MAGELLAN BLOCKSのDataEditorで、クエリーを書かずに線形回帰・ロジスティック回帰を利用することができます。
※DataEditorで表示されるモデルの重みは、モデルジェネレーターで作成されたモデルの重要度と同じではありません。比較される際は参考値としてご利用ください。
それでは早速使っていきましょう。データはいつもの電力需要予測です。
1.モデル作成
モデルを作成するには、DataEditorに登録されているテーブルからモデル作成元となるデータが入ったテーブルを選びます。該当のテーブルのメニューから クエリモデル作成 をクリックします。
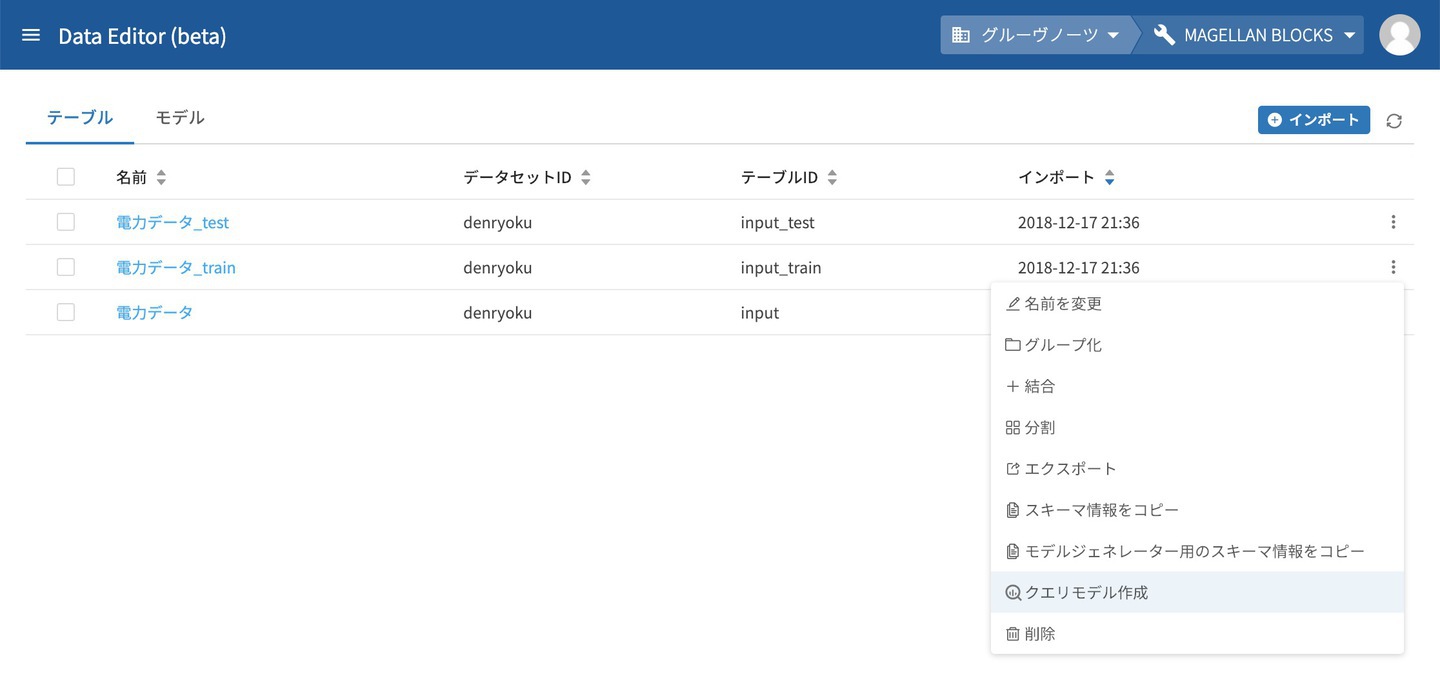
モデルを作成するための画面が表示されます。 まずはモデルの種類を選択します。DataEditorで作れるモデルには二種類あります。
- 線形回帰
- ロジスティック回帰
線形回帰は数値データを元に数値の量を予測するものです。モデルジェネレーターで言う数値回帰と同じ使い方になります。
