お初お目にかかります。グルーヴノーツ コンサルタントの高比良と申します。
私はコロナ禍の今年4月に入社した新米コンサルタントです。
前職のバックエンドエンジニア時代から、GCP、特にBigQueryが大好きですが、痒いところに手が届くユーザーインターフェースでGCPのパワーを最大限に引き出せるMAGELLAN BLOCKSの素晴らしさに感動する毎日です。
今回は、MAGELLAN BLOCKSのフローデザイナーで、CSVファイルをGCP上のクラウドストレージであるGCS(Google Cloud Storage)に配置したことを検知して、Googleスプレッドシートに自動出力するフローを作っていきたいと思います。
スプレッドシートで可視化?と思われる方もいらっしゃるかもしれませんが、実は意外にもいろいろなことができるんです。今、時系列データをガントチャート的にスプレッドシートで表現するのがマイブームになっておりまして、その方法をご紹介したいと思います。
目次
1. APIの有効化と出力先スプレッドシートの作成
はじめに、APIの有効化およびスプレッドシートへの権限追加のために、MAGELLAN BLOCKSで使用しているGCPプロジェクトとサービスアカウント名を確認します。
画面右上のプロジェクト名を選択し、歯車マークをクリックしてください。

左メニューから「GCPサービスアカウント」を選び、名前とプロジェクトIDを控えておいてください。
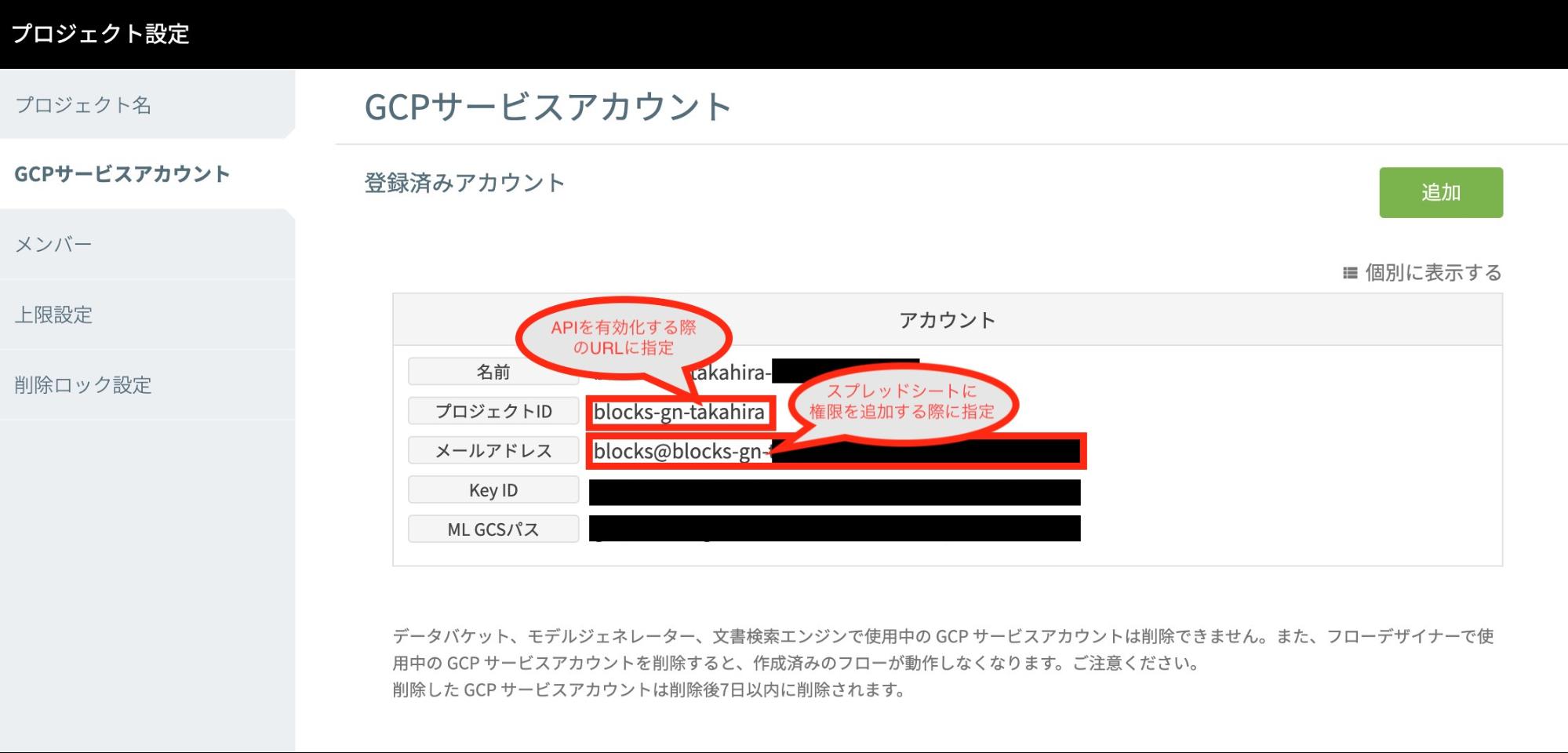
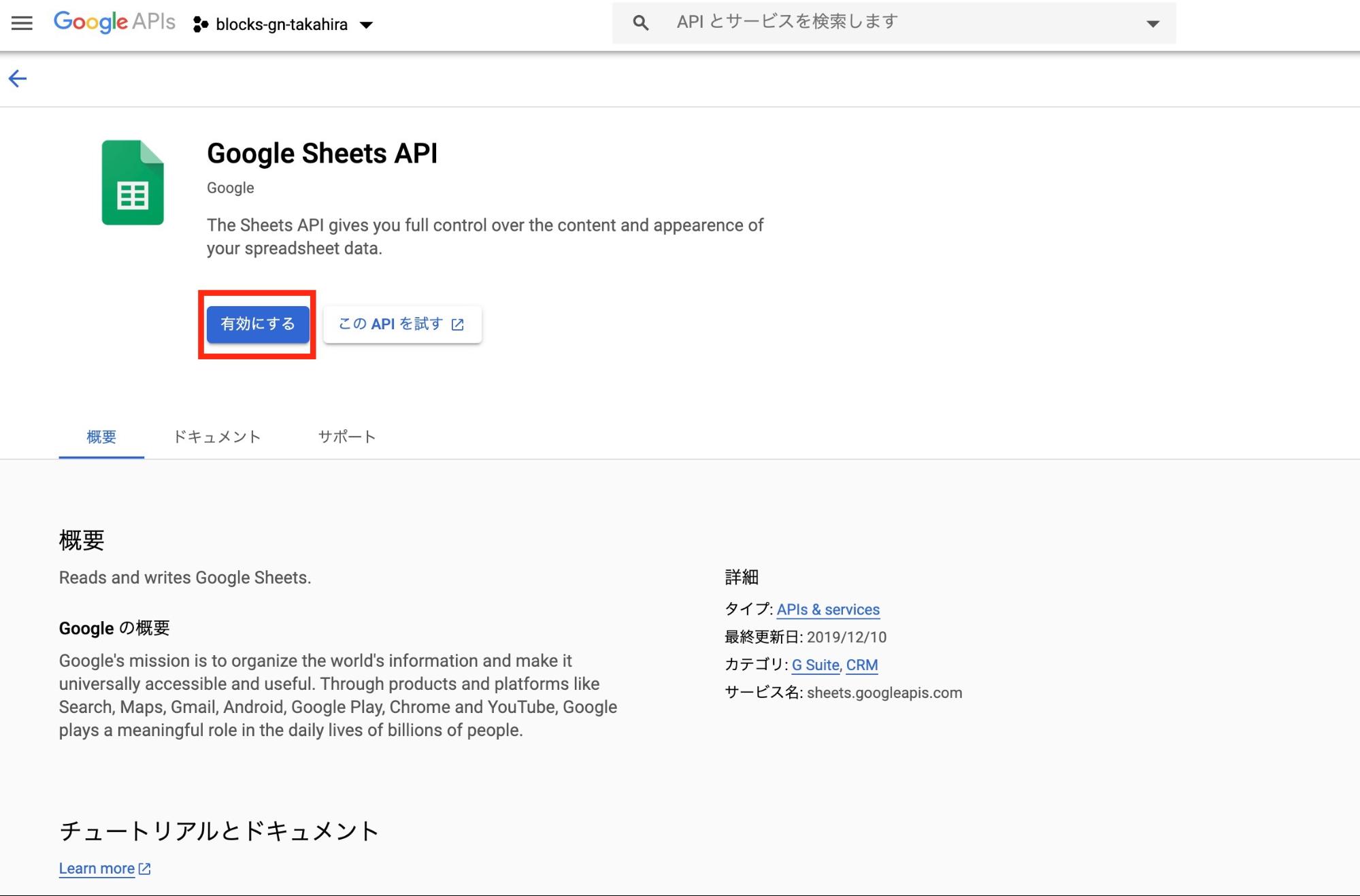
上記で控えたプロジェクトIDをコピーして、以下のURLを開き、「有効にする」ボタンをクリックしてAPIを有効化します。
https://console.developers.google.com/apis/library/sheets.googleapis.com?project=上記で控えたプロジェクトID
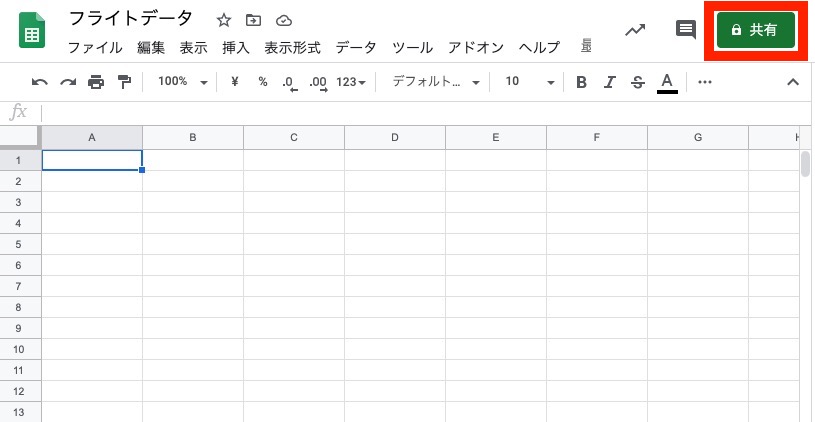
