数値回帰モデルを利用した需要予測
はじめに
MAGELLAN BLOCKS(BLOCKS)の機械学習サービスを使うと、数値回帰を通じてさまざまなデータから予測ができます。数値回帰は、過去のデータから数値的な予測を導き出す手法です。たとえば、天候や曜日のデータを活用して、店舗の来店者数、商品の販売数、交通機関の利用者数などの予測が可能です。
このチュートリアルでは、東京都の気象情報と日中時間(日の出から日の入りまでの時間)を用いて、電力使用量の予測(電力の需要予測)を例に挙げます。特に夏の暑い日や冬の寒い日など、季節による電力使用量の変動を分析するシナリオを取り上げ、BLOCKSを使った数値回帰の具体的な手順を解説します。

数値回帰のおおまかな流れ
BLOCKSの機械学習サービスは、「DataEditor」および「フローデザイナー」で利用できます。
このチュートリアルでは、「DataEditor」を使用して数値回帰を行います。下図は、今回の例における数値回帰の流れです。

- Microsoft Excel(Excel)を使って東京都の気象情報・日中時間・電力使用量をまとめたCSVファイルを作成
- DataEditorでCSVファイルを取り込み(インポート)、トレーニング用データと予測用データに分割
- DataEditorで学習(トレーニング)
気象情報および日中時間と電力使用量との因果関係を学ばせます。
このトレーニングの結果として、モデルと呼ばれる学習成果が得られます。 - DataEditorで電力使用量を予測
数値回帰を試してみよう
このチュートリアルでは、下図のステップで数値回帰の一連の流れを解説します。
