社内からの要望もとても多かった機能である クラスタリング がついにリリースされました。
MAGELLAN BLOCKSのDataEditorで実現したのでもちろん非常に簡単です。
さっそく使い方をご案内していきます。
1.モデル作成
クラスタリングモデルの作り方はDataEditorでクリックしていくだけ。今回は前にマーケティング向けモデルに使った、銀行のデータを利用します。
今回データは2つ準備していて、モデル作成用のデータと予測用のデータがあります。まずモデル作成用のテーブルを開きます。
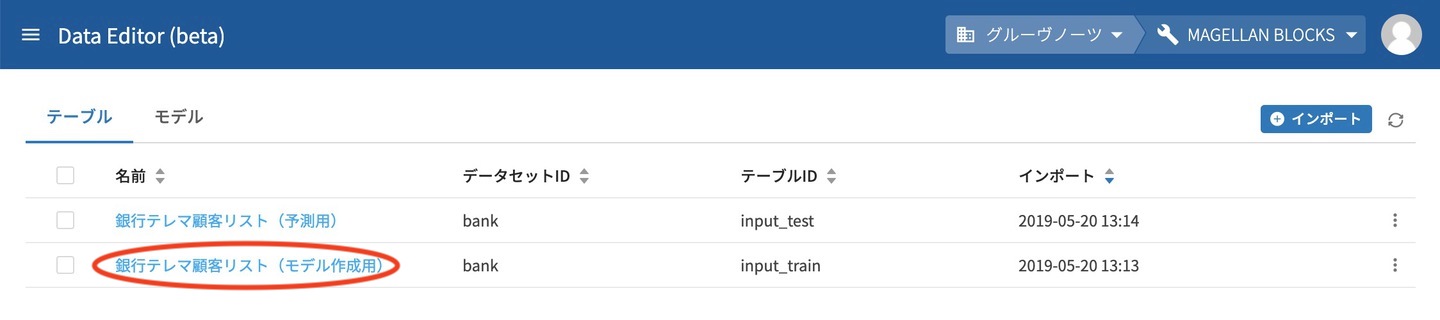
テーブルを開いたら右上側にある テーブルの操作 をクリックし、表示されるメニューから クエリモデル作成をクリックします。
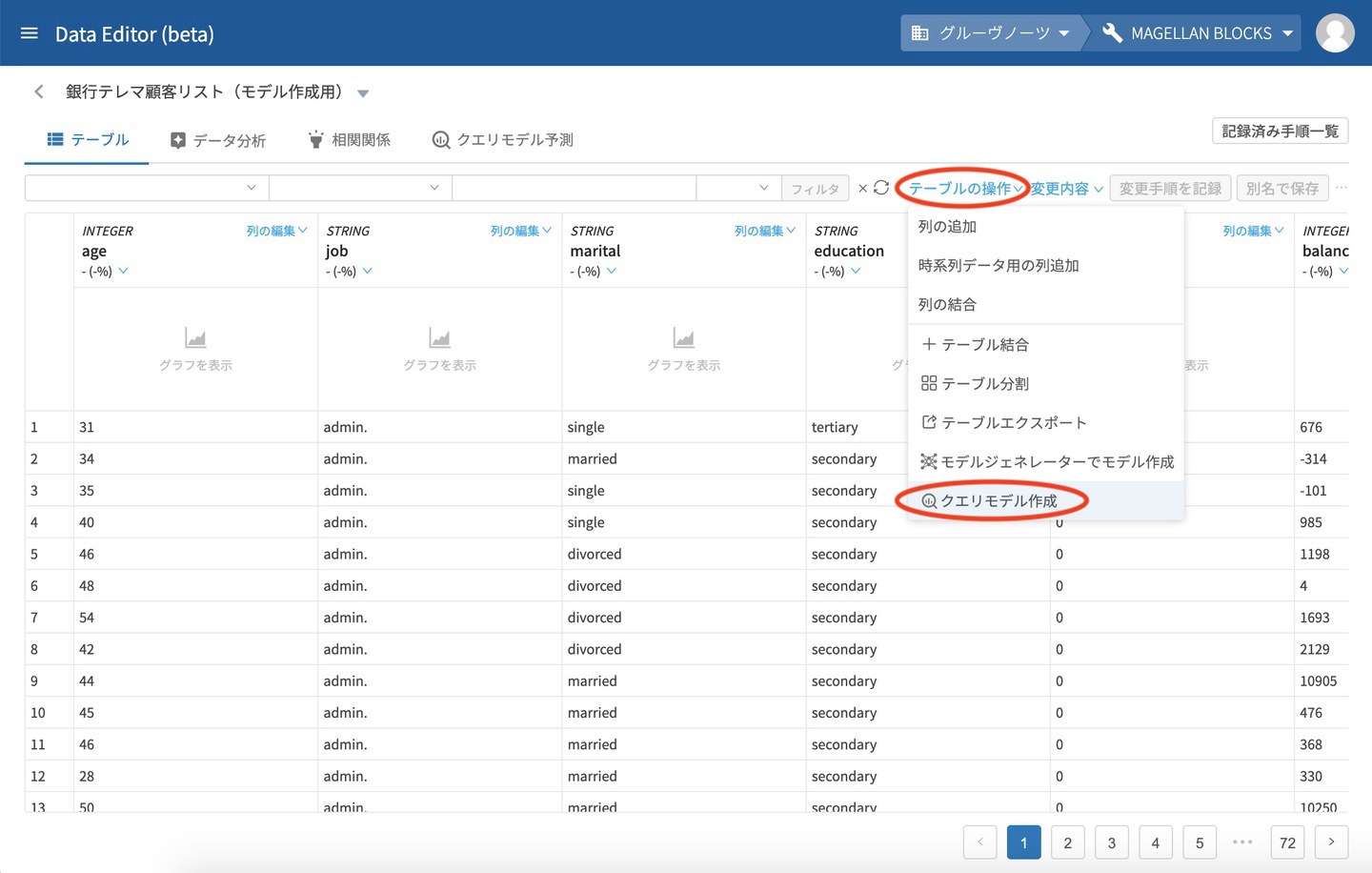