次に、出力先のスプレッドシートを作成して、サービスアカウントに編集権限を追加します。スプレッドシートを新規作成して、右上の「共有」をクリックします。
上記で控えたサービスアカウントのメールアドレスをコピーして、ユーザの追加欄にペーストし、「編集者」権限になっていることを確認します。通知は不要なのでチェックを外した後、「共有」ボタンをクリックします。
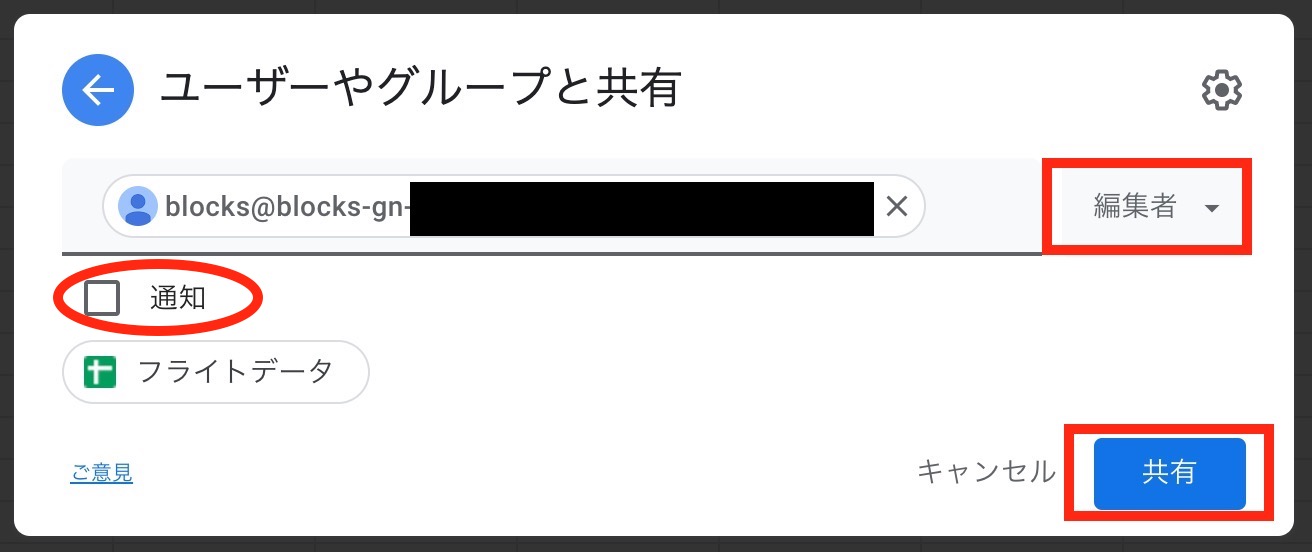
これで MAGELLAN BLOCKSからスプレッドシートに出力する準備ができました。
2. サンプルデータのダウンロードとGCSへの配置
サンプルデータとして、アメリカ合衆国運輸省が公開している、フライトデータを使用します。以下のダウンロードページを開いてください。
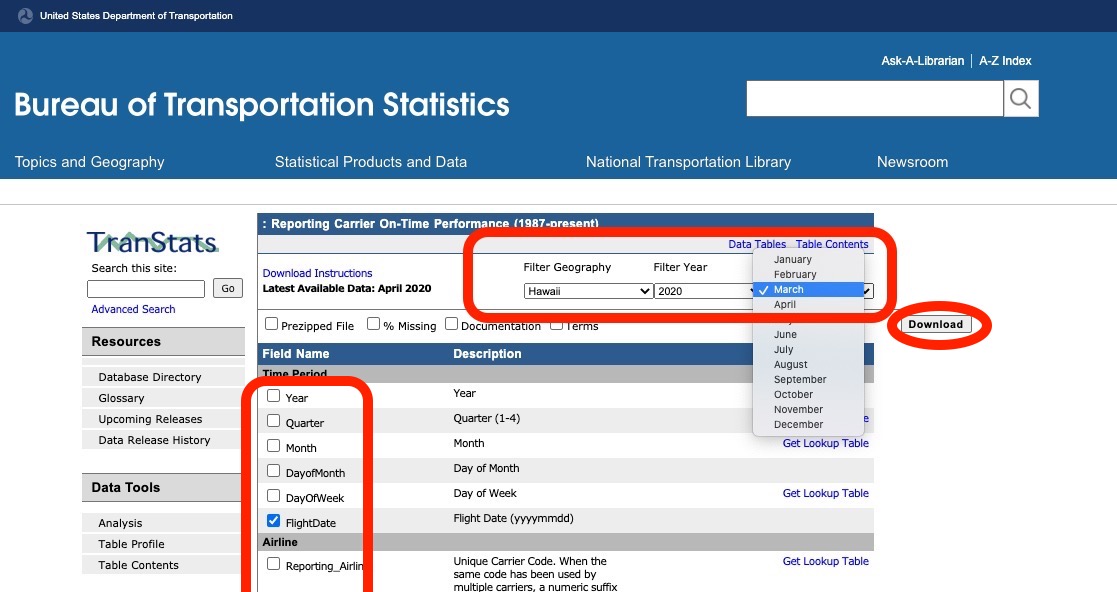
今回は、「Filter Geography」から「Hawaii」を選んで、ハワイ発着のデータを使用します。また、2020年7月20日現在で「Latest Available Data: April 2020」との記載があるので、「Filter Year」では「2020」を選び、直近2ヶ月 ※ の「March」と「April」を選びます。
ダウンロードする項目を選択できるようになっているので、「Field Name」から以下のフィールドをチェックして(デフォルトでチェックが入っているが使用しないものはチェックを外して)ダウンロードします。
- FlightDate:フライト日付
- Origin:出発空港
- Dest:到着空港
- CRSDepTime:予定出発時刻
- DepTime:出発時刻
- CRSArrTime:予定到着時刻
- ArrTime:到着時刻
※ ダウンロードしたファイルの一つ(1ヶ月分)を使ってフローを作った後、もう一つをGCSに配置して、フローが自動で起動することを確認するために、2ヶ月分をダウンロードします。以降の手順ではどの期間でも動作するため、2ファイルを用意いただければどの期間をダウンロードしても問題ありません。