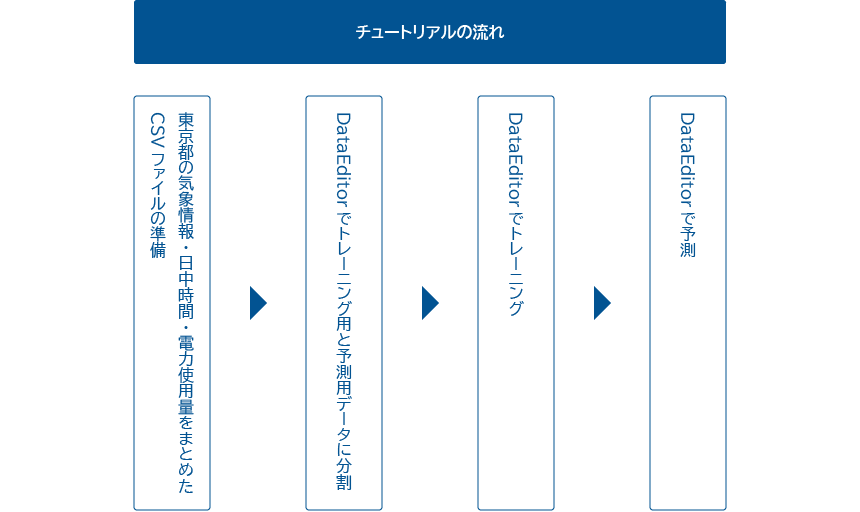
機械学習では、まとまったデータが必要不可欠です。機械学習では、まとまったデータを元に学習を行うことで、予測が可能となります。このため、機械学習においてデータの収集と加工が最初の作業となります。
なお、チュートリアルを進めるにあたって、BLOCKS推奨のウェブブラウザーGoogle Chromeを準備してください。Firefoxでも構いませんが、このチュートリアルでは、Google Chromeの使用を前提にしています。
CSVファイルを準備しよう
まず、数値回帰のトレーニングと予測に必要なデータを準備します。データは、カンマ(,)区切りのCSVファイル(BOMなし・UTF-8)で用意します。
トレーニング用データは、東京都の日毎の気象情報および日中時間と電力使用量を使用します。
- 最高気温
- 最低気温
- 日照時間
- 平均湿度
- 日中時間
- 電力使用量
これらのデータは、気象庁・国立天文台・東京電力パワーグリッドの各ホームページから入手できます。
- 最高気温・最低気温・日照時間・平均湿度:気象庁
- 日中時間:国立天文台
- 電力使用量:東京電力パワーグリッド
report 注意
日中時間は、国立天文台が提供する日の入りと日の出の時間から算出します。時間の単位は分とします。
このチュートリアルでは、2018年1月1日から2020年12月31日までの3年間のデータを準備し、トレーニング用データと予測用データに分けて使用します。
| データの種類 | データ量(期間) |
|---|---|
| トレーニング用データ | 2018年1月1日から2020年11月30日までの2年11か月分 |