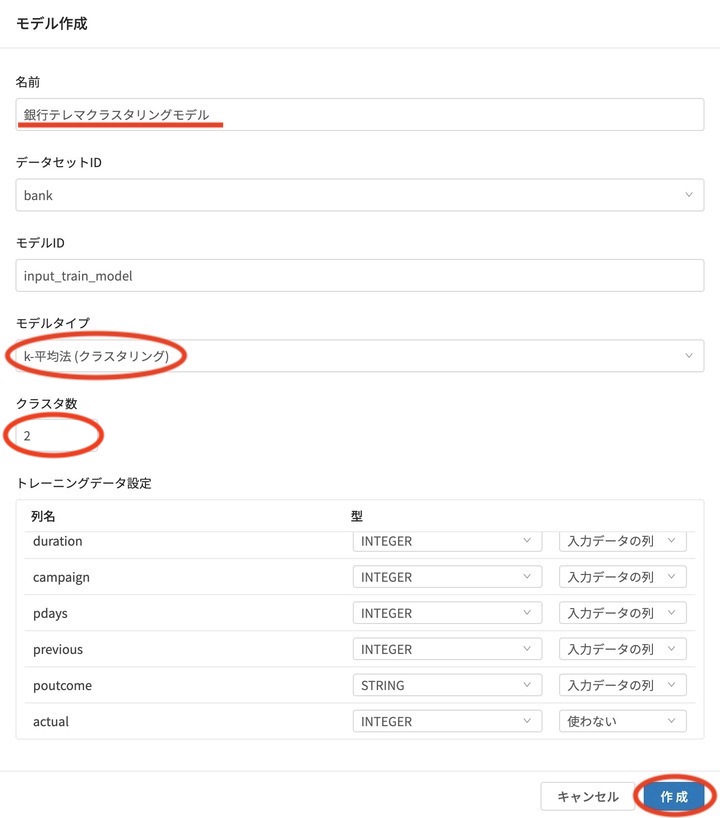
モデル作成の画面が表示されるので分かりやすい名前を入力し、モデルタイプを k-平均法(クラスタリング)を選択します。
そして クラスタ数 を指定します。初期値が2となっていますが、何パターンかのモデルを作ってみて比較すると良いと思います。
最後にトレーニングデータ設定で使わない項目があればそのように設定し、右下の 作成 をクリックするだけでクラスタリングモデルができあがります。
2.予測
続いて作成したモデルでクラスタリングの予測を行います。対象となるデータが入った予測用のテーブルを開きます。
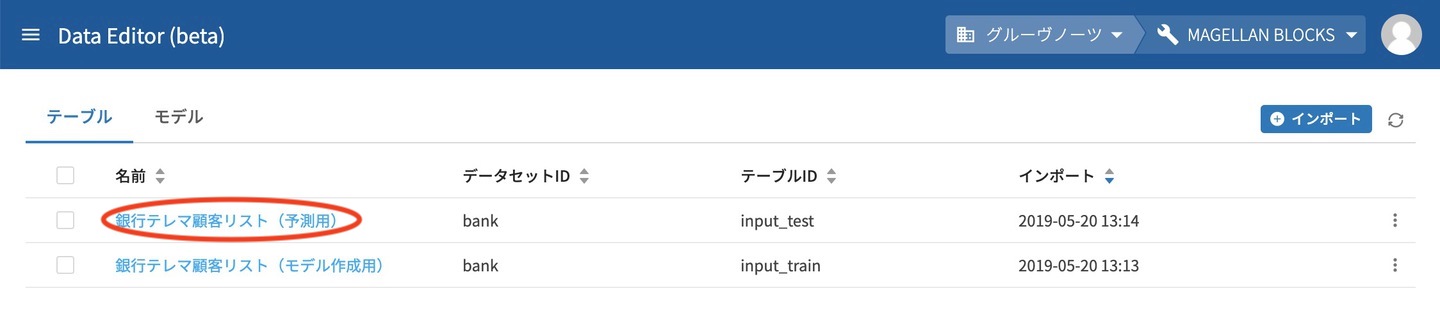
テーブルを開いたら右側のタブの クエリモデル 予測を選択します。