次に、ダウンロードしたファイルの一つ(1ヶ月分)を、GSCにアップロードします。
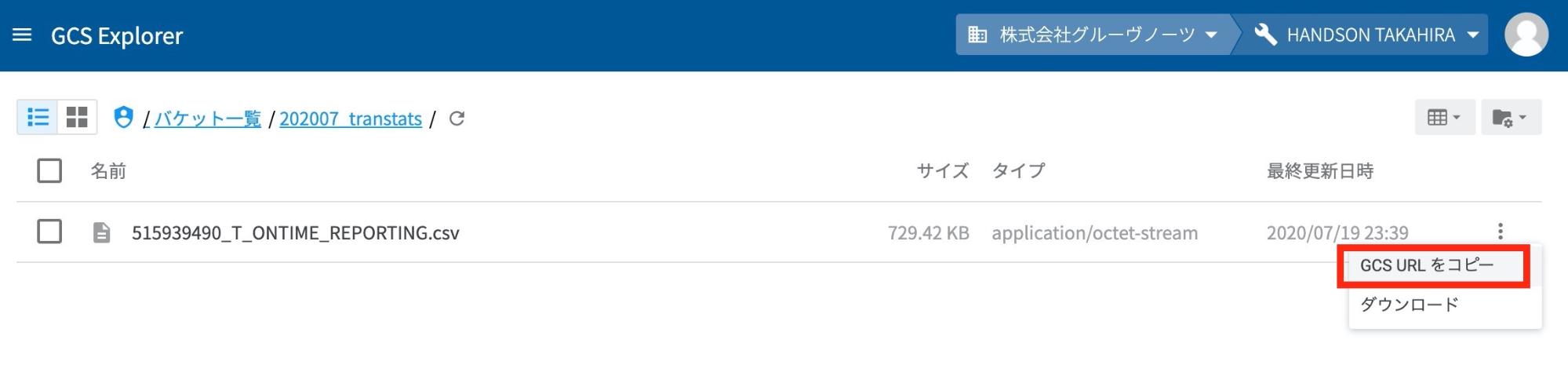
GCS へのアップロードは、GCS Explorerから行います。
アップロードしたファイルのURLを後ほど使用するので、GCS Explorerにて、ファイルの右側にある縦の3点リーダー "︙" をクリックして "GCS URL をコピー" しておきます。
3.フローデザイナーでデータ取り込み〜スプレッドシートに出力するフローの作成
フローデザイナー で、先ほど保存したファイルを取り込むフローを作成します。
最初に、画面左の "基本" から "フローの開始" のブロックをドラッグ&ドロップで配置します。
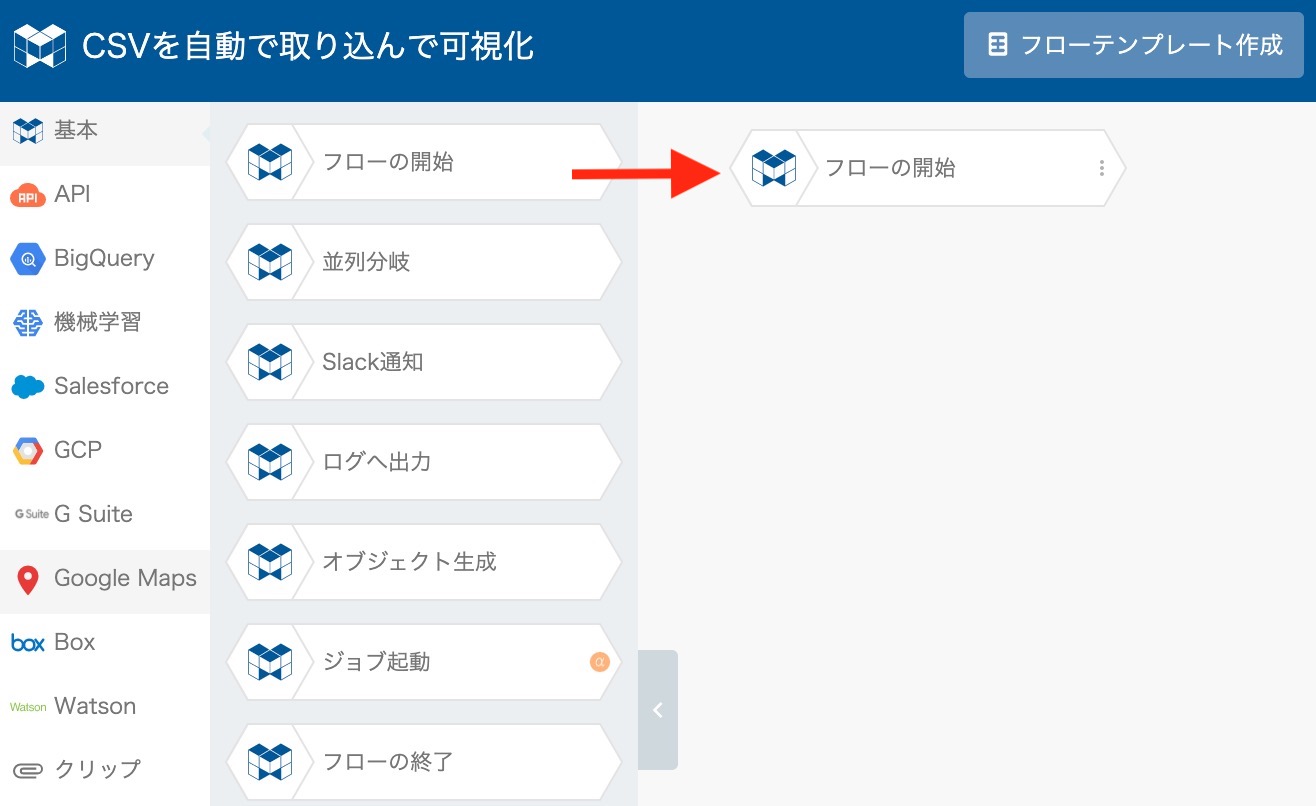
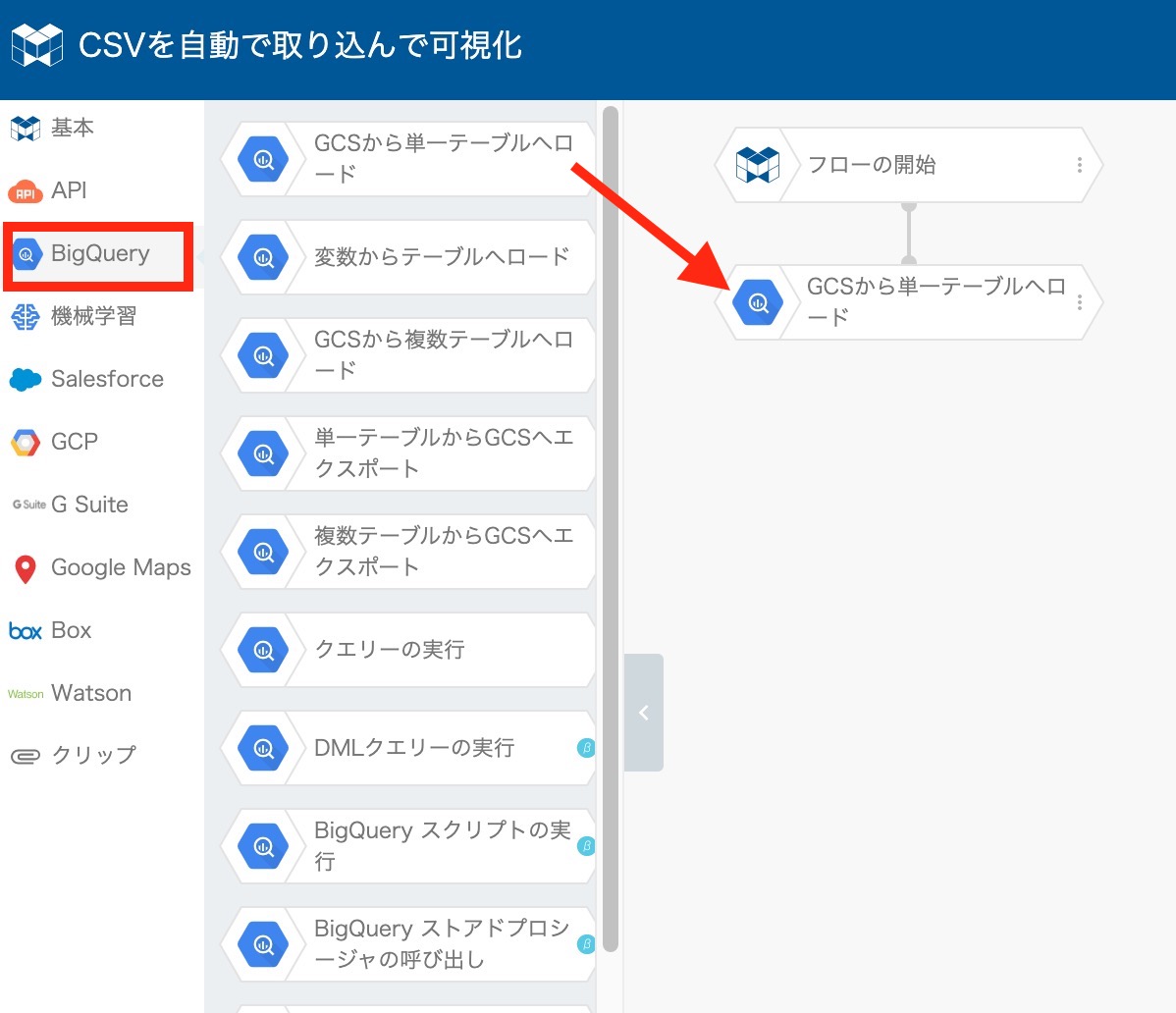
GCSに取り込んだデータをクエリを使って整形していくために、まずBigQueryに取り込みます。
左メニューの "BigQuery" をクリックし、 "GCS から単一テーブルへロード" のブロックを選んで、 "フローの開始" のブロックに重ねます。
(片方のブロックがハイライト表示されるようにブロックとブロックを重ねると、ブロックをつなぐことができます。)
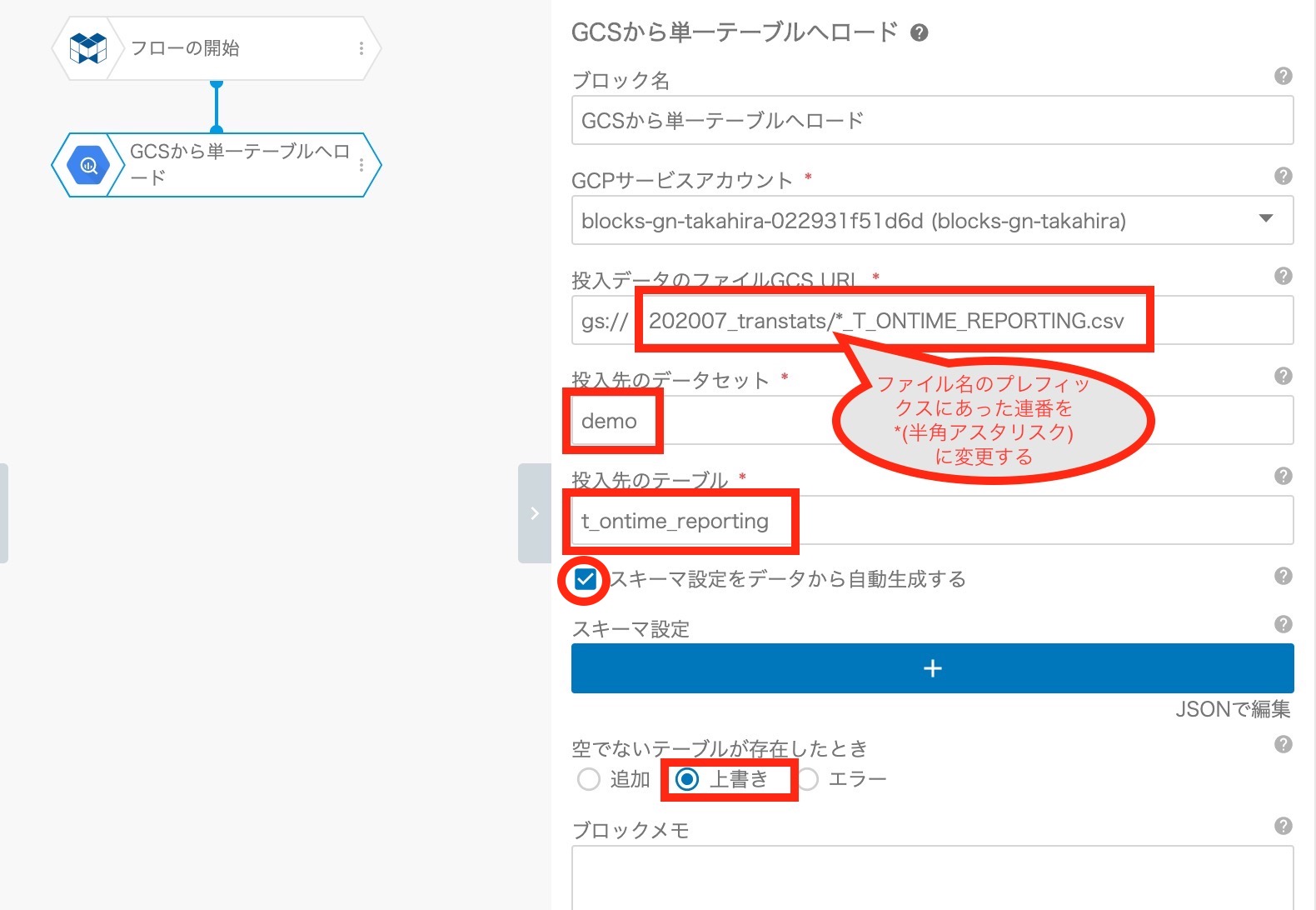
設置した "GCS から単一テーブルへロード" のブロックをダブルクリックして、右側に表示された設定画面の項目に以下を入力します。
-
- 「投入データのファイルGCS URL」項目に、上記 3. の工程の最後にコピーした "GCS URL" を貼り付け、ファイル名のプレフィックスにあった連番を*(半角アスタリスク)に変更する。
例) 515939490_T_ONTIME_REPORTING.csv
→ *_T_ONTIME_REPORTING.csv
※このように指定することで、同一の命名規則で作成された複数ファイルの一括取り込みが可能となります。