| 予測用データ | 2020年12月1日から2020年12月31日までの1か月分 |
重要
予測用データは、実運用では未来のデータを使用します。このチュートリアルでは、実運用前の検証段階を想定しています。このため予測用データは、トレーニング結果の確からしさをテストするため、トレーニングには使用していない過去のデータを用います。
因子については、まとめたデータを用意しました。
| データ | 説明 |
|---|---|
| cloud_download サンプル気象データ(weather_daytimeminutes.csv) |
気象庁と国立天文台が提供するデータから東京都の気象情報と日中時間をひとつにまとめたカンマ(
左の欄のリンクをマウスの右ボタンでクリックしてください。表示されるメニューからリンク先を保存する旨の項目をクリックするとダウンロードできます。 announcement 警告 |
結果となる値の電力使用量は、2次配布が許可されていないため、東京電力パワーグリッドのダウンロードページから直接ダウンロードします。
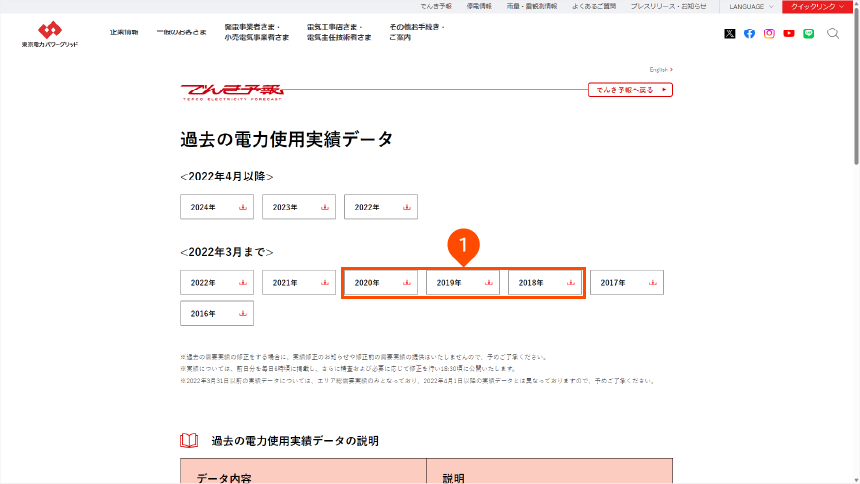
ダウンロードは、2020年・2019年・2018年のリンク(❶)をそれぞれマウスの右ボタンでクリックしてください。表示されるメニューからリンク先を保存する旨の項目をクリックするとダウンロードできます。いずれもカンマ(,)区切りのCSVファイルです。ファイル名は、それぞれjuyo-2020.csv・juyo-2019.csv・juyo-2018.csvです。
これで、データがすべて揃いました。これから、これらのデータをBLOCKSで扱えるデータ形式に加工していきます。
