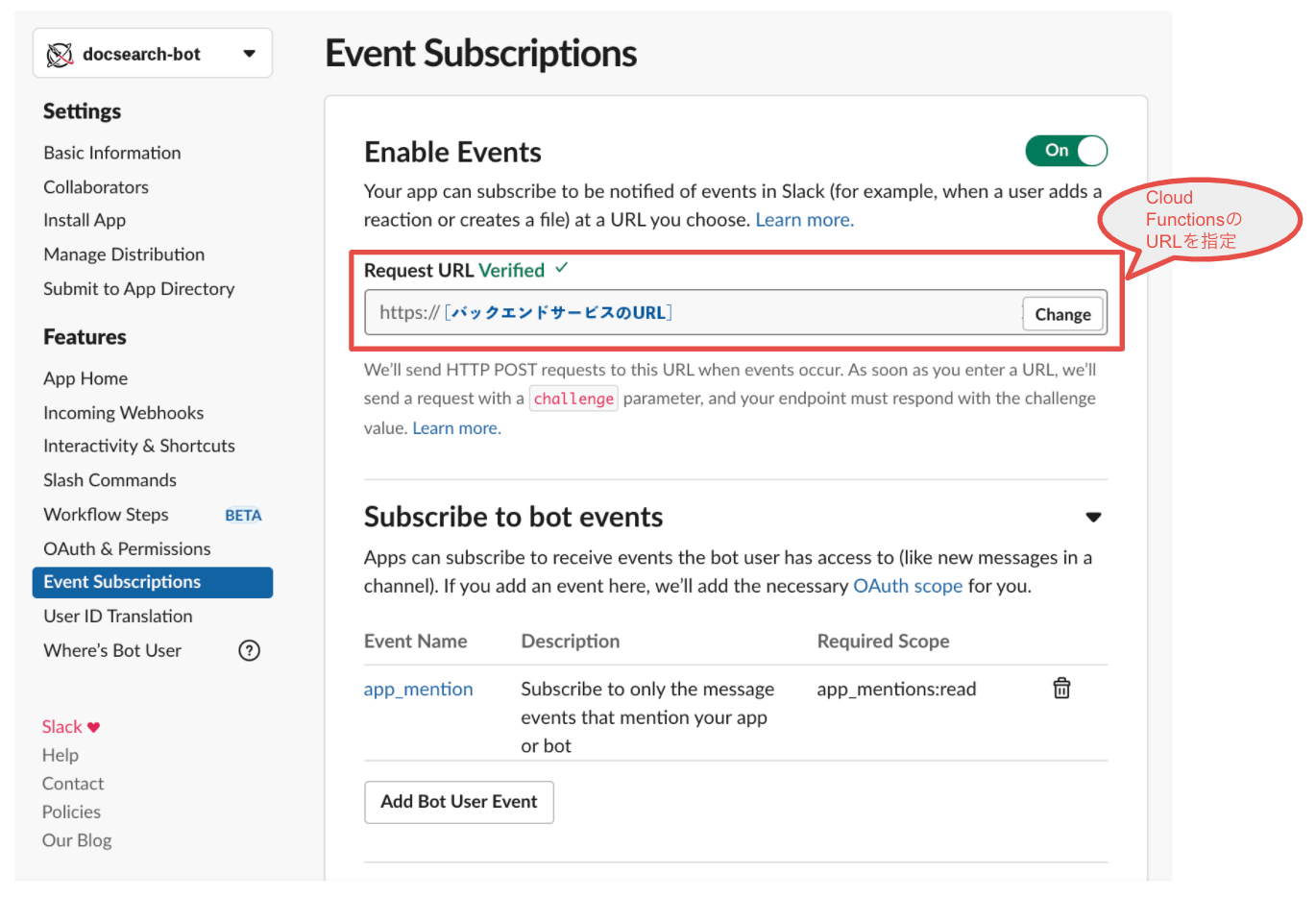
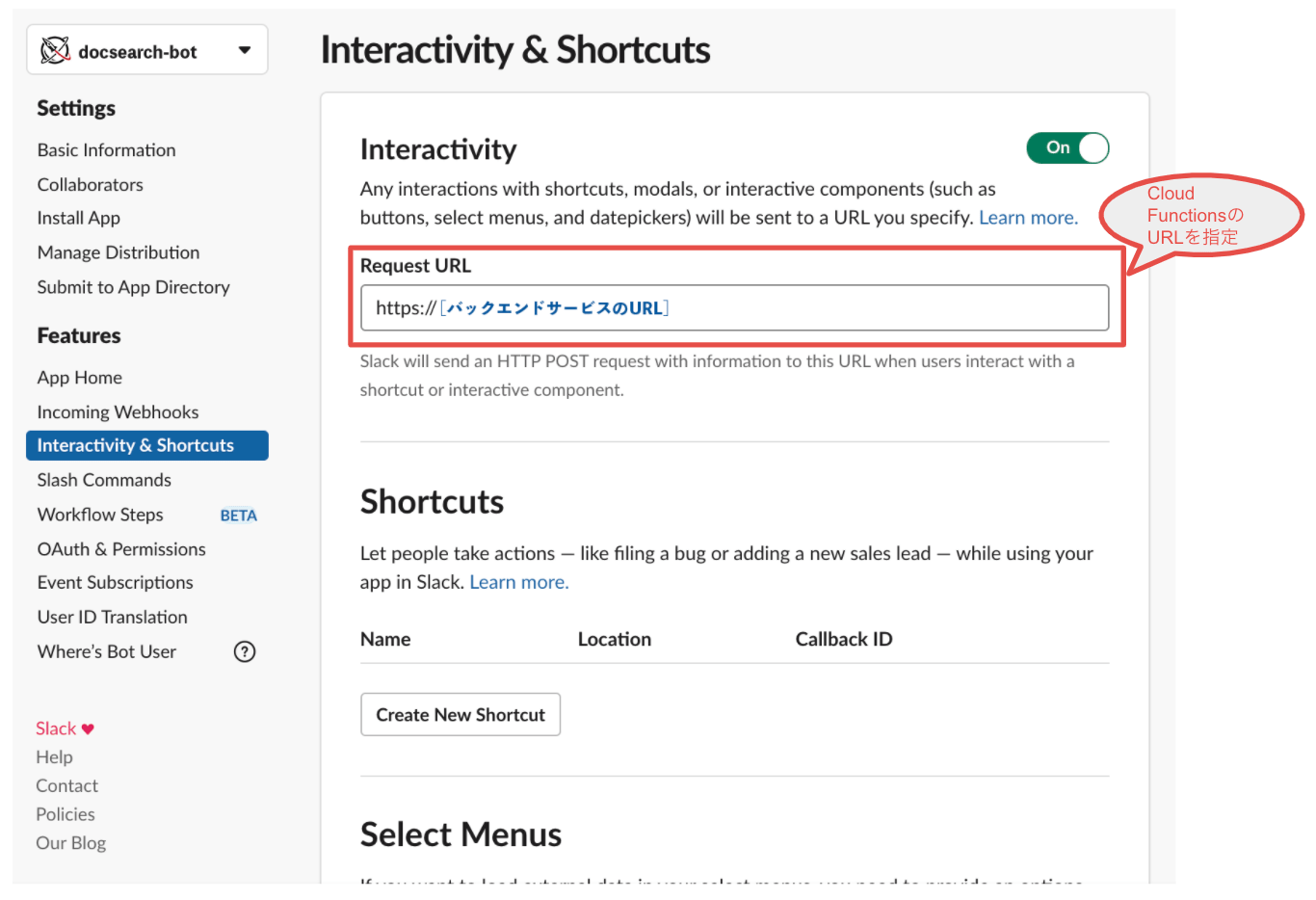
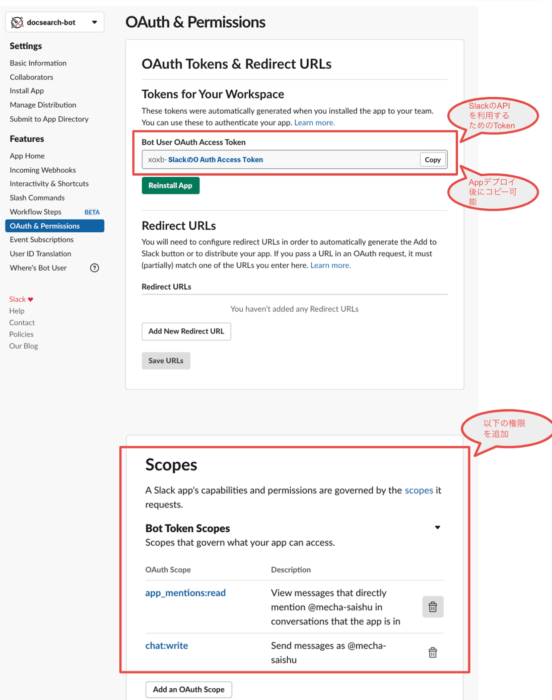
設定が完了したらSlack AppをワークスペースにデプロイしてO Authアクセストークンを取得し、Google Cloud Functionsの9行目のslack_bot_user_tokenパラメータに設定してください。(注)
(注意)
実際の運用においてO Authアクセストークンは、ソースコード中に直接記載するのではなくセキュアな環境に保管して都度アクセスすることをお勧めします。また、バックエンドサービスもアクセス制限を加えたり、アクセストークンを利用しない限り、リクエストが実行できなくする認証処理を加えることをお勧めします。
いざ!実行!!
