以前、コーヒー豆の良・不良をMAGELLAN BLOCKSのモデルジェネレーターで画像分類タイプを利用して判別する方法を紹介しました。
今日は画像分類で利用できる様々な予測方法を紹介したいと思います。
画像分類の予測方法には運用に合わせて色々な予測方法が選ぶことができます。
その予測方法の選び方のポイントはこの3つです。
- どういうシチュエーションで使うか
- どこにある画像を予測するか
- 予測結果をどこに出力するか
上記のポイントを踏まえて紹介していきたいと思います。
目次
とりあえず1枚の画像を予測してみる(動作確認)
最初にみなさんが試されるのが「どんな予測結果がでるのかな?」という動かしてみるということでしょう。
その場合はまずGCSに保存してある1枚の画像を予測することをお勧めします。
また予測結果はログに表示するとシンプルに確認できるので良いでしょう。
入力:GCSに保存した1枚の画像ファイル
出力:フローデザイナーのログへ出力
予測方法:オンライン予測
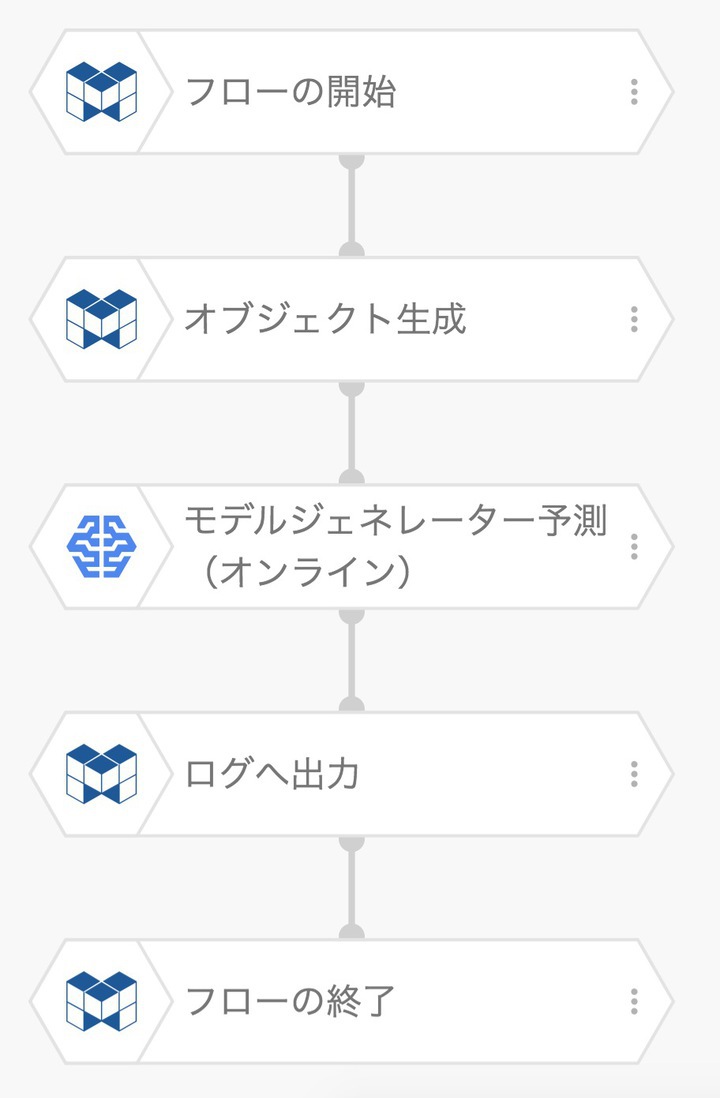
この場合のフローは3つのブロックを使ったフローを準備します。(開始・終了を除く)
二つ目のブロックであるオブジェクト生成で 画像ファイルの場所 を指定します。その指定方法にはモデルジェネレーターのルールに合わせる必要があります。
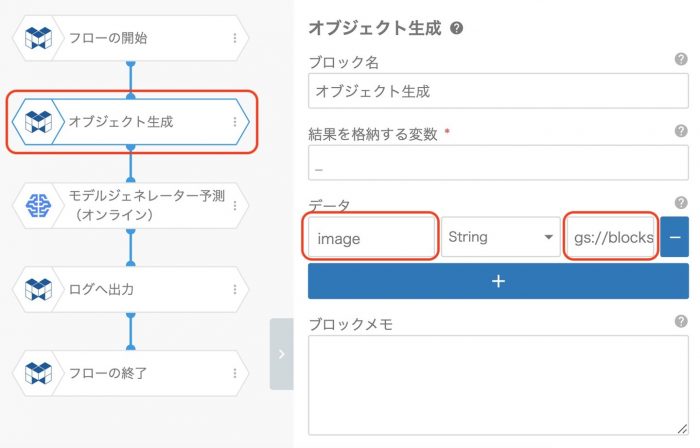
image というキーに gs://ファイルの場所 という指定方法になります。今回のフロー例でいうと下記の設定内容となります。
gs://blocks-gn-ysmr-us-central1-data/coffee_beans/yosoku/ng_1-2.jpg
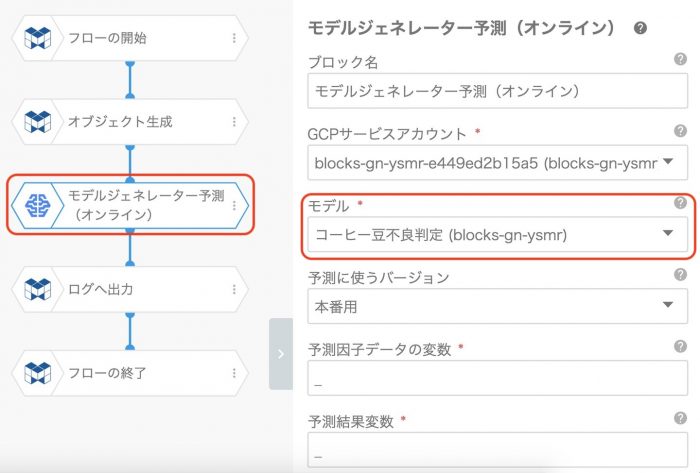