今回は、線形回帰を利用します。ロジスティック回帰は数値データを元に分類判断をするものです。モデルジェネレーターで言う数値分類と同じ使い方になります。
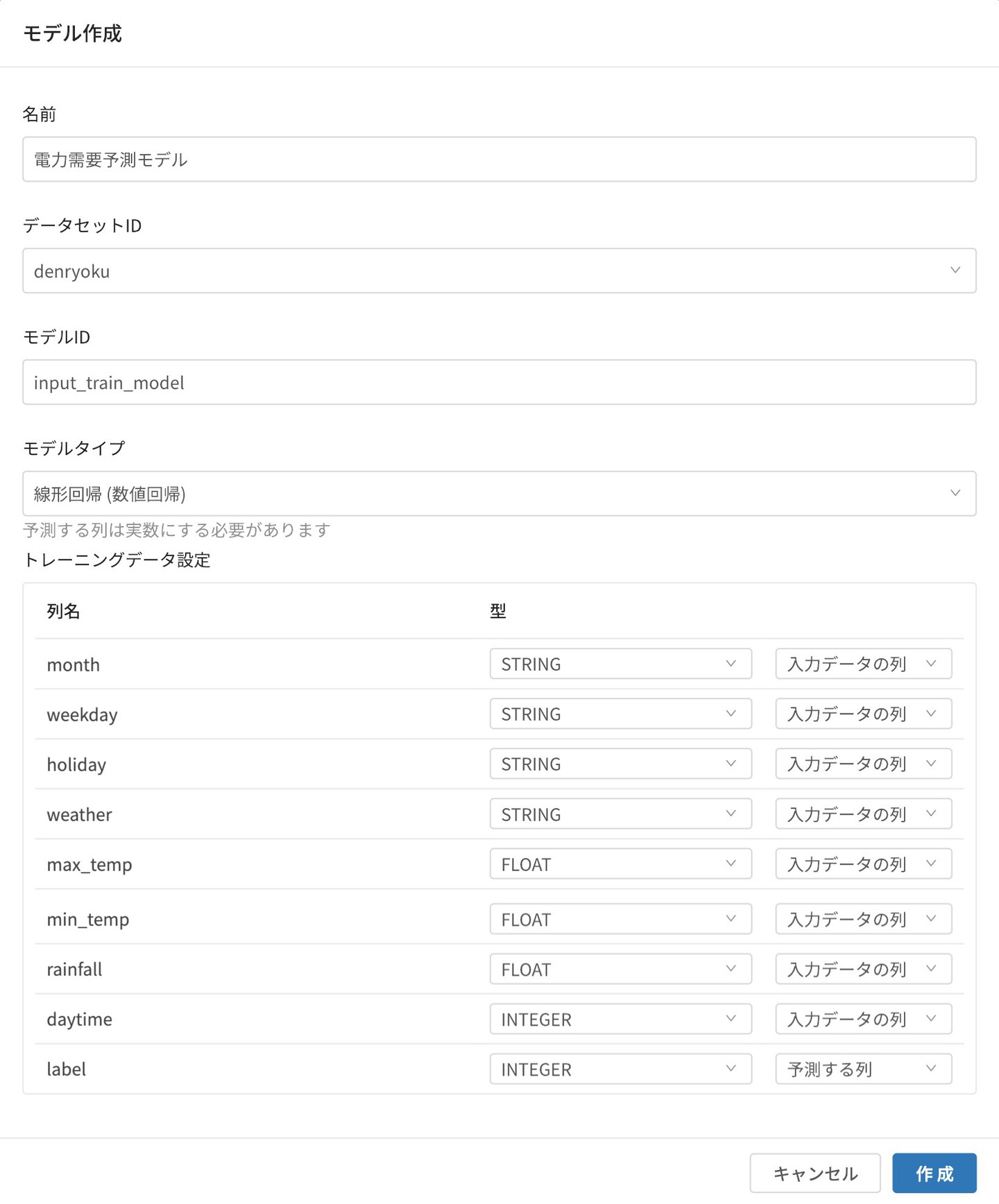
モデルタイプの選択と、予測因子の型と予測対象となる項目について設定を行います。設定が完了したら、 作成 をクリックすると線形回帰のモデルが作成されます。

2.モデル情報の確認