予測に使うモデルを選択してください。 のプルダウンから、今回作成したモデルを選択します。

モデルを選び終わったら後は 予測 をクリックするだけです。

予測結果が表示されました。 最初の列の CENTROID_ID が自動的に作成されたクラスターです。一番上の行で見るとkey=16822のデータがCENTROID_ID=2にクラスタリングされたことがわかります。
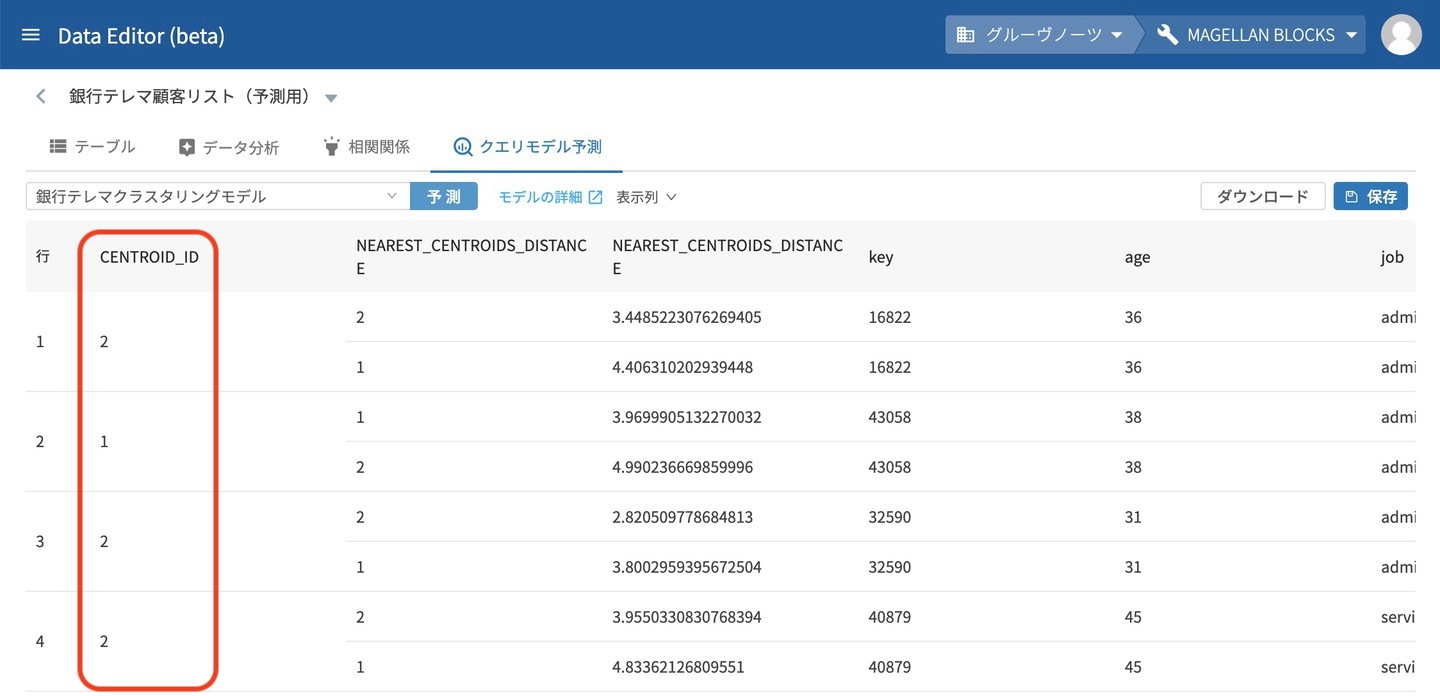
このようにDataEditorのクエリモデルに新しく追加されたクラスタリングの機能を使って、顧客クラスタや店舗クラスタなど様々なクラスタを簡単に作成できます。
データを準備するだけでDataEditorですぐクラスタリングモデルを作成できるので、ぜひご活用いただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。