続いてモデルジェネレーター予測(オンライン)のモデルには対象となるモデルを選択しておきます。

このフローを実行すると、対象となる画像の予測結果がログに出力されます。
ログに表示されている情報について詳しく説明します。
- key
keyとは、どの画像ファイルを予測したかを示すGCS URLが表示されます。これはGCSにあるファイルを予測した場合のみで、予測方法によって表示が変わります。
- labels
labelsは、画像分類タイプのモデルジェネレーターに学習させている分類の種類が表示されます。今回はコーヒー豆の ng,ok のフォルダを学習させているので2つが列挙されています。 ※なおフォルダの名前順に表示されます。
- scores
scoresは、上記labelsの順にこの画像の各分類に対する確からしさのスコアが表示されます。この数値は合計すると約1になる数字で、とても少ない数字の場合は1.234e-17など指数表示になる場合があるのでご注意ください。
- label
上記scoresで最も大きい値を示すラベルが表示されます。最終的に何に分類されかと言う意味です。
このように1枚とりあえず予測してみる場合にはこのような方法で行います。
また今回はログに出力していますが、GCPカテゴリに入っている 変数からGCSへアップロード ブロックを利用するとJSONファイルとして出力することも可能です。
複数枚の画像をまとめて予測をする
とりあえず予測してみたら、次は正しく予測しているかの検証に入られると思います。
その際はもちろん1枚ずつやっていてはらちがあかないので、まとめて予測する方法が必要になります。
まとめて予測する場合は、その結果を表形式で確認する場合が多いと思います。
そのため、出力はCSVやGoogleスプレッドシートを利用する場合が主となります。
入力:GCSに保存した複数の画像ファイル
出力:GCSにCSVファイルとして出力
予測方法:バッチ予測