モデルが作成されると、テーブル一覧の他にモデル一覧のタブが表示されます このモデル一覧から作成したモデルを選びクリックします。
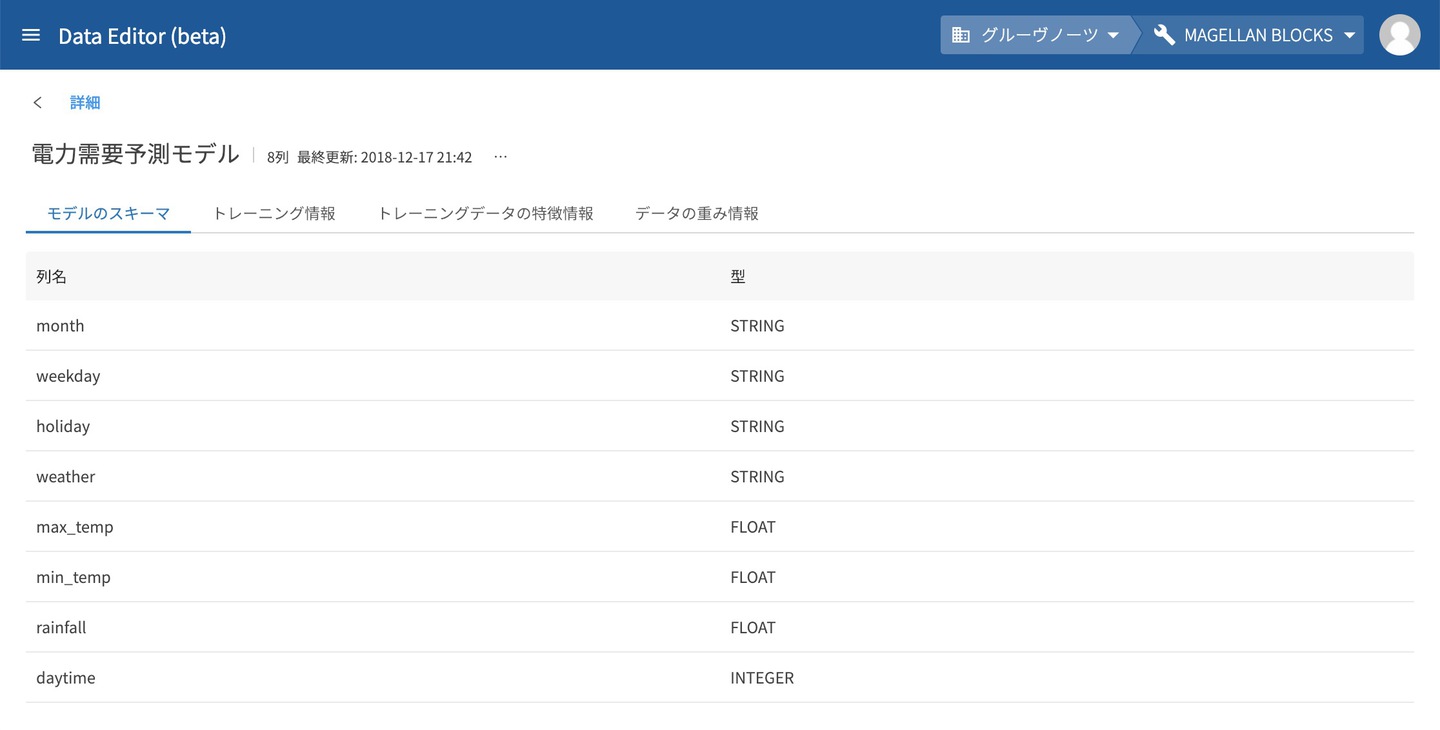
モデルのスキーマ
予測因子の項目名および型などの定義
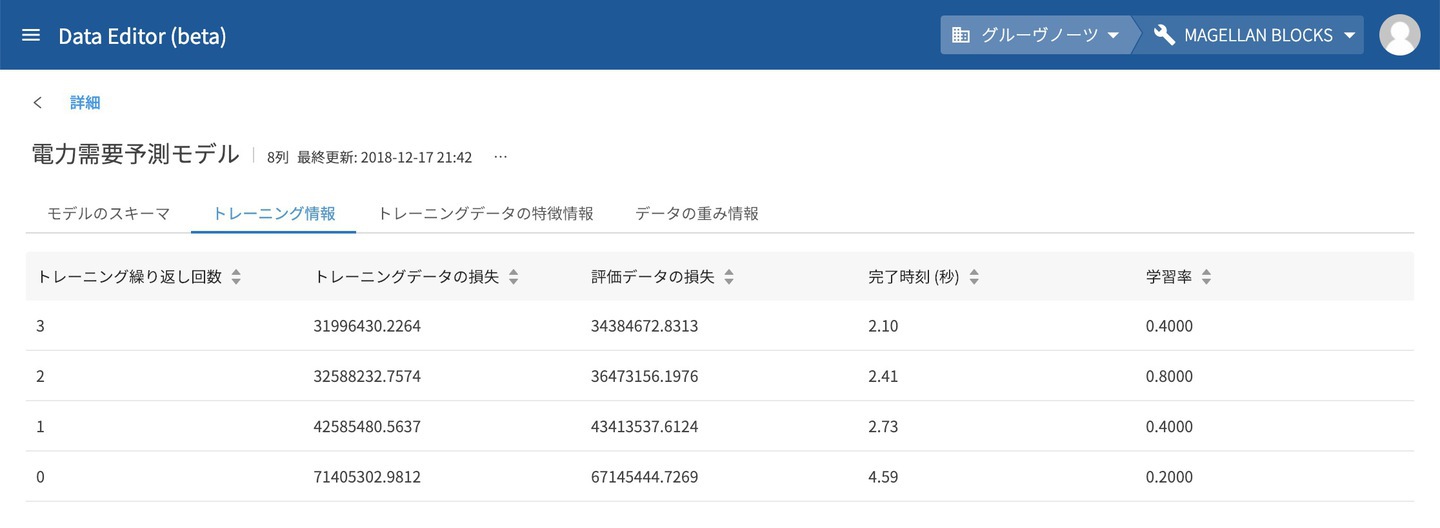
トレーニング情報
モデル作成時に内部的に行われたトレーニングに関する情報
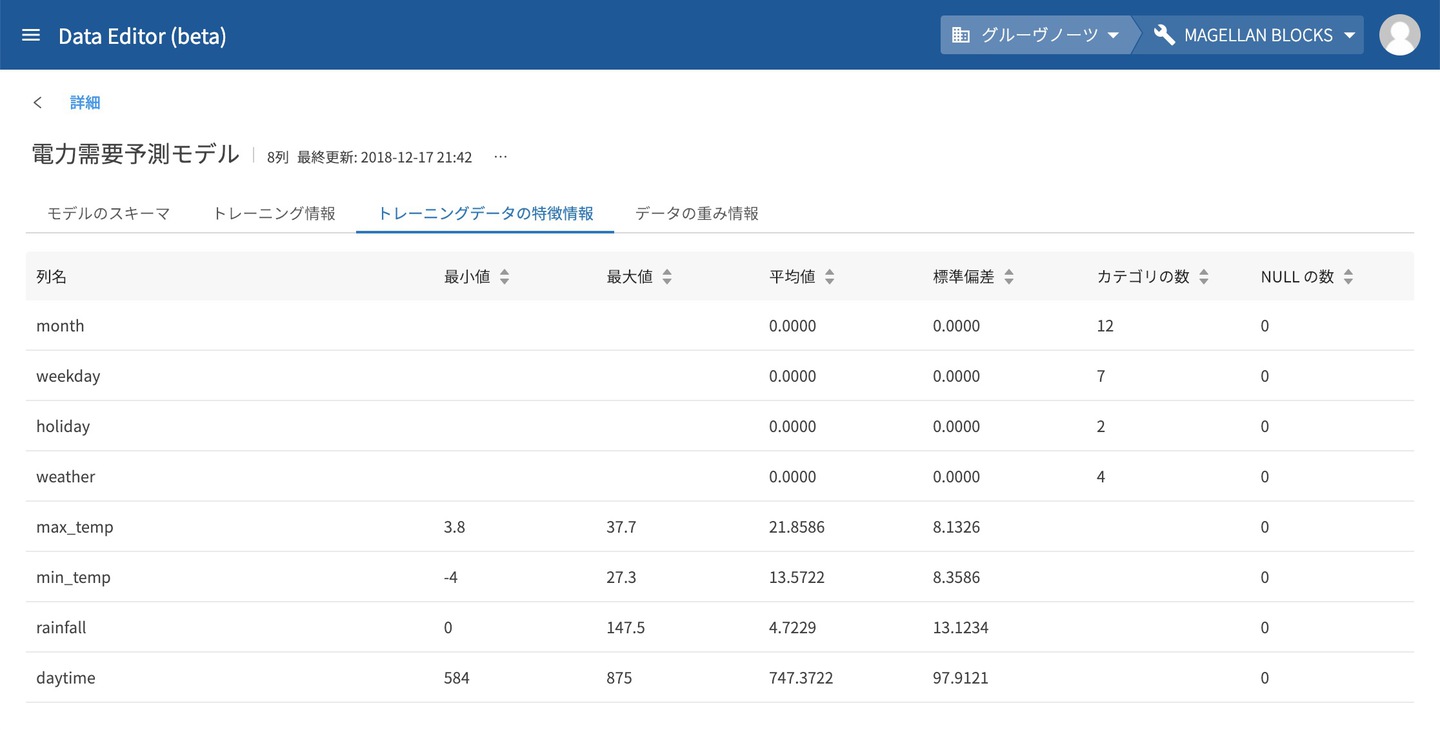