- 投入先のデータセット、テーブル名を入力する
- "スキーマ 設定をデータから自動生成する" をチェックする
- "空でないテーブルが存在したとき" のオプションで "上書き" を指定する
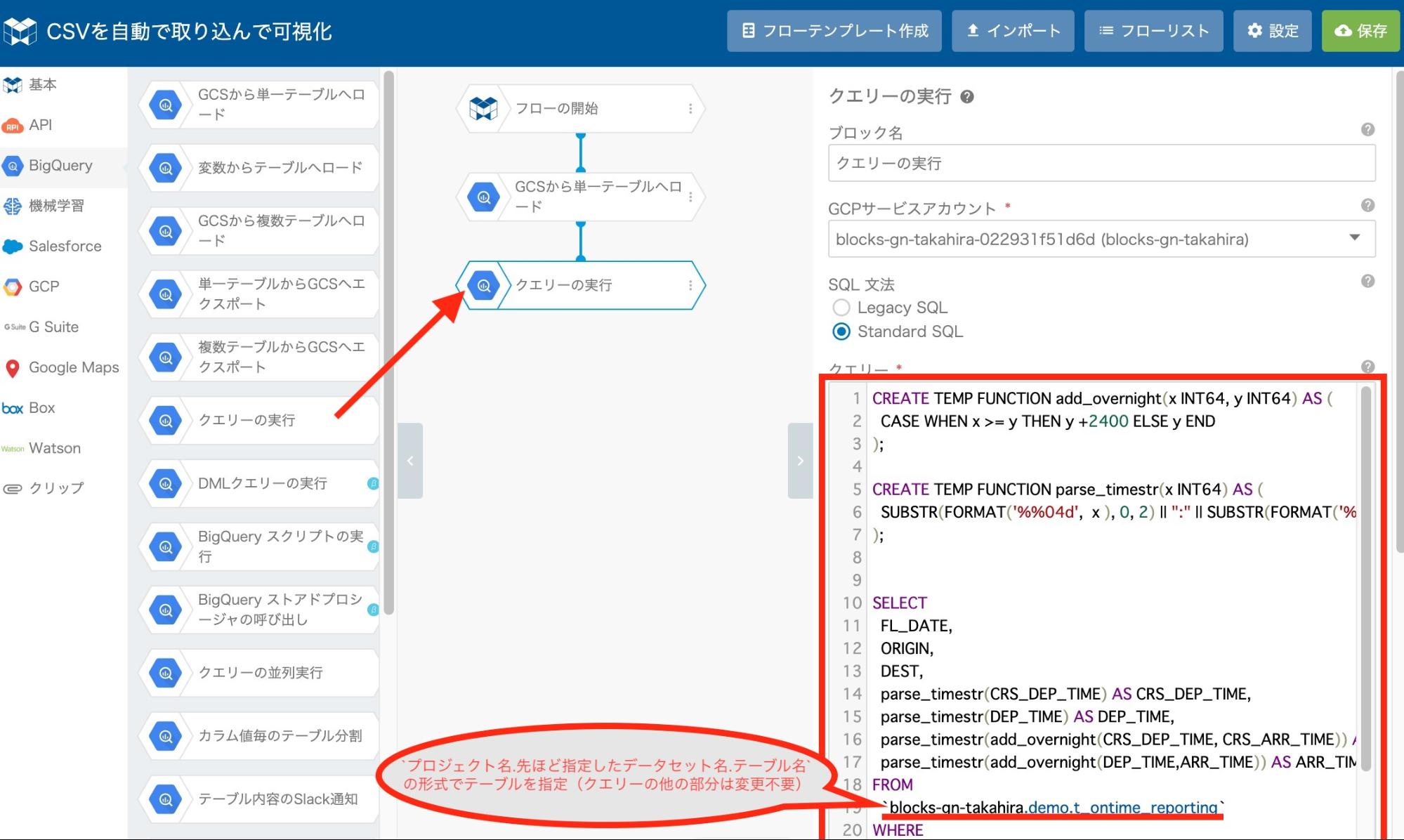
先ほどと同じ要領で、"クエリーの実行" ブロックを配置します。
"クエリー" に以下のクエリを貼り付けます。
CREATE TEMP FUNCTION add_overnight(x INT64, y INT64) AS (
CASE WHEN x >= y THEN y +2400 ELSE y END
);
CREATE TEMP FUNCTION parse_timestr(x INT64) AS (
SUBSTR(FORMAT('%%04d', x ), 0, 2) || ":" || SUBSTR(FORMAT('%%04d', x ),3, 2)
);
SELECT
FL_DATE,
ORIGIN,
DEST,
parse_timestr(CRS_DEP_TIME) AS CRS_DEP_TIME,
parse_timestr(DEP_TIME) AS DEP_TIME,
parse_timestr(add_overnight(CRS_DEP_TIME, CRS_ARR_TIME)) AS CRS_ARR_TIME,
parse_timestr(add_overnight(DEP_TIME,ARR_TIME)) AS ARR_TIME
FROM
`blocks-gn-takahira.demo.t_ontime_reporting` -- ご自身の環境に合わせて入力※
WHERE
ORIGIN = 'HNL'
AND DEST IN ('LAS','SFO','OAK')
ORDER BY
FL_DATE,
CRS_DEP_TIME,
CRS_ARR_TIME
※FROM句の入力方法 `①プロジェクトID.②データセット名.③テーブル名`