これを満たすフローを作成するには、フローテンプレートの機能を利用すると非常に便利です。
上記の入力・出力・予測方法と予測モデルを指定するだけで、簡単にフローを作成できます。
まずは フローテンプレート作成 のボタンをクリックします。

まずはどのタイプの予測かを選択します。
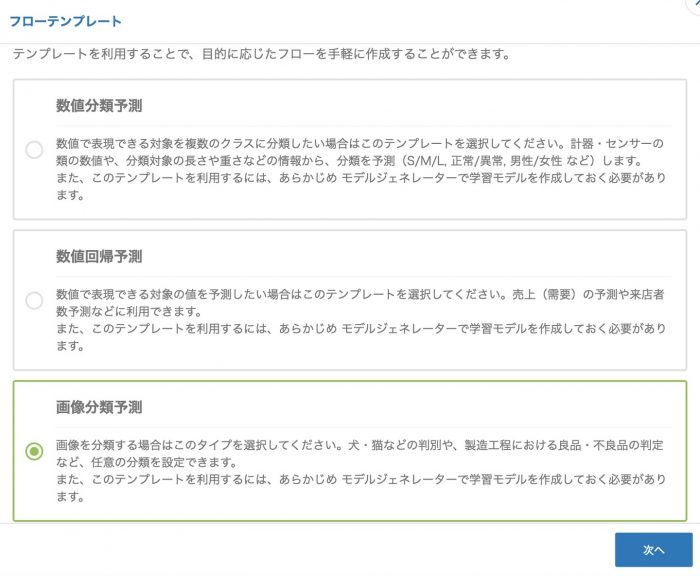
今回はもちろん 画像分類予測 を選択します。
ここから指示に従い入力していくと、フローができあがります。
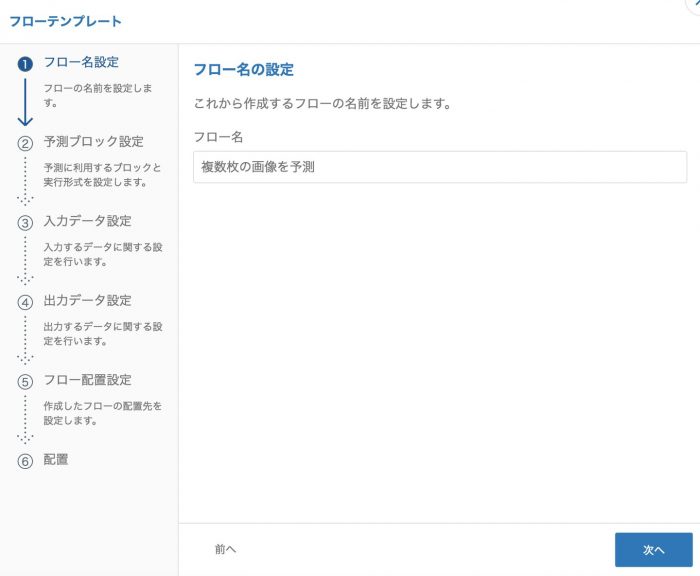
フロー名の設定はここで入力した内容がフローの開始ブロックの表示名となります。
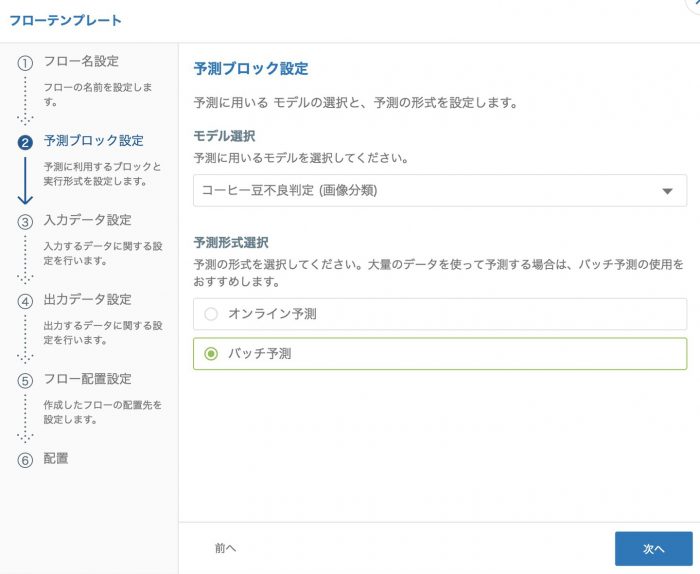
モデルの選択ではトレーニング済みの画像分類タイプのモデルを選択します。
予測形式の選択では バッチ予測 を選択します。バッチ予測はかならず、前後のオーバーヘッドにより10分前後はかかります。
※もし複数枚の画像をある程度短時間で予測する必要があるときは、他の方法を複数回実行するなど検討が必要です。
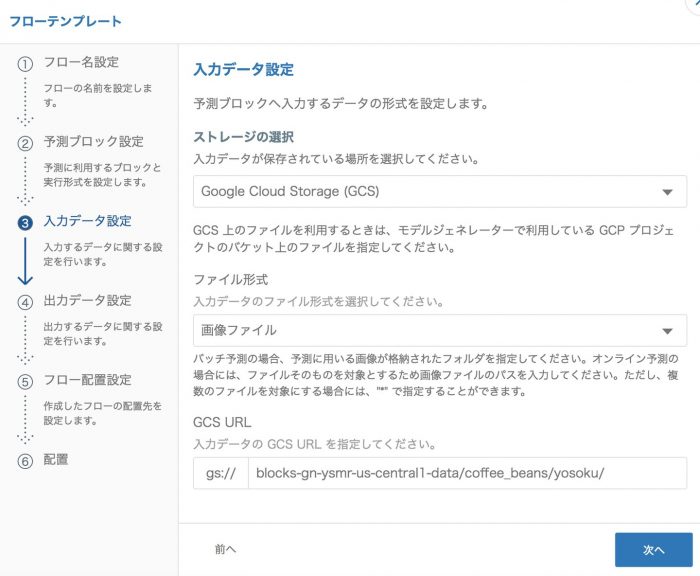
入力データ設定では、GCS上に置いてあるJPEGファイルの場所を設定します。
※必ず gs://画像ファイルが保存されているフォルダ/ とします。
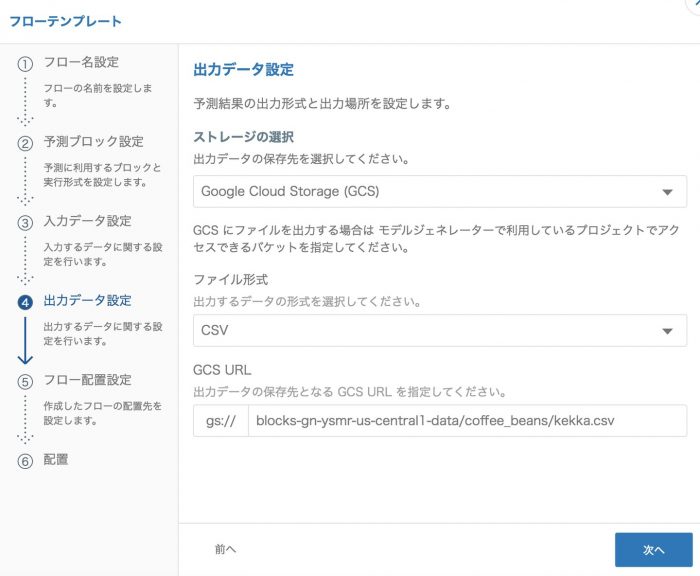
出力データ設定も同様に、GCS上に出力するCSVのファイルの場所を設定します。
フロー配置設定では、フローデザイナーにて複数のタブを利用している場合にタブを選択できます。
あまり気にせず配置ボタンをクリックしてしまいましょう。
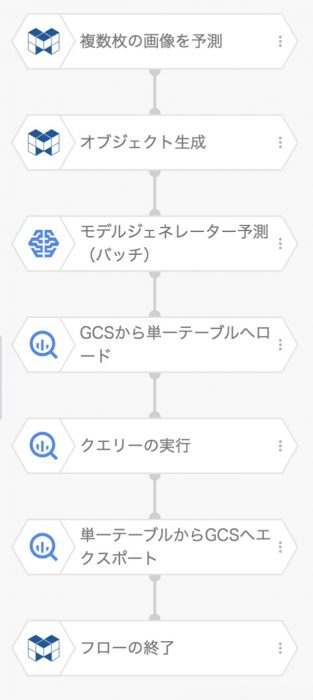
すると指示に従い設定を行うだけで、このようなフローができあがりました。