トレーニングデータの特徴情報
学習データについて予測因子ごとの最大・最小・平均値などの統計情報
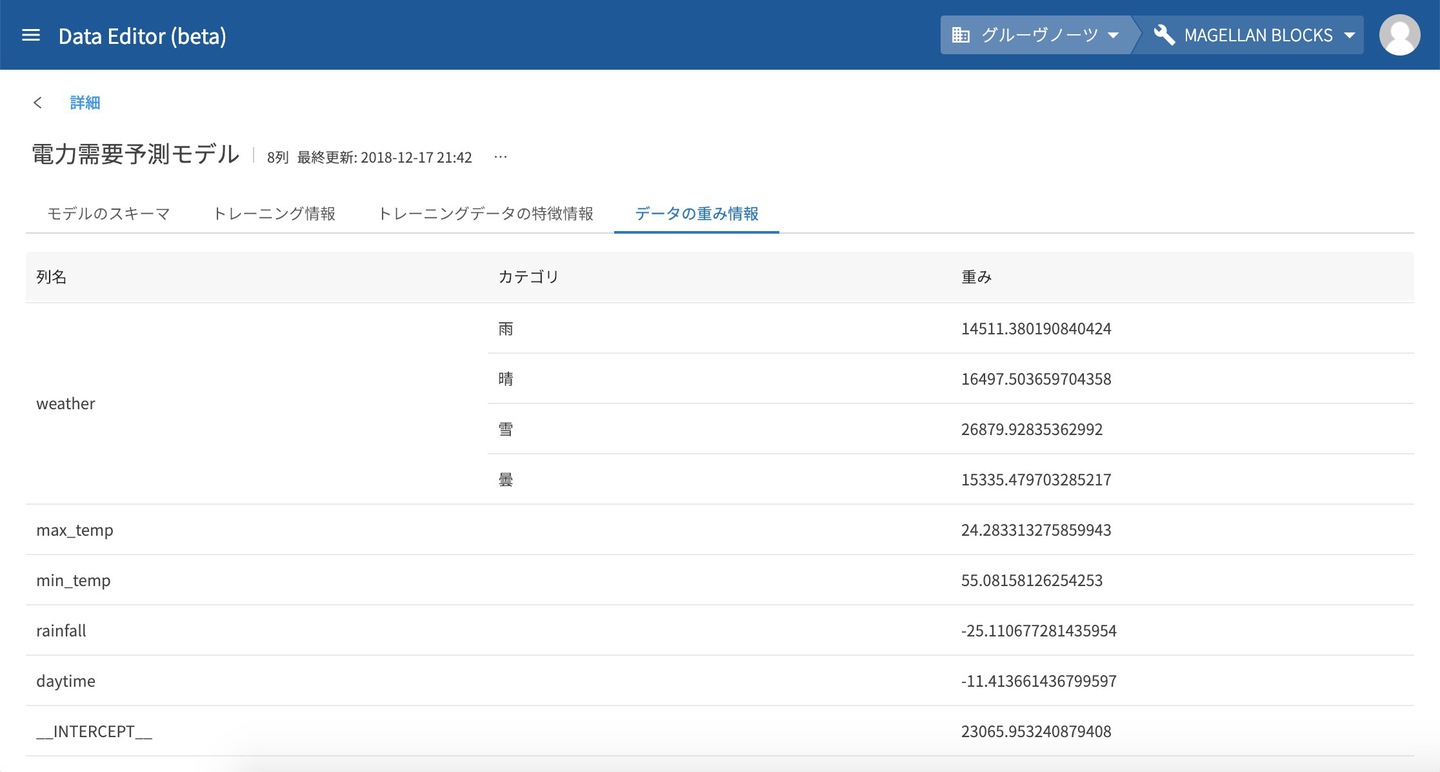
データの重み情報
各予測因子についての重みや切片の情報
3.予測
予測はまず、テーブル一覧から予測に使うテーブルを選択します。

テーブルの画面が表示されたところで予測のタブをクリックし、利用するモデルを選択して 予測 をクリックするとそれだけで予測することができます。