①プロジェクトID:手順 1. で確認したプロジェクトID
②データセット名: "GCSから単一テーブルへロード" ブロックで指定したデータセット名
③テーブル名: "GCSから単一テーブルへロード" ブロックで指定したテーブル名
今回クエリの構文説明については割愛させていただきますが、詳しく知りたい方はBigQueryのクエリリファレンスを参照してください。
クエリの処理内容としては、出発空港が'HNL'、到着空港が'LAS','SFO','OAK'の便に絞り混んで、出発時刻と予定時刻のそれぞれ予定と実績を抽出しています。
UDFでは、
日跨ぎの到着時刻を整形しています。例えば翌朝5時の到着を 29:00 という文字列で表現することにより、この後の手順にてスプレッドシートで可視化する際に日跨ぎであることを解釈できるようにしています。
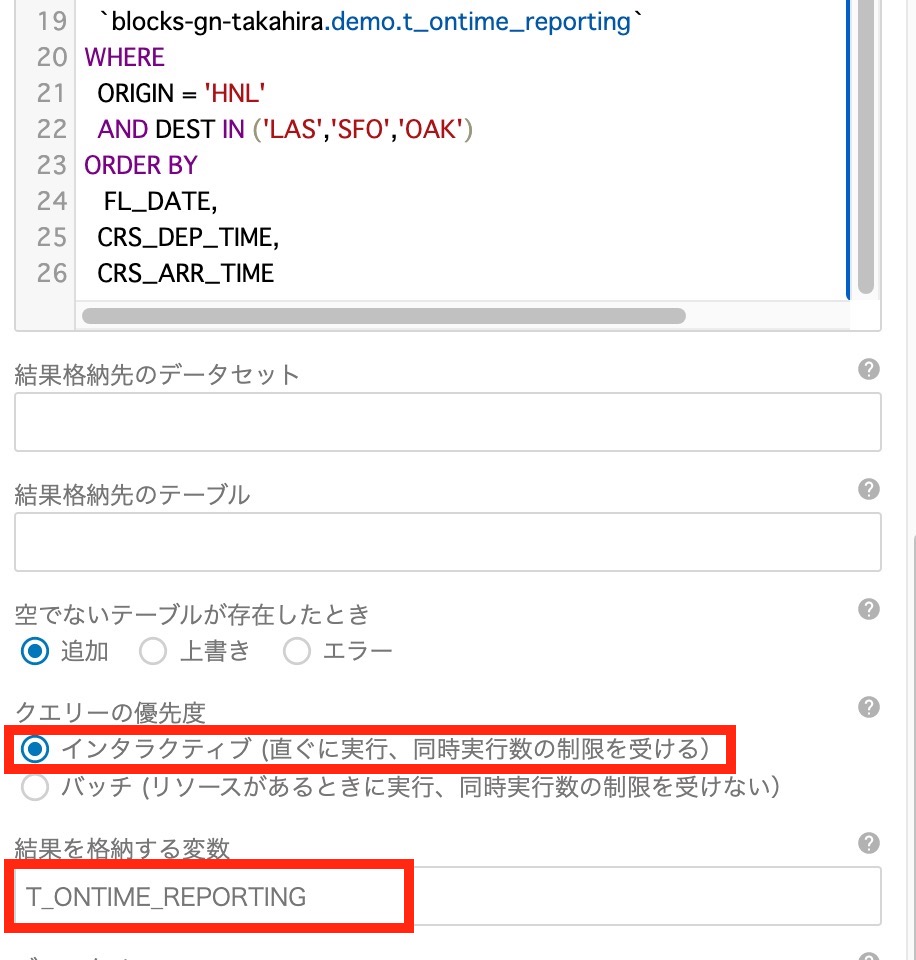
右側の設定メニューをスクロールして、"クエリの優先度" を "インタラクティブ" に設定し、 "設定を格納する変数" に任意の変数名を設定します。
つづいて、左メニューの "G Suite" をクリックし、 "スプレッドシートを更新" ブロックを追加します。
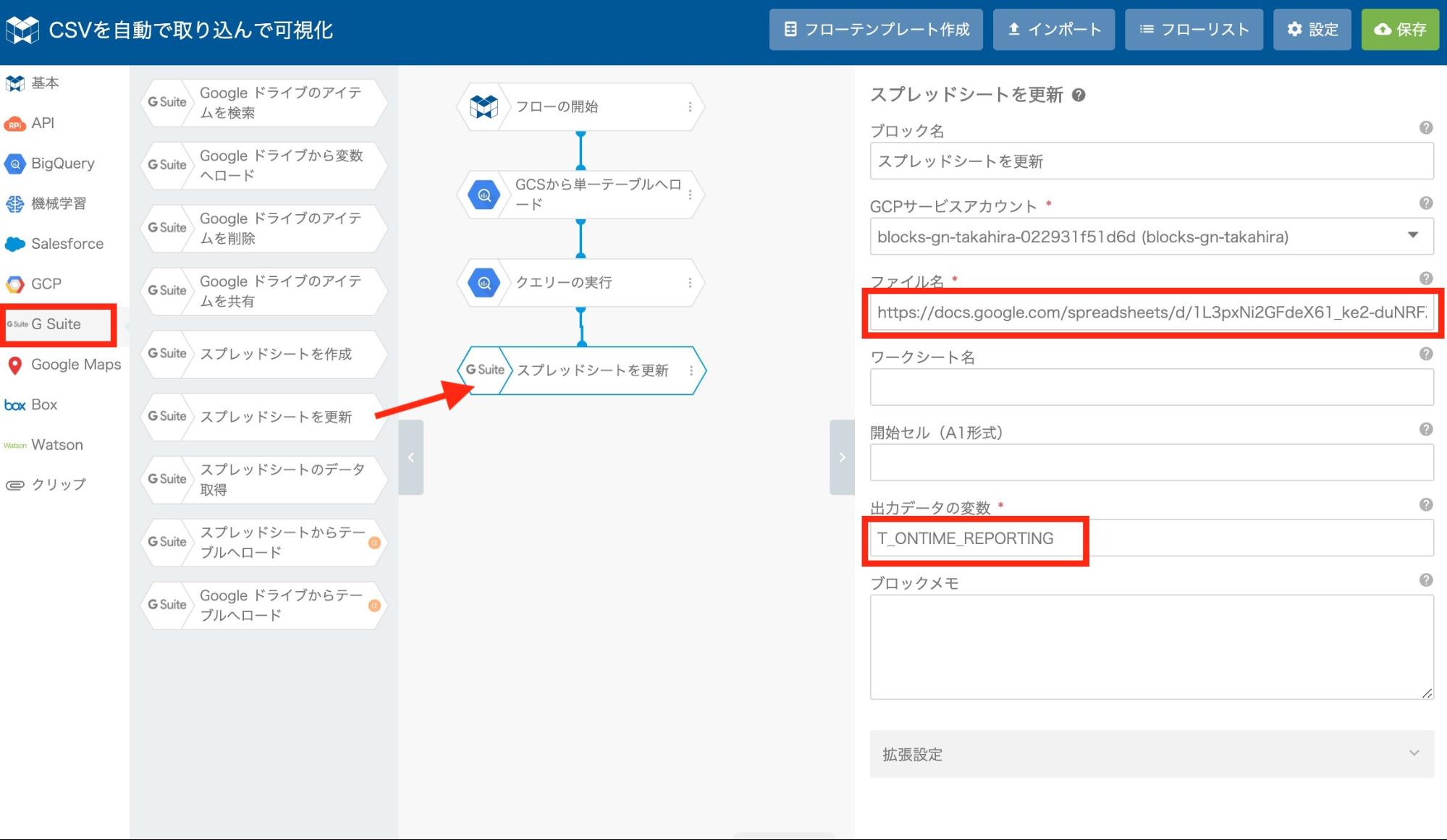
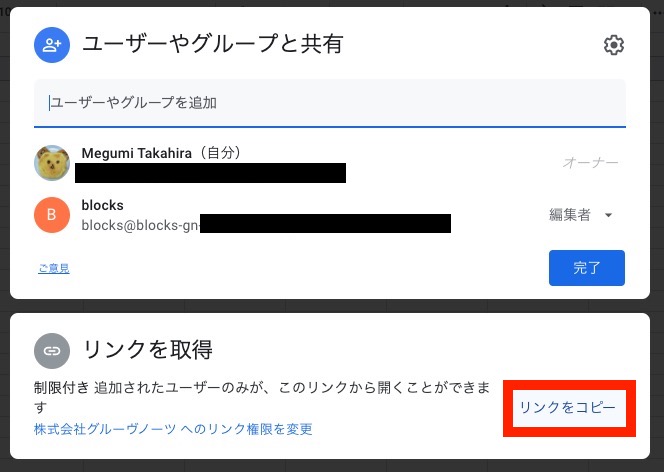
ファイル名の部分は、手順1.で作成したスプレッドシート右上の "共有" ボタンをクリックして表示されるダイアログにて、 "リンクをコピー" をクリックしコピーした内容をペーストしてください。
"出力データの変数" には、先ほど指定した変数名を入力します。
最後に、左メニューの "基本" をクリックし、 "フローの終了" ブロック追加します。
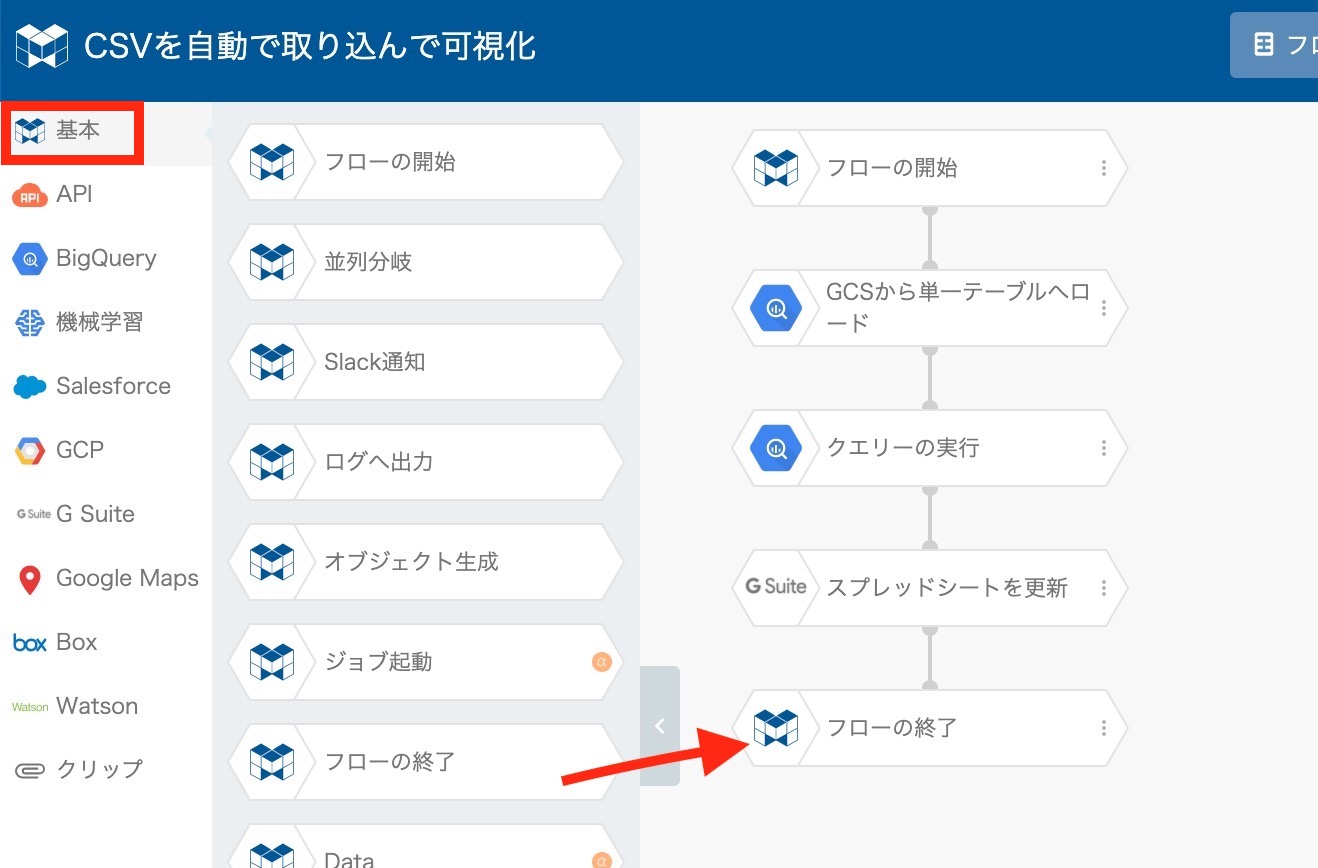
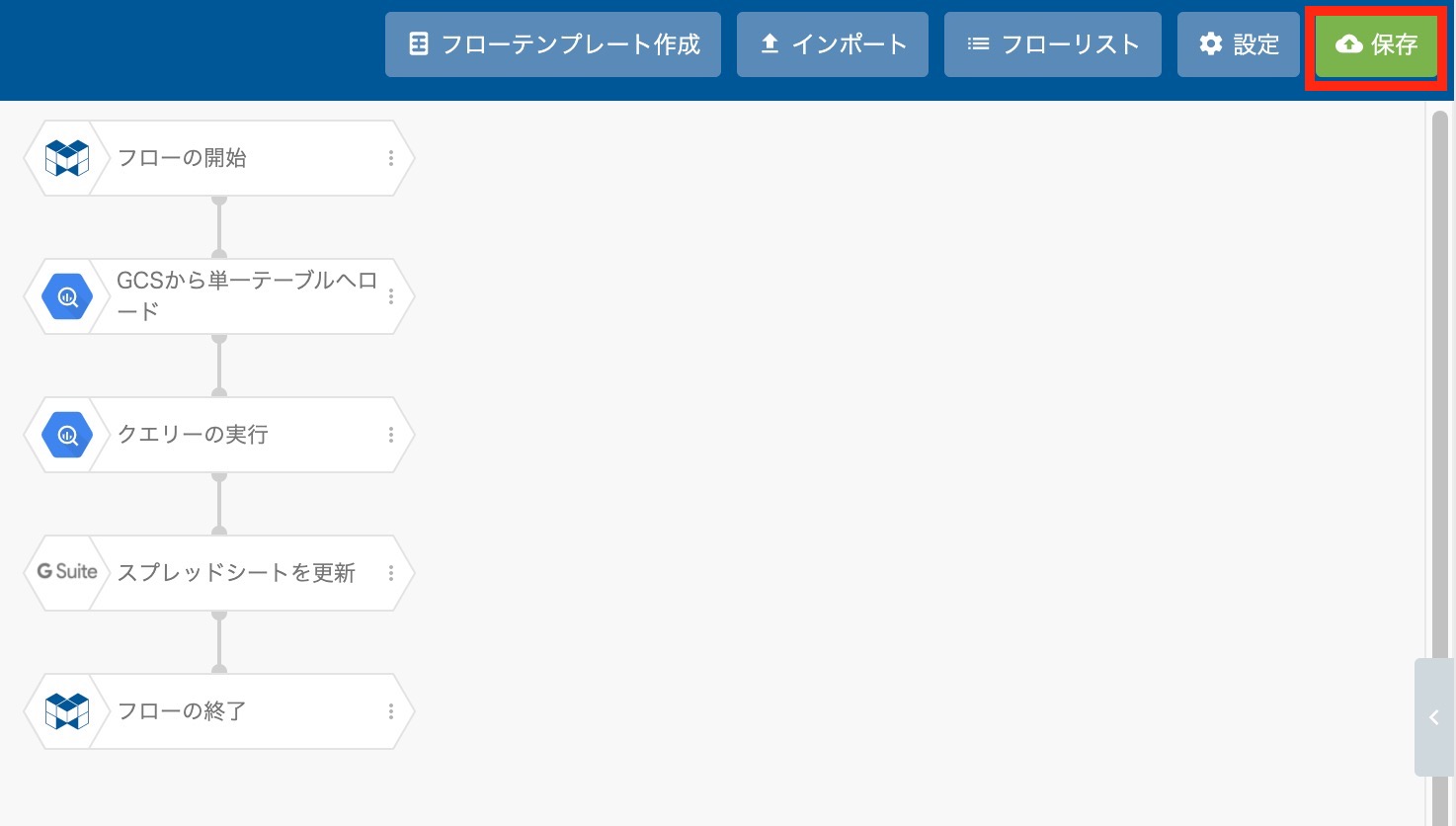
右上の "保存" ボタンをクリックして、保存します。これにてフローが完成しました!