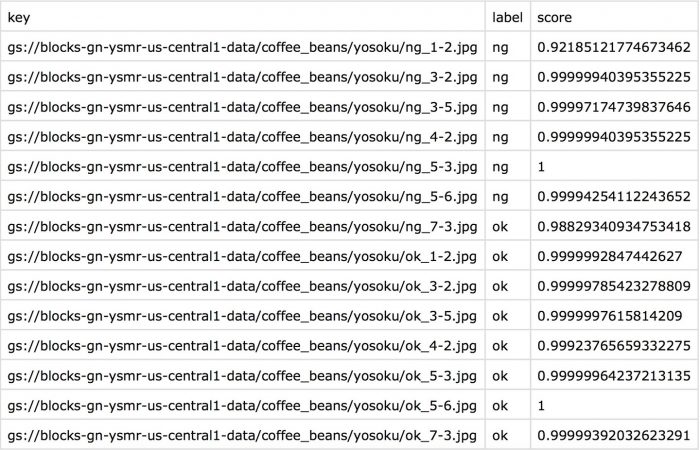
このフローの処理結果として出力されたCSVファイルを開くと、このようになっています。
出力内容を確認するとkey,labelについては先ほどと同じ意味合いですが、scoreだけ違います。
scoresとして出力されていた値の中で一番大きい値が出力されるのでご注意ください。
利用シチュエーションとして検証に使うと説明しましたが、監視カメラで1日撮りためた画像を夜間にまとめて判断するような運用でも利用可能です。
ローカルで撮影した画像を送信しながら予測する
インターネットに繋がる環境で数秒のレスポンスタイムで許容されるシチュエーションで利用される方法です。
例えばスマホアプリを開発して、撮影した画像をMAGELLAN BLOCKSに送って状態を判断するなどです。
さすがに「スマホアプリを開発して」と書いてあるとおり、このあたりからはプログラミングも絡んできます。
ただスマホアプリ開発者であれば朝飯前なREST APIを呼び出すだけで、フローも非常に簡単です。
入力:送信された画像ファイル
出力:フローデザイナー上の変数
予測方法:オンライン予測予測
一気にフローが簡単になりましたね。
はい モデルジェネレーター予測(オンライン) だけです。
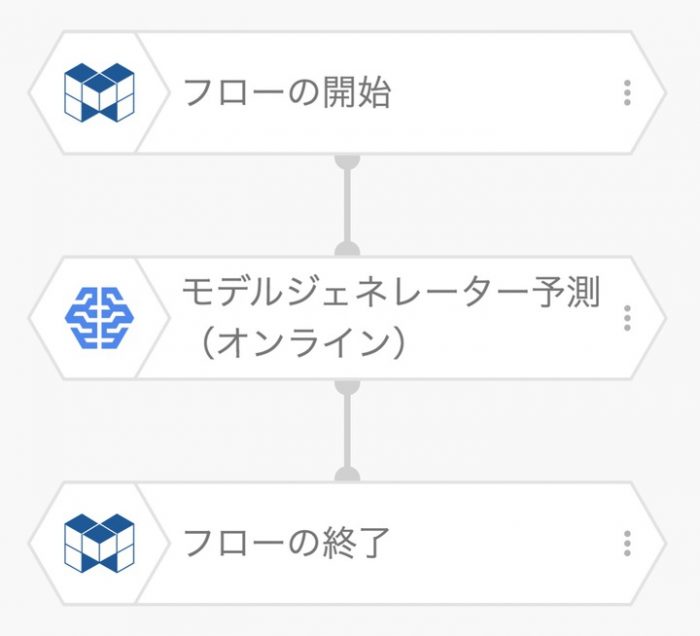
このフローを実行するには 外部実行 と言うMAGELLAN BLOCKSに準備されたAPIを利用します。
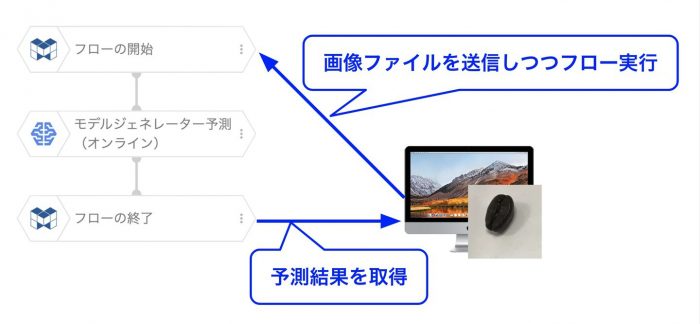
図のイメージで画像が送信されてフローにて予測処理が行われた後に予測結果を取得します。
ビジネスサイドの方は「こういうことができるんだ」と理解し、社内のエンジニアや協力会社に依頼する部分だとご理解ください。
具体的な実装方法については フローの外部実行 をご確認ください。
また筆者がよく使うサンプルコードを掲載しておきます。
[js]#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ------------------------------------------------------------------------------
# フローデザイナーのモデルジェネレーター予測(オンライン)ブロックで画像分類タイプをしている
# フローをAPIから起動して終了確認して結果の変数値を取得する
#
# フローデザイナーから下記3点を確認し設定する
# フローデザイナーのサービス設定で取得したAPIトークン
# フローデザイナーのURLの固有部分
# 実行するフローに設定したID
# JPEGファイルパス
#
# 実行サンプル
# python ./img_prd.py <blocks_designer> <blocks_token> <blocks_flow> '/dir/img.jpg'
# ※JSON文字列は "_" を最初に定義しておくと、そのままフローで "_"で利用できる。
#
# ------------------------------------------------------------------------------
import sys
import time
import base64
import urllib.request, json
from distutils.util import strtobool
if __name__ == '__main__':
# 引数取得
args = sys.argv
# 引数チェック
if len(args) != 5:
# Usage出力
print("Please call with collect arguments.")