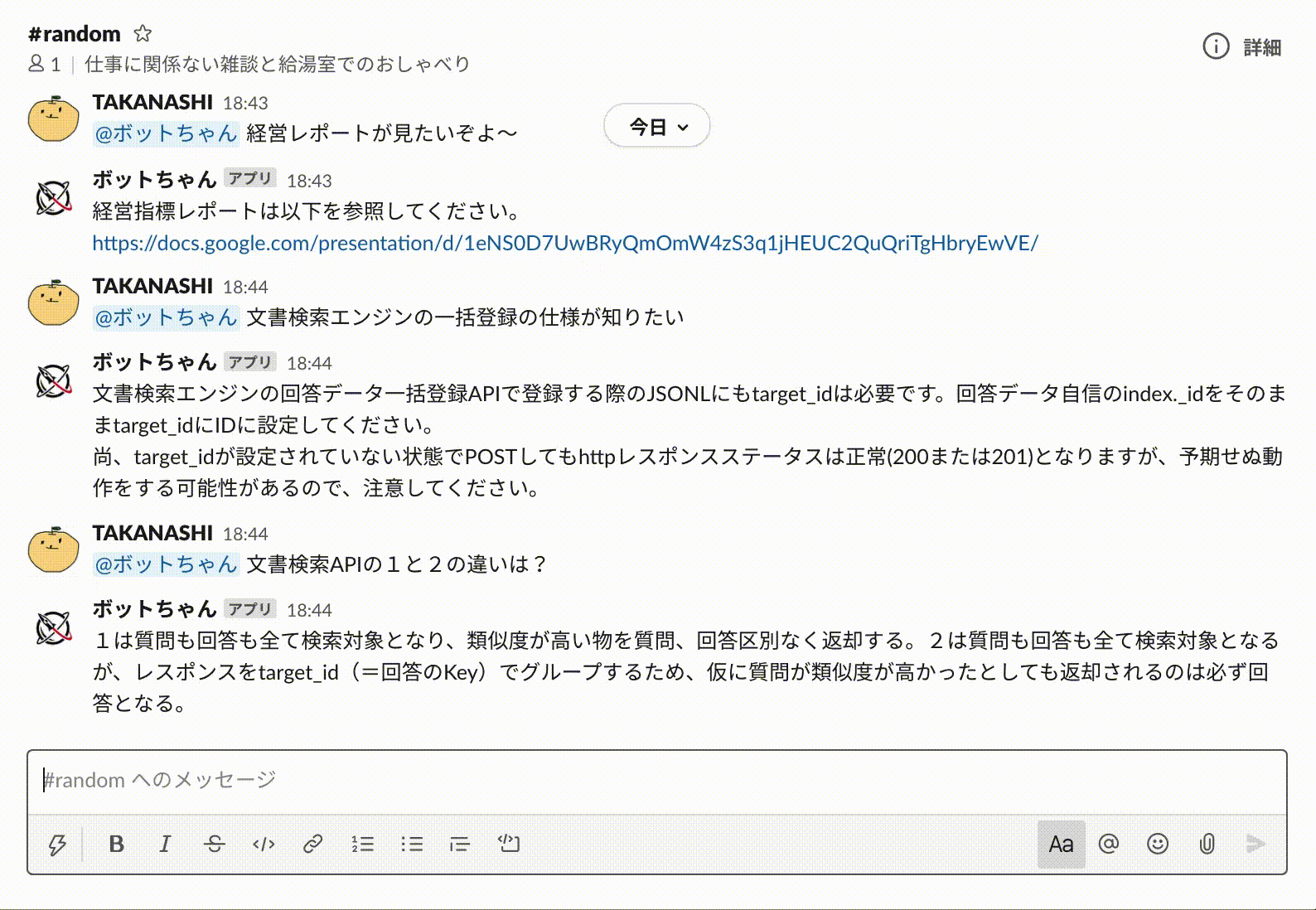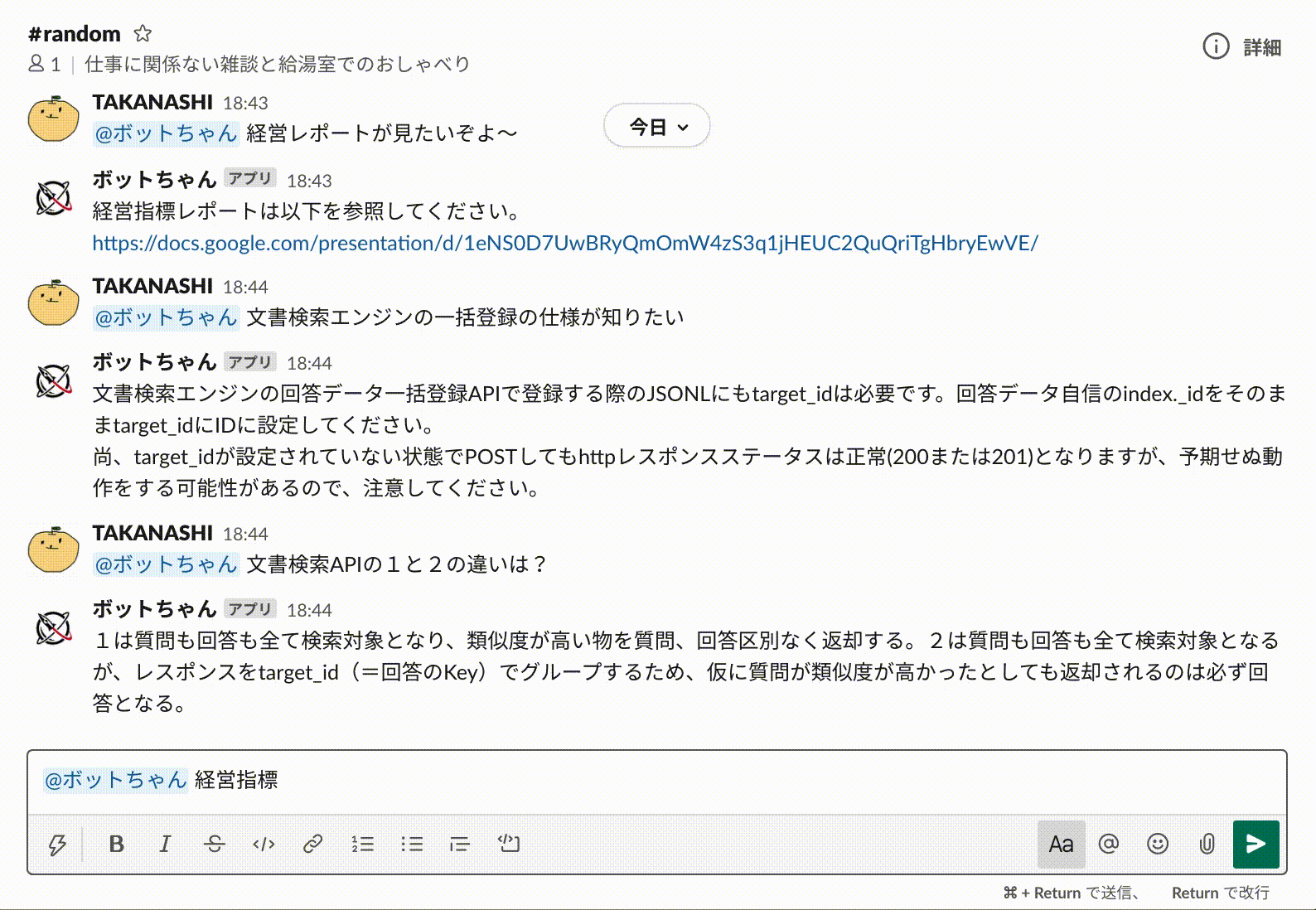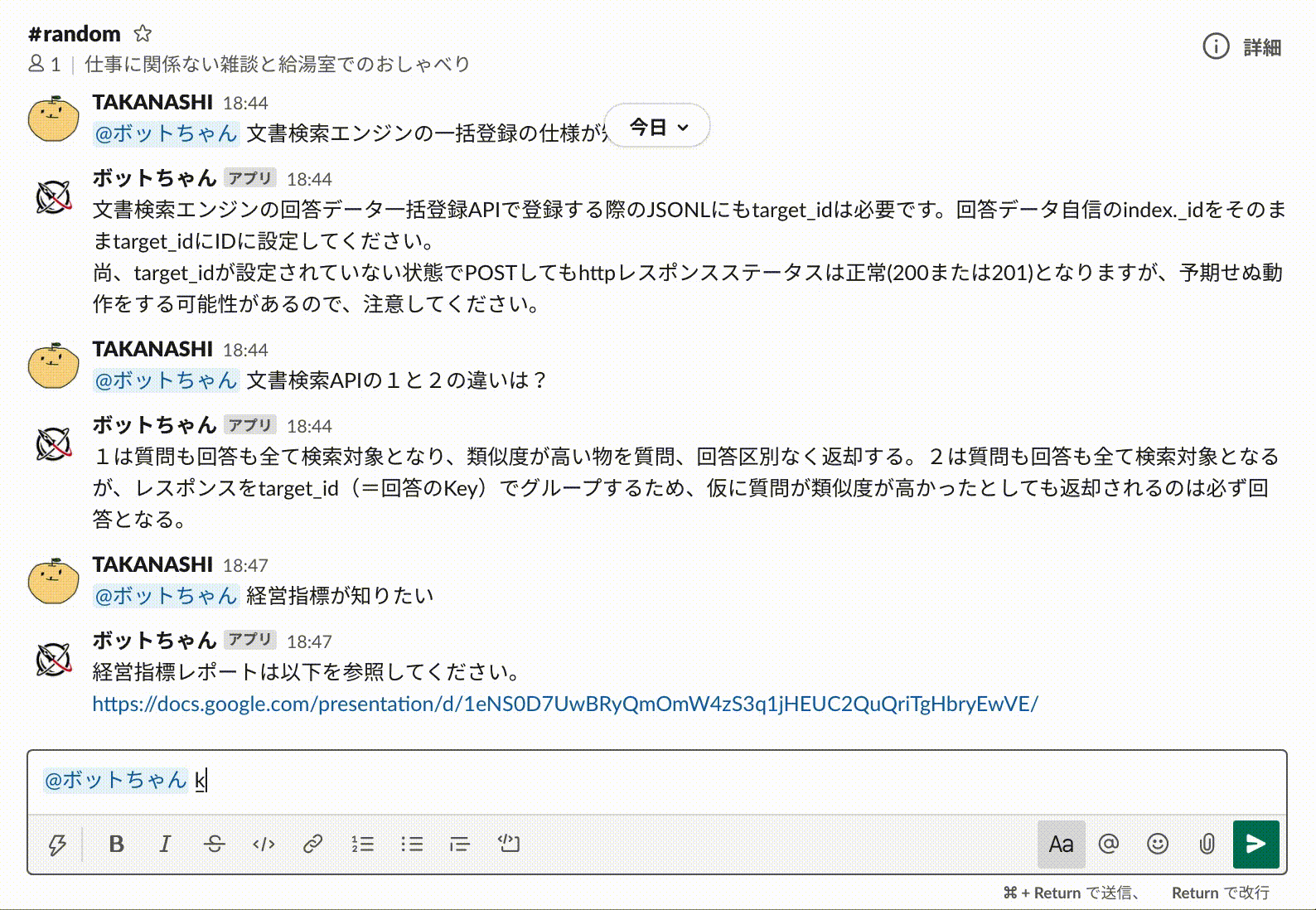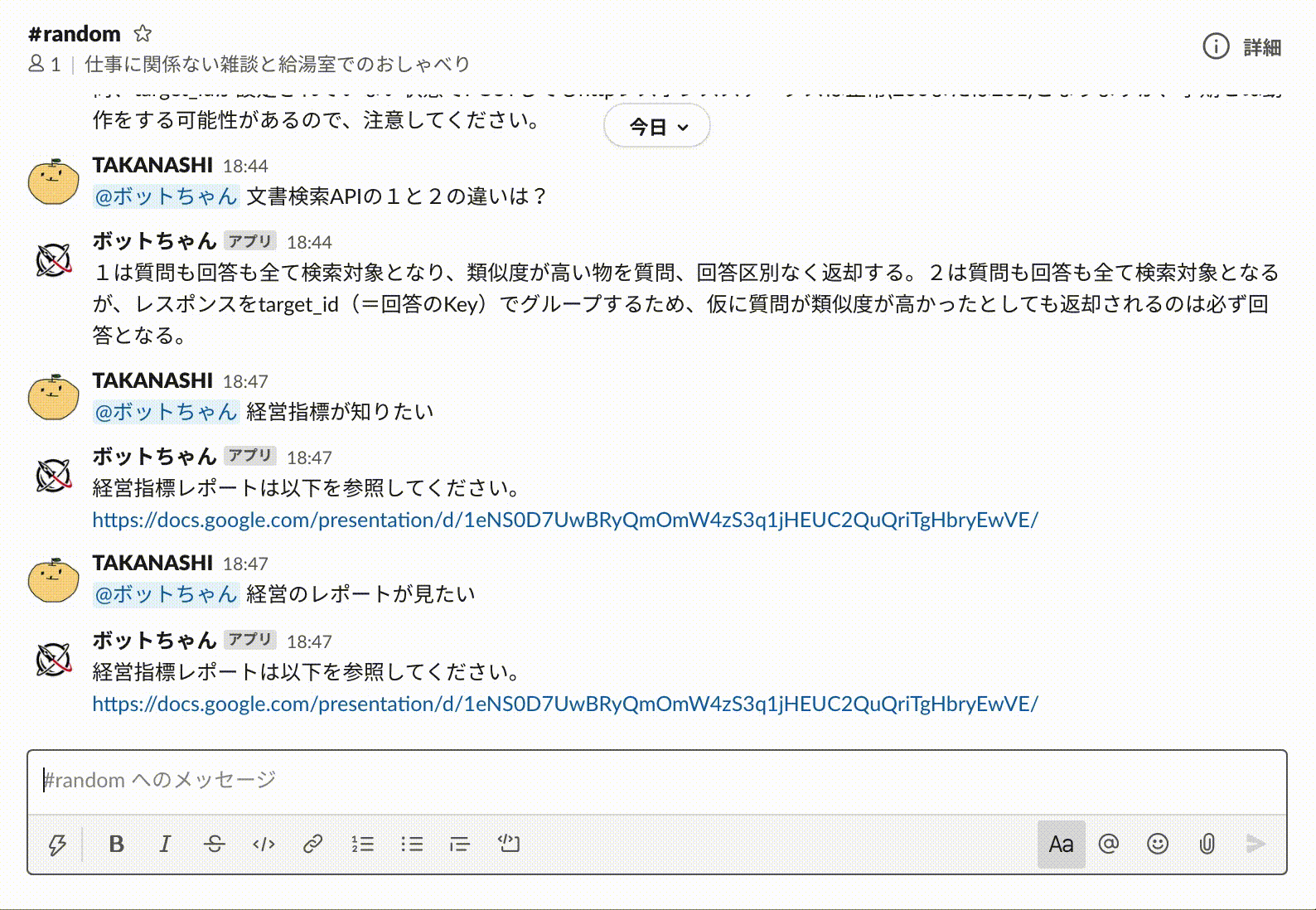