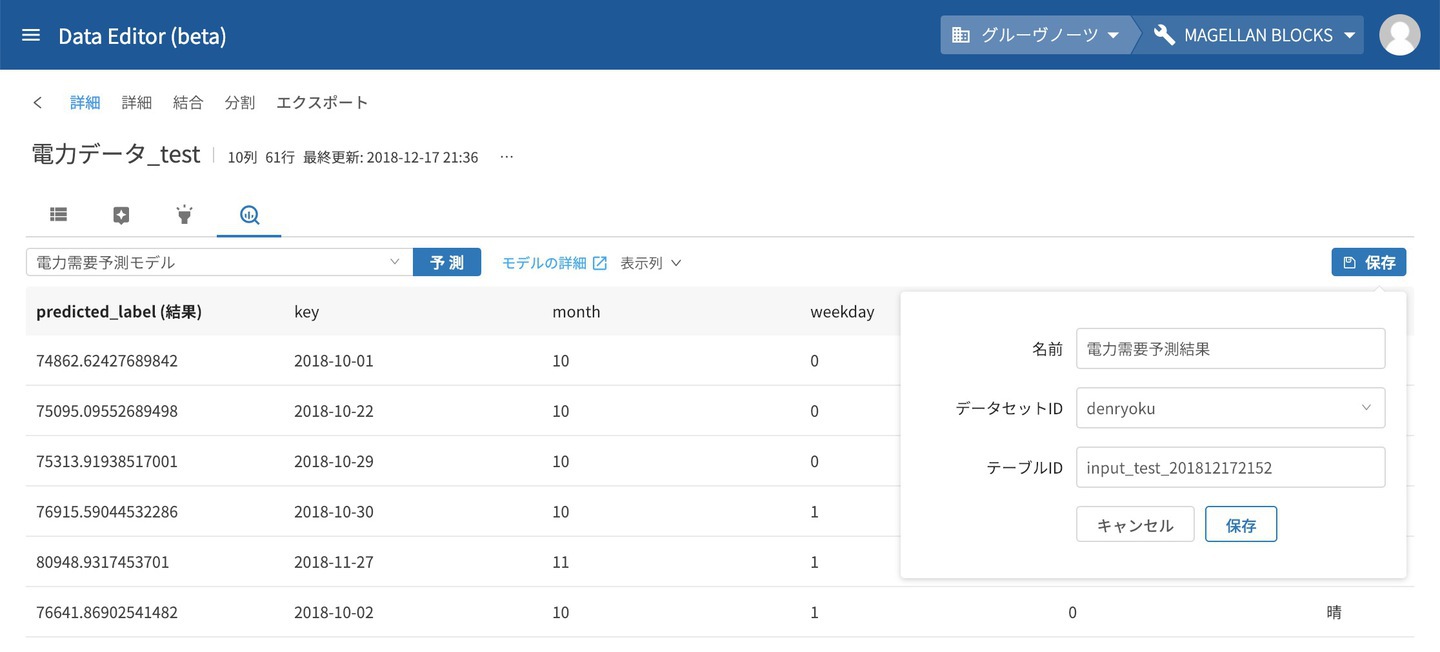
予測対象のデータに含まれる key ごとに予測結果 predicted_label が表示されます。
この結果から保存をクリックすると、DataEditorの新たなテーブルとして利用することができます。
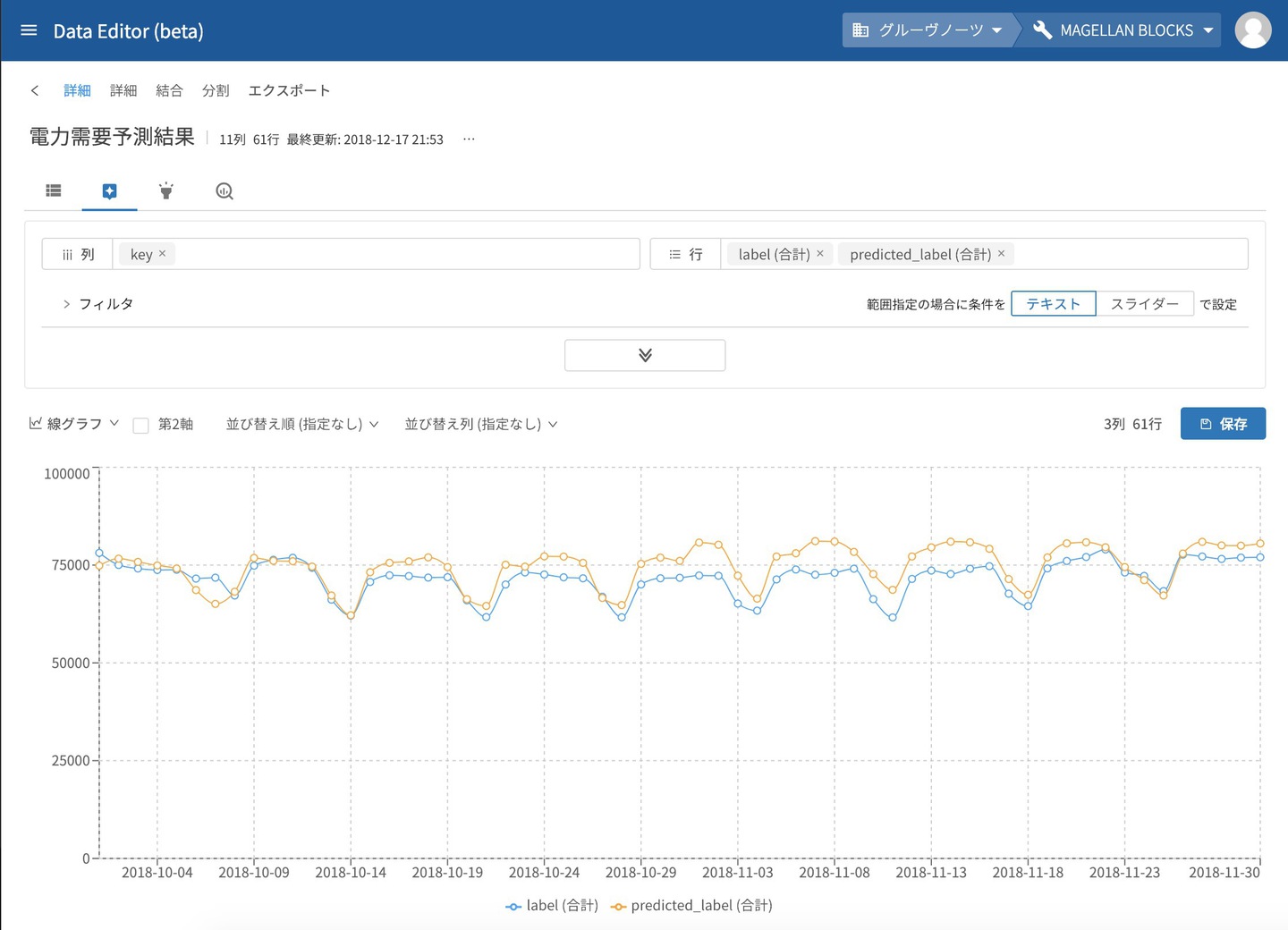
新たなテーブルとして保存ができると言うことは、実績であるlabelと予測結果のpredicted_labelを線グラフにして比較することなんかも簡単に実現できます。
さいごに
このように新しくDataEditorに追加されたモデル作成の機能は簡単にモデル作成・予測を行うことができます。
重回帰分析と言うとExcelなんかでは16項目までの制限があったりデータ量によって時間がかかったりしますが、DataEditorであればそう言ったこともなく利用できるのでぜひご活用いただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。