4.フローを実行してみる
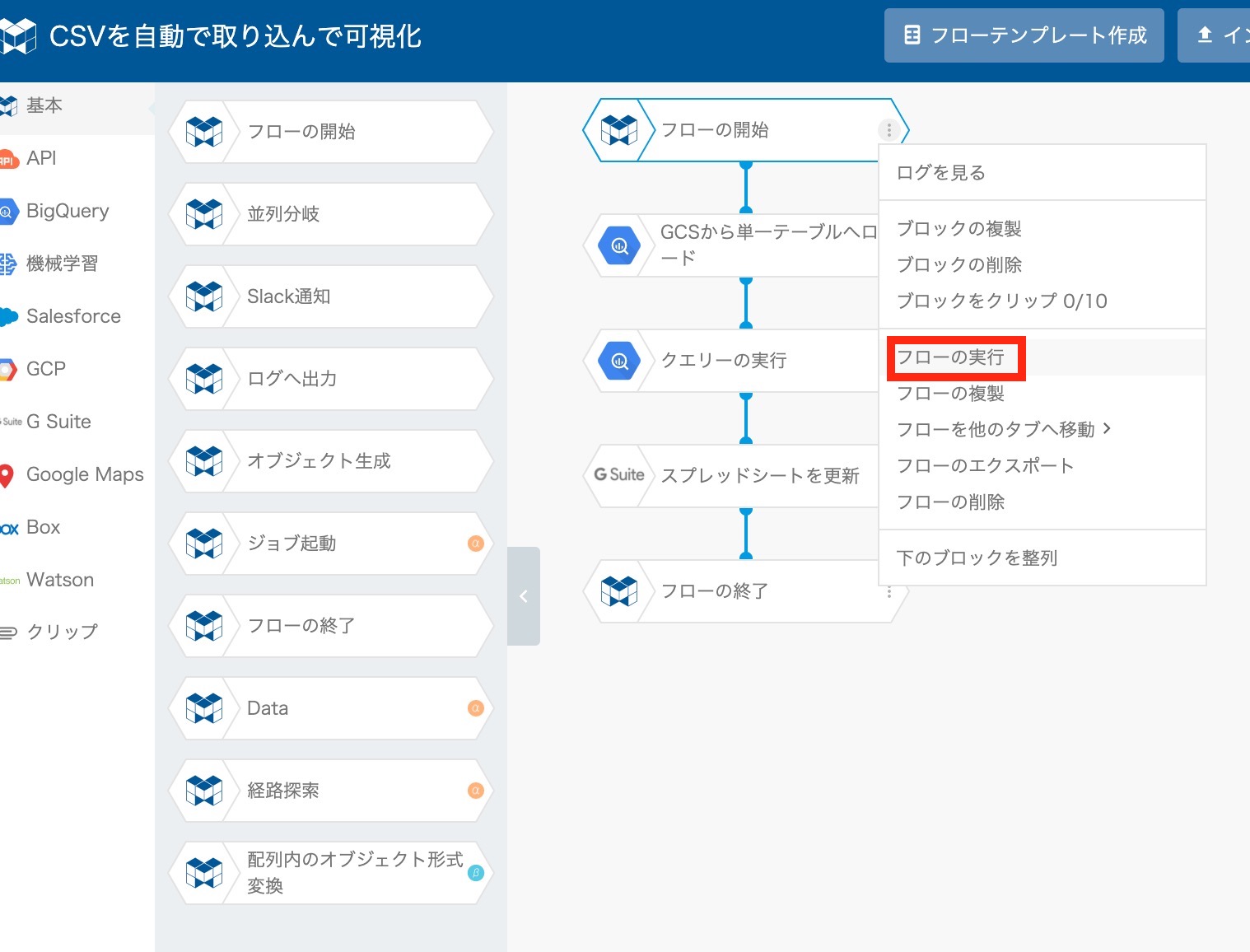
では、出来上がったフローを実行してみましょう。
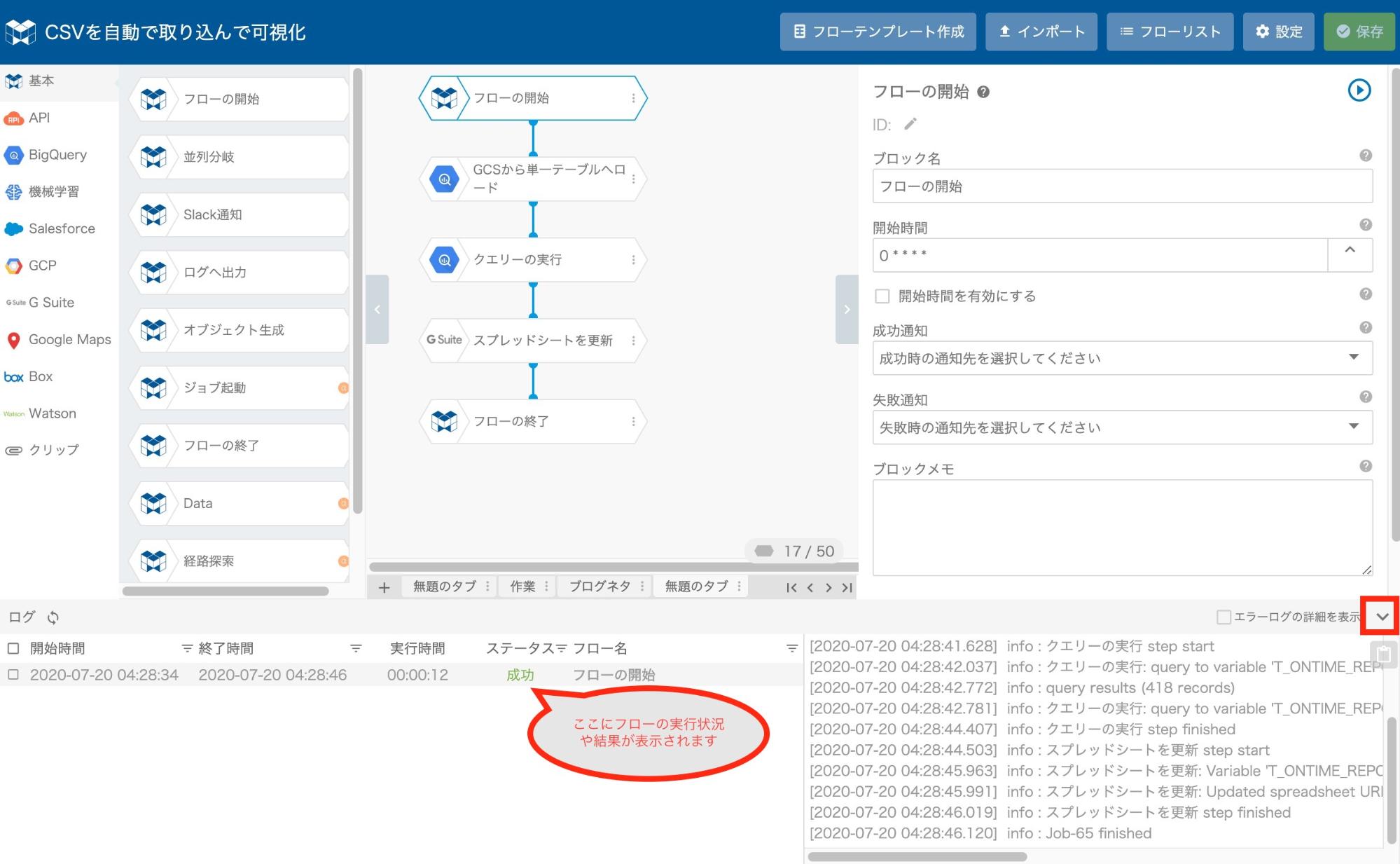
"フローの開始" ブロックの右端にある縦の3点リーダー "︙" をクリックし、表示されたメニューから "フローの実行" をクリック。
MAGELLAN BLOCKSの画面右下ほどにある "^" をクリックして、実行状況を確認します。ステータスで 『成功』 と出れば取り込みとスプレッドシートへの出力が完了しています。
5.スプレッドシートでガントチャート的な可視化をする
フローの成功を確認できたら、出力先のスプレッドシートを開いてみましょう。
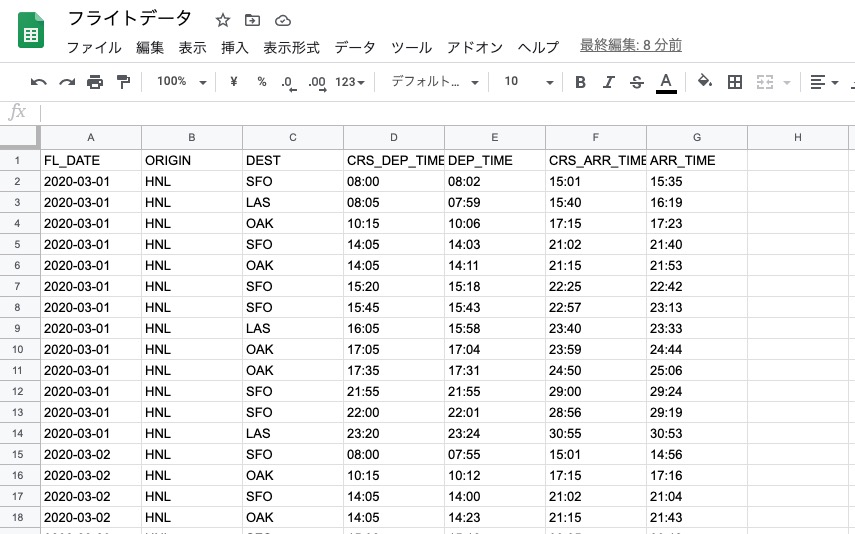
CSVのデータ内容を整形した状態で出力されていることが確認できました。
文字列だけでは、フライトの状況が見えにくいので、簡単なガントチャートのようなものを、関数と条件付き書式で追加していきます。
まず、デフォルトの列数だと足りないので、列を追加します。画面左上のfxマーク下あたりの四角い部分をクリックします。
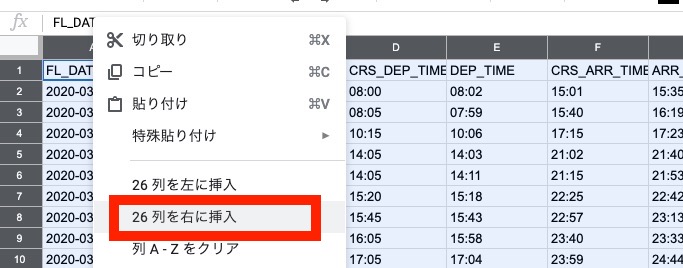
次に、列名の領域を右クリックします。

"26列を右に挿入" を選択します。
これだけだと足りないので、同じ要領でさらに52列追加します。
充分な列数が確保できました。
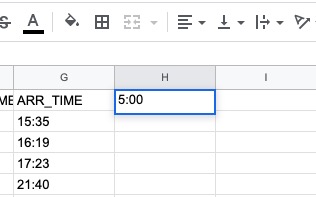
続いて、H1 セルに 開始時刻として "5:00" を入力します。
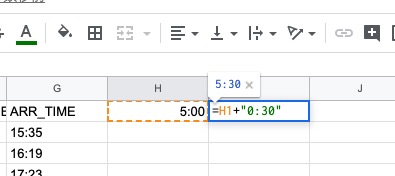
次に、I1セルに"=H1+"0:30""と入力します。
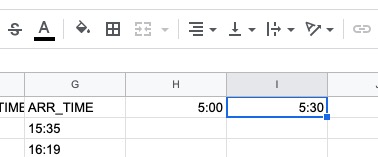