以上ですべての実装が完了しましたので、Slackから質問(命令)を実行してみましょう。
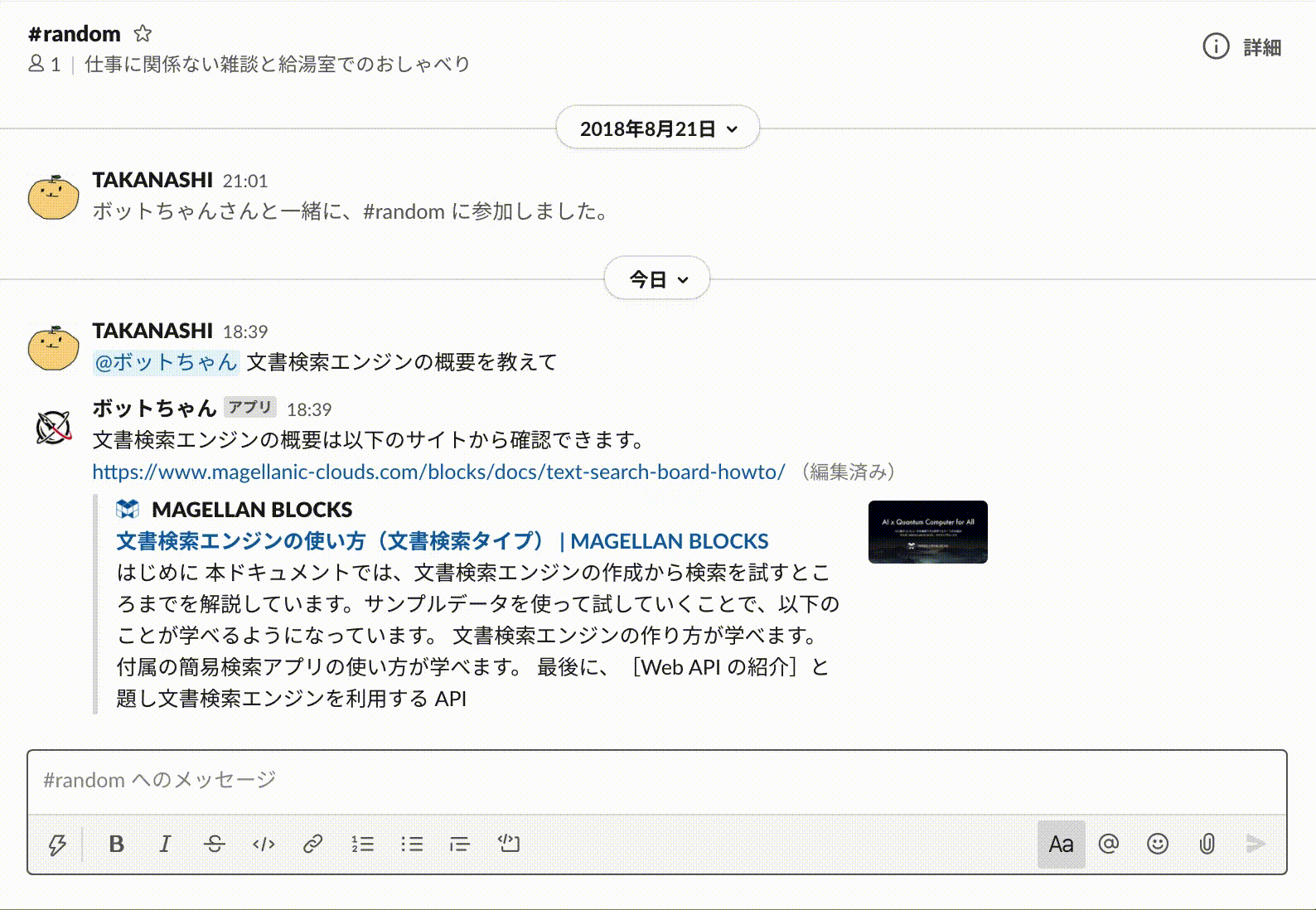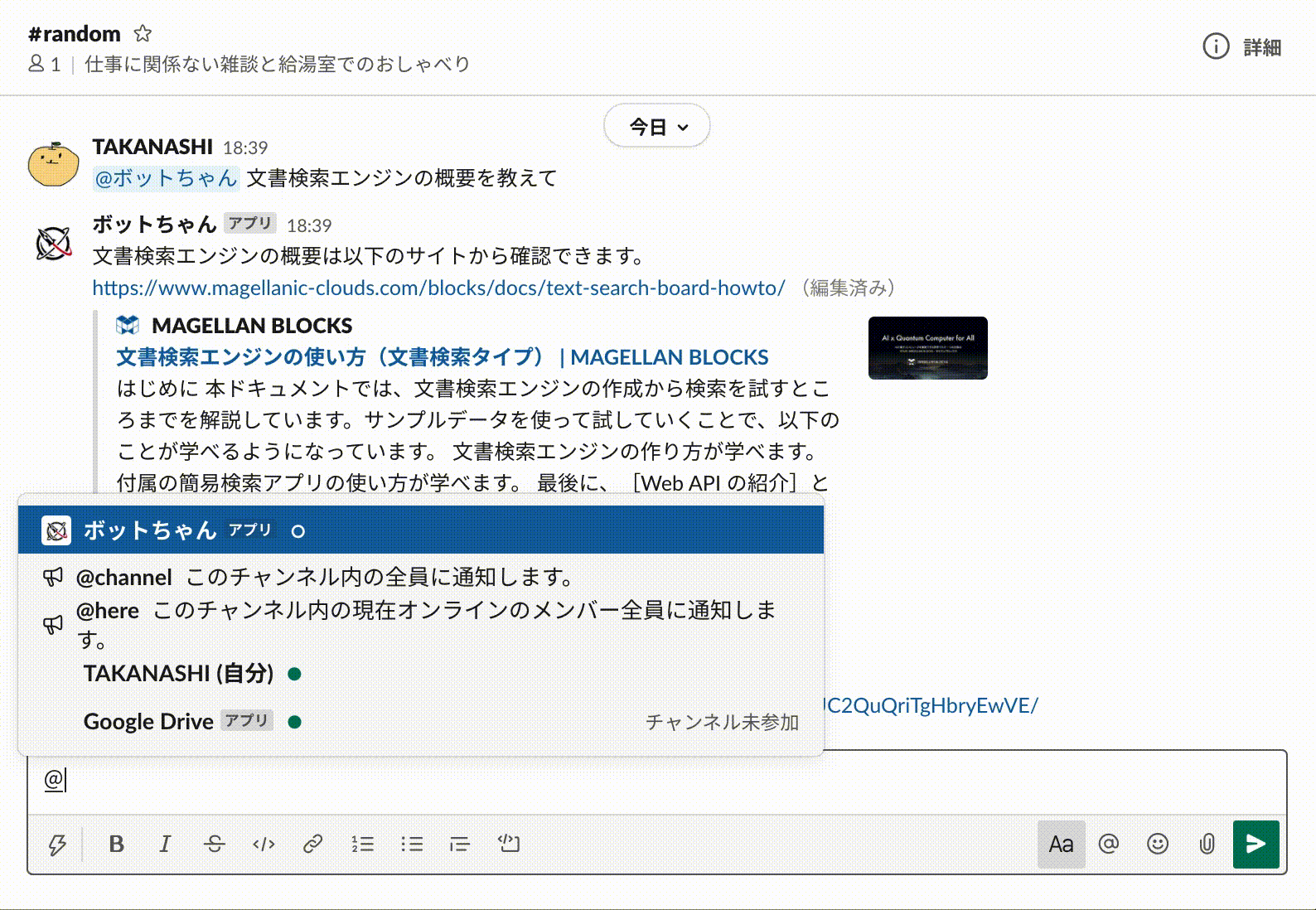