print(" python ./img_prd.py <blocks_designer> <blocks_token> <blocks_flow> '/dir/img.jpg'")
quit()
# BLOCKS実行フロー情報
blocks_designer = args[1]
blocks_token = args[2]
blocks_flow = args[3]
# 画像ファイルパス
image_file = args[4]
print("--------------------------------------------------------------------------------")
print("Flow Designer flow Starting")
print("Designer URL : " + blocks_designer)
print("Flow ID : " + blocks_flow)
print("JPEG FILE : " + image_file)
# --------------------------------------------------------------------------
# 画像ファイルをBASE64化してJSON作成
# --------------------------------------------------------------------------
b64 = base64.encodestring(open(image_file, 'rb').read())
blocks_json = {
"_" :
{
"key" : image_file,
"image" : {
"b64" : b64.decode('utf8')
}
}
}
json_data = json.dumps(blocks_json).encode("utf-8")
# --------------------------------------------------------------------------
# BLOCKS フローデザイナーフロー起動
# --------------------------------------------------------------------------
url = "https://" + blocks_designer + ".magellanic-clouds.net/flows/" + blocks_flow + ".json"
method = "POST"
headers = {
"Content-Type" : "application/json" ,
"Authorization" : "Bearer " + blocks_token
}
# httpリクエストを準備してPOST
request = urllib.request.Request(url, data=json_data, method=method, headers=headers)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode("utf-8")
json_obj = json.loads(response_body)
result = json_obj['result']
job_id = json_obj['job_id']
if result == True:
print("flow starting is successed.")
else:
print("flow starting is failed.")
exit()
# --------------------------------------------------------------------------
# BLOCKS フローデザイナー実行ステータス取得
# --------------------------------------------------------------------------
status = ""
while status not in ["finished" ,"failed", "canceled"] :
# 1秒待つ
time.sleep(1)
# リクエスト情報作成
url = "https://" + blocks_designer + ".magellanic-clouds.net/flows/" + blocks_flow + "/jobs/" + str(job_id) + "/status.json"
method = "GET"
# httpリクエストを準備してGET
request = urllib.request.Request(url, method=method, headers=headers)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode("utf-8")
json_obj = json.loads(response_body)
status = json_obj['status']
print("job_id " + str(job_id) + " is " + status)
if status not in ["failed","canceled"]:
print("flow is successed.")
else:
print("flow is failed.")