関数の計算結果として、5:00 に30分加算した5:30が表示されます。これを横にコピーしていくことにより、30分単位のチャートを作成します。
I1セルの関数をBH1セルまで横にコピーして、列幅を整えます。

H2セルをクリックして、 "条件付き書式" を選択します。
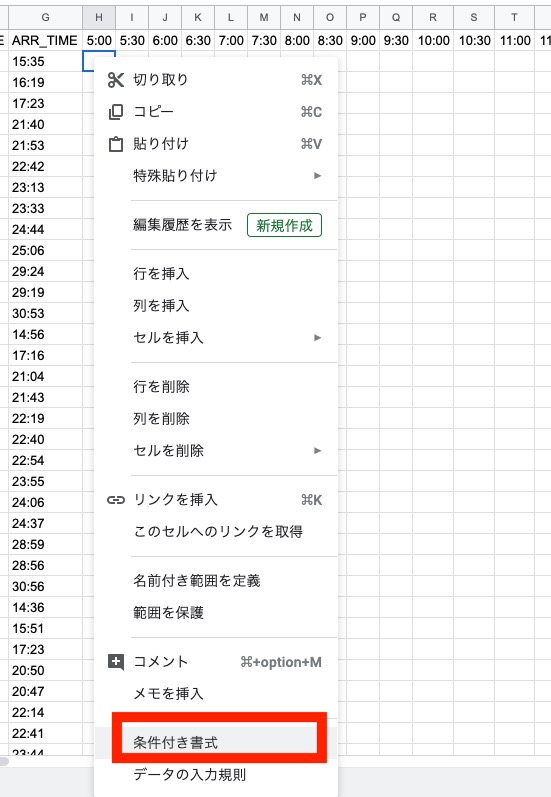
条件1として以下を入力し、 "条件を追加" をクリックします。
- 範囲に適用 → H2:BH
- セルの書式設定の条件(プルダウン) → カスタム数式を選択
- 数式入力欄 → =AND(H$1>=VALUE($E2),H$1<VALUE($G2))
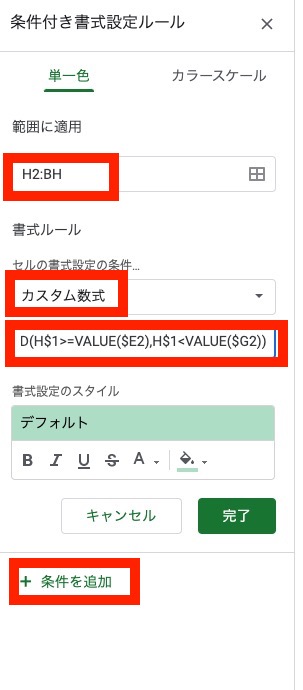
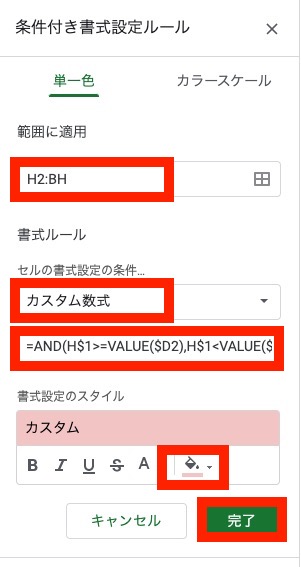
条件2として以下を入力し、"完了" をクリックします。
- 範囲に適用 → H2:BH
- セルの書式設定の条件(プルダウン) → カスタム数式を選択
- 数式入力欄 → =AND(H$1>=VALUE($D2),H$1<VALUE($F2))
- 書式設定のスタイル → 条件1と異なる目立つ背景色を指定
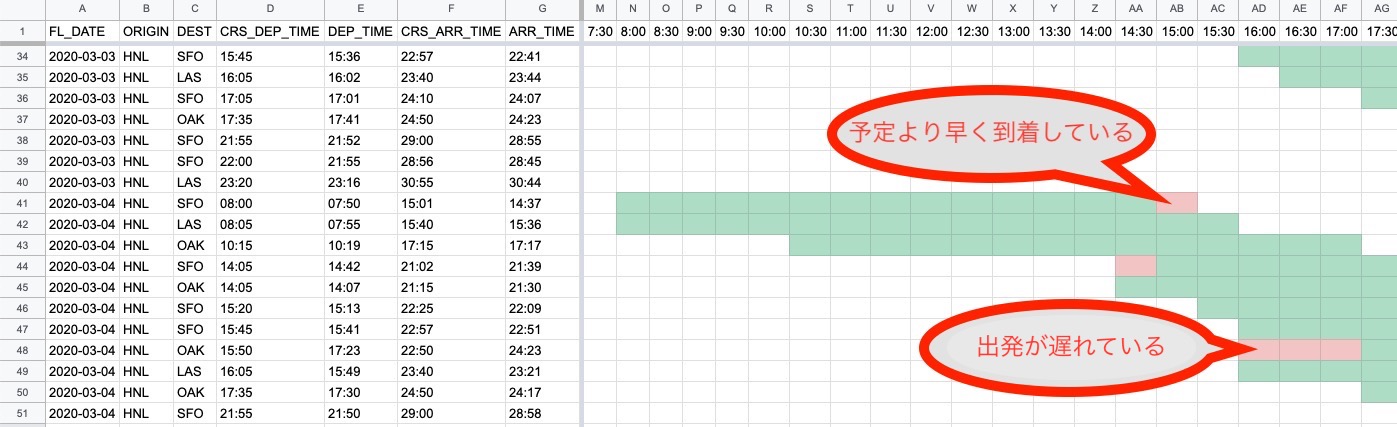
チャートが表示できました。条件1では実績の飛行時間を、条件2では予定の飛行時間を表示しています。
条件付き書式は先に設定した条件が優先されるので、予定と実績がぴったり一致している場合には、実績を表す緑の線だけが表示されます。予定と実績にズレがある場合には、条件2の線が出現して、予定との相違がどのくらいあるかを表現します。
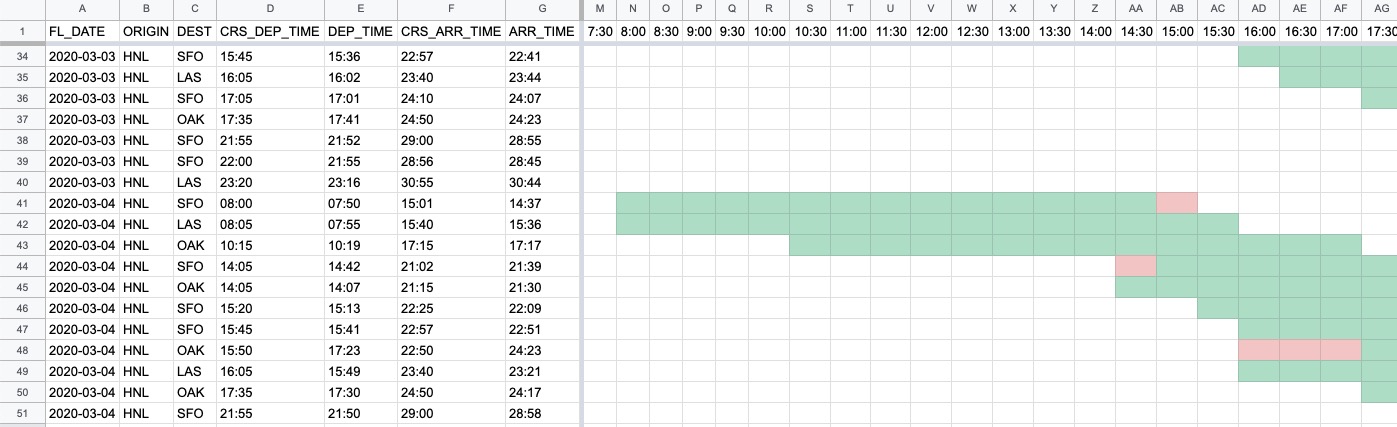
表示されたチャートをみていくと、例えば3/4 8:00 発の HNL-SFO便は、予定より30分程(1セル分)早く到着していることがわかります。