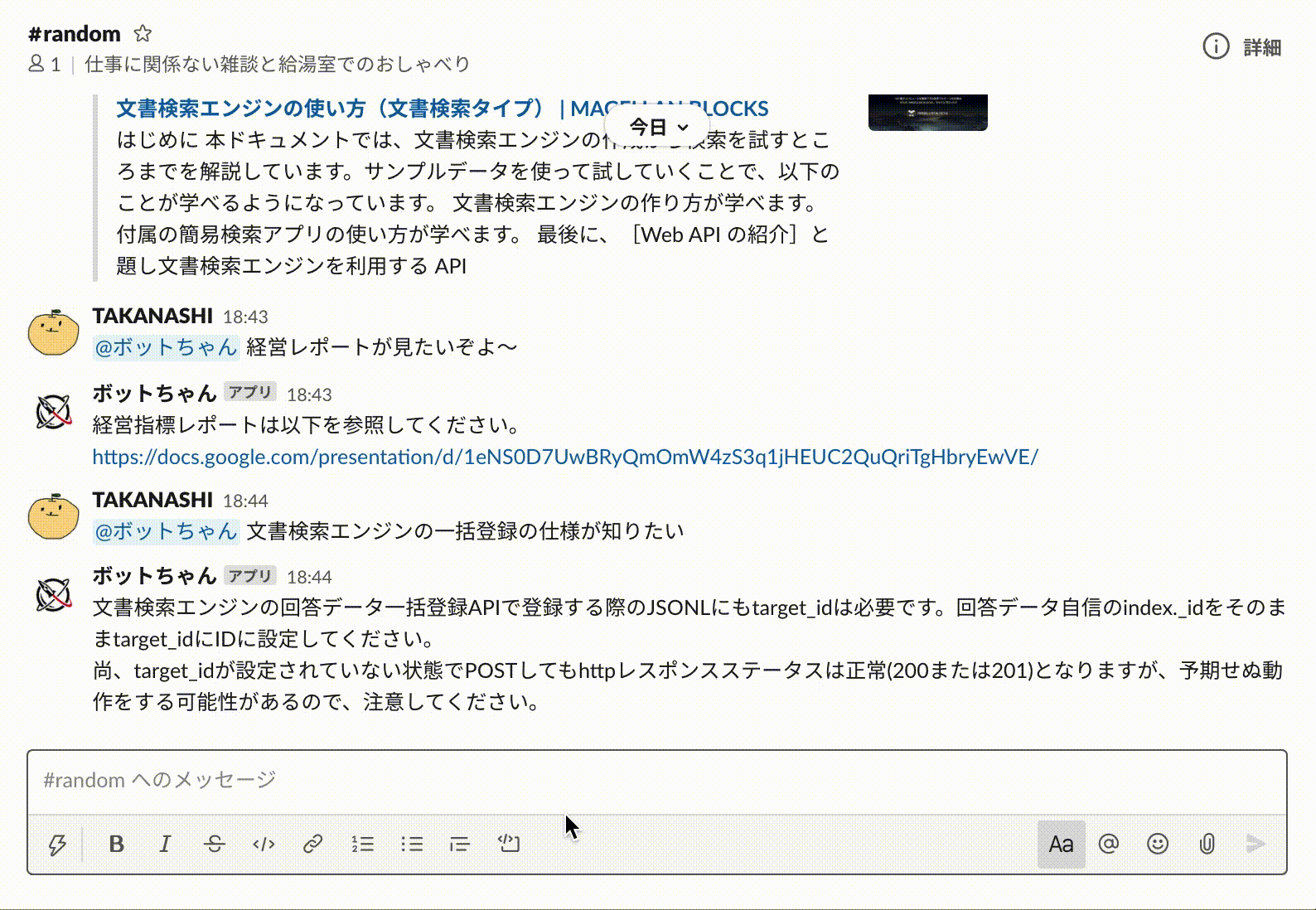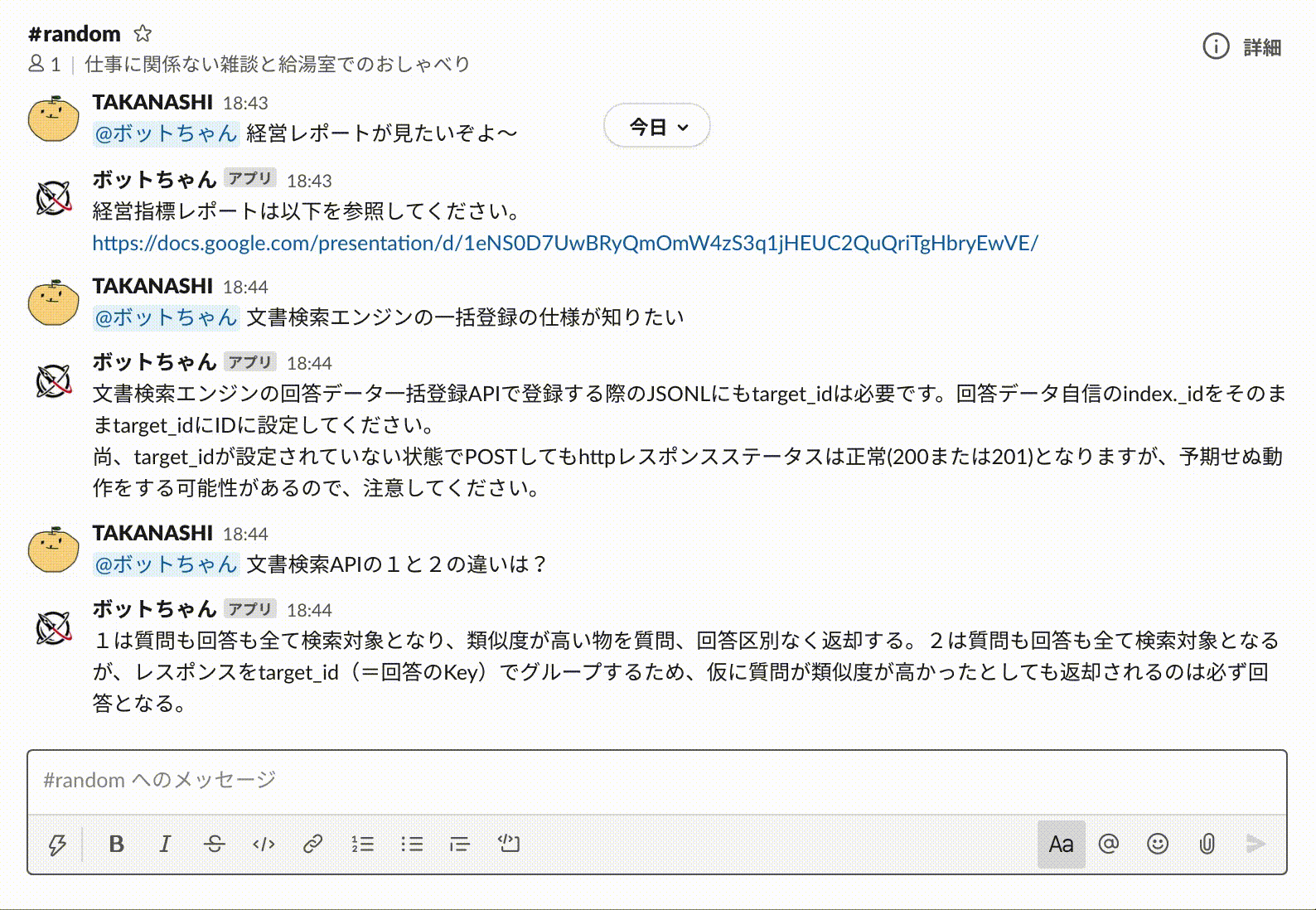
想定した質問(命令)に対して正しく回答してくれていますね。
もちろん自然言語特有の「経営指標」「経営のレポート」や「知りたい」「見たい」といった表現の揺らぎにもしっかり対応してくれています。
文書検索エンジンのレスポンスを受け取って、Cloud Functionsでそのレスポンス内容に応じてさらに処理を分岐させれば、より複雑なオペレーションにも対応可能です。
まとめ
いかがでしたでしょうか?
文書検索エンジンを利用することにより、自社でAI構築をすることなく簡単に自然言語によるChatOpsの実現ができることをご理解いただけたかと思います。
最後に、グルーヴノーツのコンサルティングサービスではSlack以外にもさまざまなチャットツールと文書検索エンジンとを連携させたChatOps構築のご支援もさせていただいています。
「自社の業務改善にChatOpsを導入したいが最適なやり方がわからない」というお悩みがございましたら、こちらのお問い合わせフォームよりお気軽にご相談ください。
最後までお読みいただきありがとうございました。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。