exit()
# --------------------------------------------------------------------------
# BLOCKS フローデザイナー変数値取得
# --------------------------------------------------------------------------
# リクエスト情報作成
url = "https://" + blocks_designer + ".magellanic-clouds.net/flows/" + blocks_flow + "/jobs/" + str(job_id) + "/variable.json"
method = "GET"
# httpリクエストを準備してGET
request = urllib.request.Request(url, method=method, headers=headers)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode("utf-8")
json_obj = json.loads(response_body)
print(json_obj)
[/js]
インターネットのない環境または予測処理に高いレスポンスが必要なシチュエーション
これはズバリ工場のラインで検品を行う場合や検査機器と連携して判断を行う場合などです。
もちろんコンピュータに組み込む必要があるので、多少プログラミングが必要となります。
これを実現するためにはまずMAGELLAN BLOCKSのご契約をいただいた上で、MAGELLAN BLOCKSダウンロードサービスにお申し込みいただく必要がございます。
お申込みをいただくとトレーニングのメニュー (︙) に モデルをダウンロードする が表示されます
実現するにはPythonとTensorflowが導入された環境があれば可能です。
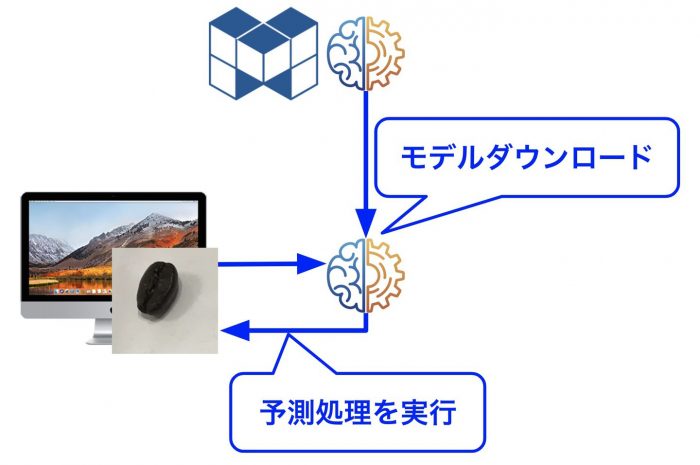
図のようなイメージでダウンロードされたモデルを利用して、ローカル環境で予測処理が可能です。予測処理を動かすにためのサンプルソースを掲載しておきます。
なおMacbook Pro 2016のCPUを利用した場合、予測1枚あたり0.2sec前後でした。また、Google ColaboratoryのGPU環境では0.04sec前後で処理できていたので、工場のラインであっても運用できるレスポンスではないかと思います。
コードを見る[js]
# -*- coding: utf-8 -*-
# ------------------------------------------------------------------------------
# 画像分類の予測をモデルジェネレーターで作成したモデルでローカル環境で予測する
#
# 前提:下記のフォルダ構成に配置する
# /base_dir
# /predict_images.py(本プログラム)
# /blocks_ml_99999
# /saved_model.pb(ダウンロードしたモデル)
#
# 実行イメージ
# python ./predict_image.py <images_dir>
#
# ------------------------------------------------------------------------------
import os
import sys
import time
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
saved_model_dir = "blocks_ml_99999"
if __name__ == '__main__':
# 引数取得
args = sys.argv
if len(args) != 2:
print("argments error!")
print("python ./predict_images.py <images_dir>")
quit()
images_dir = args[1]
ext_list = ["jpg", "jpeg","JPG","JPEG"]
print("="*80)
before_get_files = time.time()
file_list = []
for root, dirs, files in os.walk(images_dir):
for ext in ext_list:
file_list.extend([os.path.join(root, file) for file in files if ext in file])
after_get_files = time.time()
elapsed_get_files = after_get_files - before_get_files
print("get file list time {:.5f} secs".format(elapsed_get_files))
print("="*80)
predictor = tf.contrib.predictor.from_saved_model(saved_model_dir)
after_load_model = time.time()
elapsed_load_model = after_load_model - after_get_files
print("save_model load time {:.5f} secs".format(elapsed_load_model))
print("="*80)
for image_path in file_list:
before_open_image = time.time()
image = open(image_path, "rb").read()
after_open_image = time.time()
result = predictor({"image":[image], "key": [image_path]})
after_predict_image = time.time()
result = result
elapsed_time_open_image = after_open_image - before_open_image
elapsed_predict_image = after_predict_image - after_open_image
file_name = os.path.basename(str(result['key'][0].decode("utf-8")))
predicted_label = result['label'][0].decode("utf-8")
max_score = max(result['score'][0])
msg = "open:{:.5f} secs".format(elapsed_time_open_image) + "/"
msg += "predict:{:.5f} secs".format(elapsed_predict_image) + " => "
msg += "key:" + file_name + ","
msg += "label:" + predicted_label + ","
msg += "score:" + "{:.5f}".format(max_score)
print(msg)
[/js]
最後に
このようにシチュエーションごとに利用すべき予測方法が変わってきますので、検証のためと実際の運用で最適な方法を選択していただければと思います。
「こういうシチュエーションではどういう運用がいいだろうか」と疑問に思われた場合には、お気軽にグルーヴノーツのコンサルタントへご相談いただければ対応させていただきます。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。