また、3/4 15:50 発予定のHNL-OAK便は、予定より1時間30分程(3セル分)出発が遅れたことがわかります。
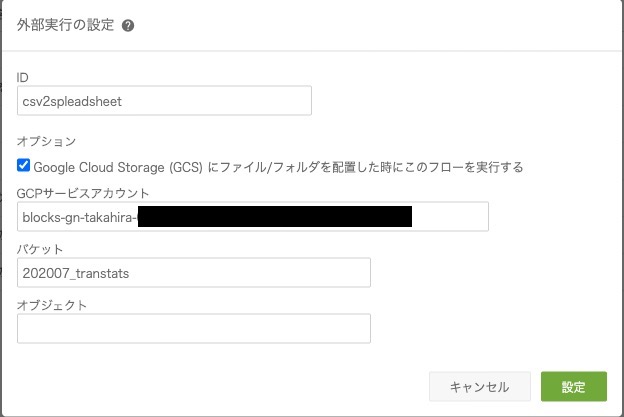
6.外部実行でGCSトリガーを設定する
最後に、フローデザイナーの新機能である外部実行のGCSトリガーを使って、CSVをGCSに配置した際に自動でスプレッドシートに反映されるようにします。
GCSトリガーの詳しい使用方法は、「GCS トリガーで BigQuery へデータを自動取り込みするフローを作る」のブログで紹介していますので、ぜひご参照ください。
CSVを格納しているバケットを指定して、GCSトリガーを設定します。
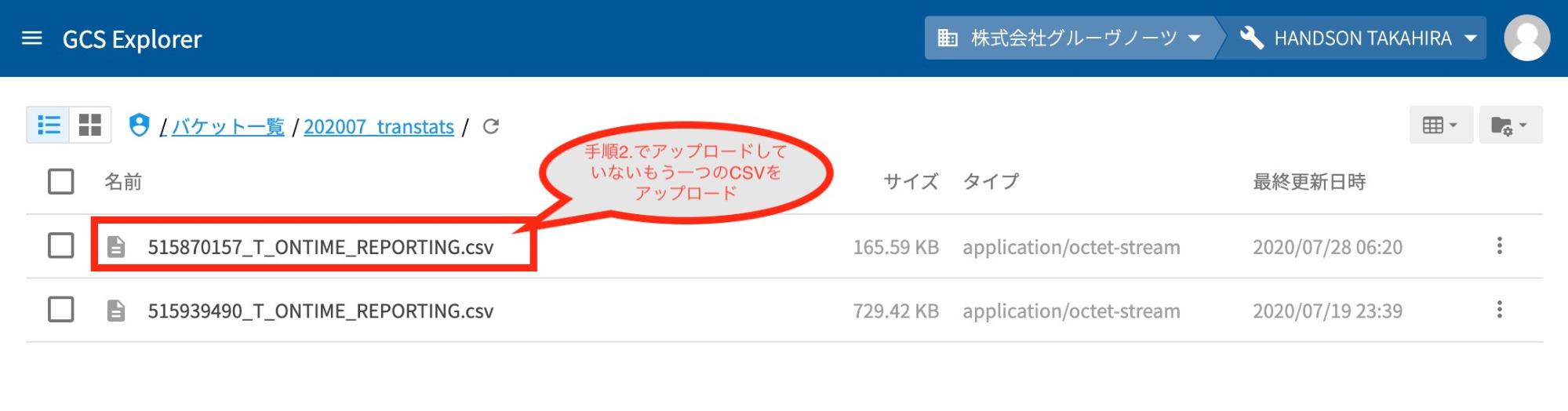
手順2. でアップロードしていないもう一つのCSVをアップロードします。
新規アップロードしたデータが追加されました。
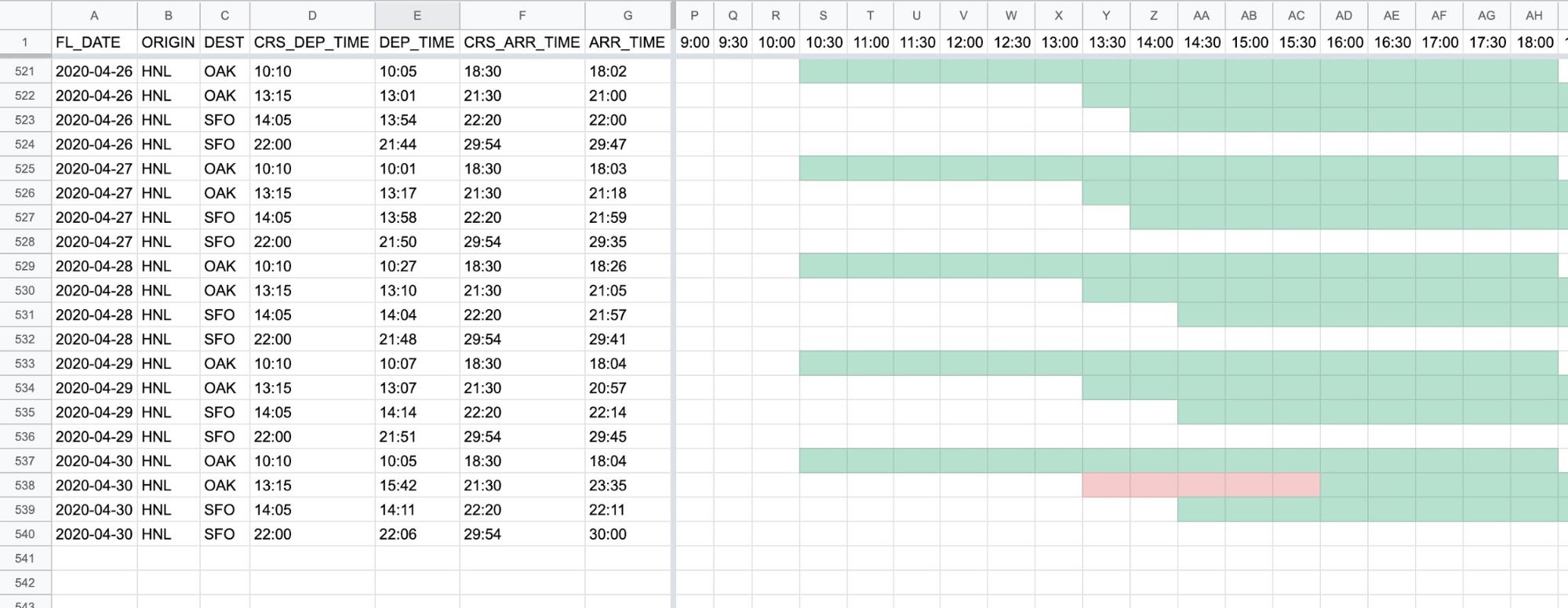
余談ですが、今回使用したホノルル発のフライト数を2020年3月と4月で比較すると、3月のフライト数に対して4月のフライト数が約1/4に減少していますね。新型コロナウイルス感染拡大の影響かと思いますが、一日も早く収束して楽しくハワイ旅行をできる日がくることを祈っています。
いかがでしたでしょうか? MAGELLAN BLOCKSとスプレッドシートを連携させることで、属人化しがちなスプレッドシートの更新を自動化でき、多くの方が見慣れた表計算ソフトの形で時系列データを可視化することができました。
MAGELLAN BLOCKSの活用範囲は、高度な分析やデータ処理はもちろんなのですが、このように身近な日常業務の自動化にも活用することができます。ぜひみなさんの業務軽減にもお役立ていただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。