データの加工方法は色々ありますが、このチュートリアルでは、Excelで因子と結果となる値をひとつにまとめます。その後、BLOCKSのDataEditorで、トレーニング用データと予測用データへ分割します。
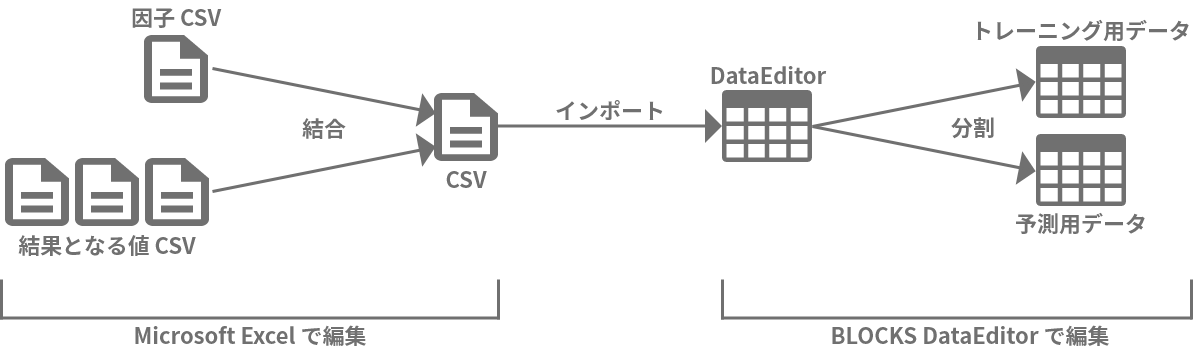
それでは、Excelで因子データと結果となる値をひとつにまとめていきます。形式は以下のように、因子→結果となる値の順に並べます。表の見出しは英数字とアンダースコア(_)で構成します(括弧内の表記が実際の見出し)。
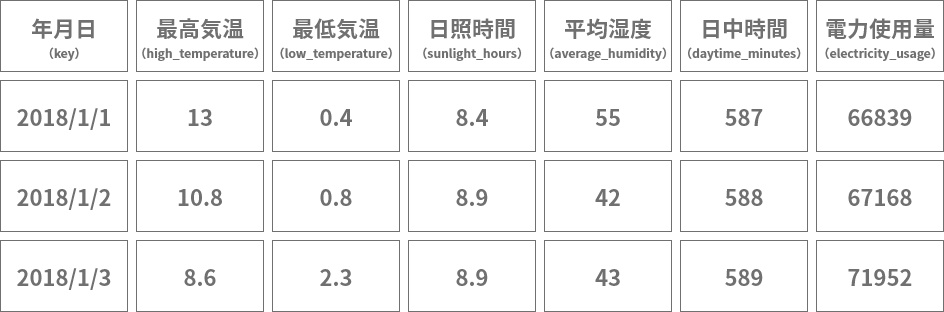
(図をクリックすると拡大表示されます。)
info 参考
因子年月日は因子データではありませんが、電力使用量をまとめたり、トレーニング用データと予測用データへ分割する際に必要です。
先にダウンロードしたweather_daytimeminutes.csvファイルをExcelで開きます。
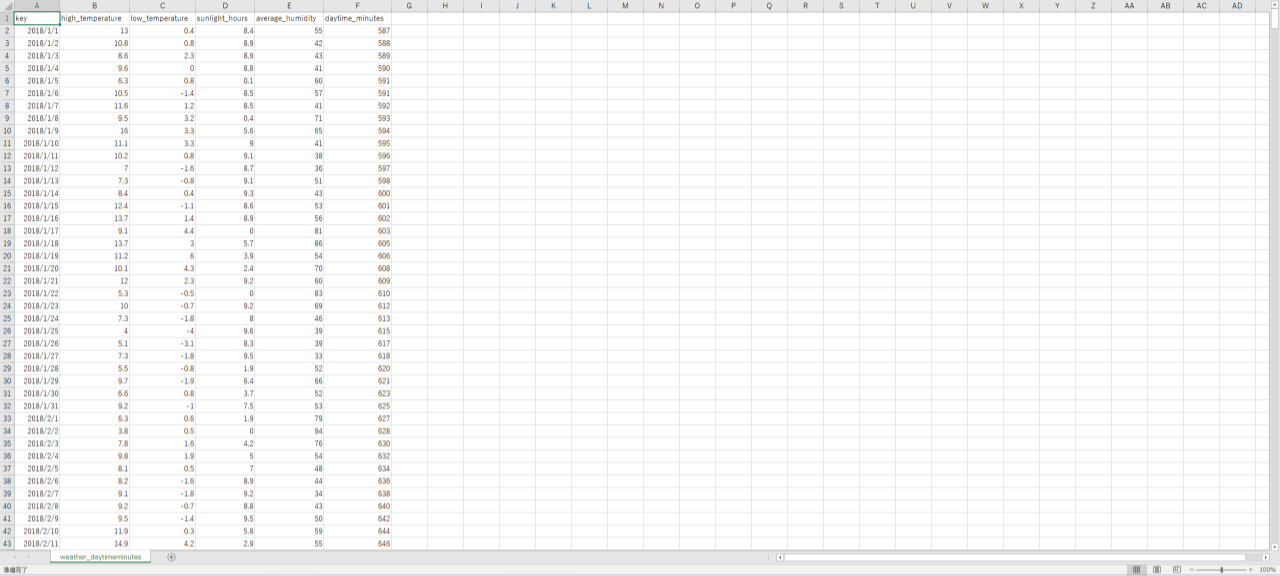
このファイル(ブック)の新しいワークシートに、3つの電力使用量のデータファイルを取り込んでいきます。
Excel 2019やMicrosoft 365を利用の方は、以下の手順を実施してテキストファイルウィザードの機能が利用できるようにしてください。
- 「
ファイル」メニューをクリック
- 「
オプション」をクリック
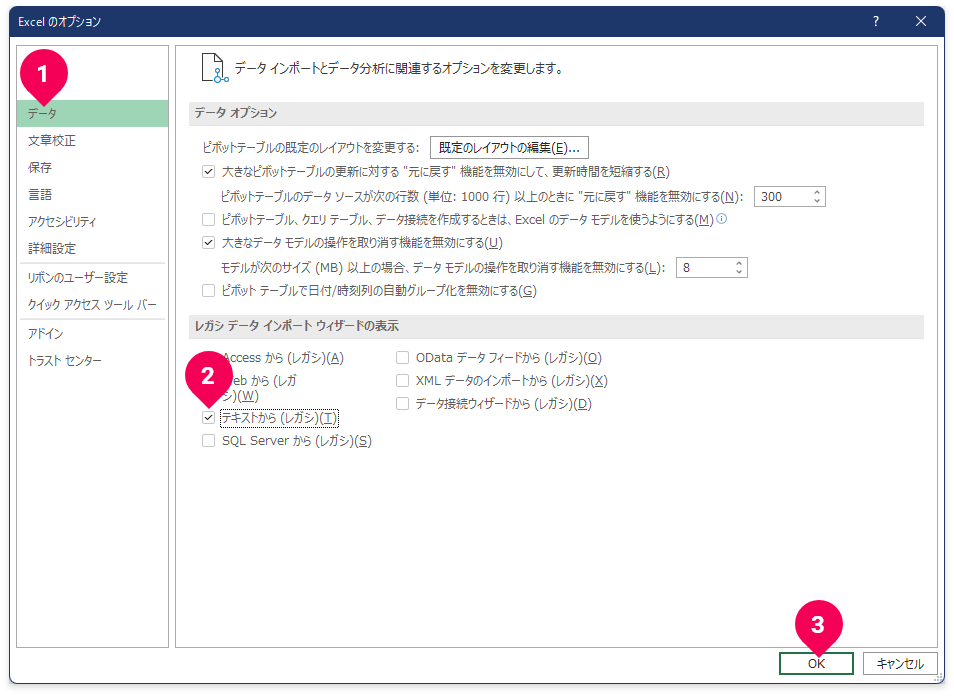
- 「
データ」をクリック - 「
テキストから(レガシ)」をクリック - [
OK]ボタンをクリック
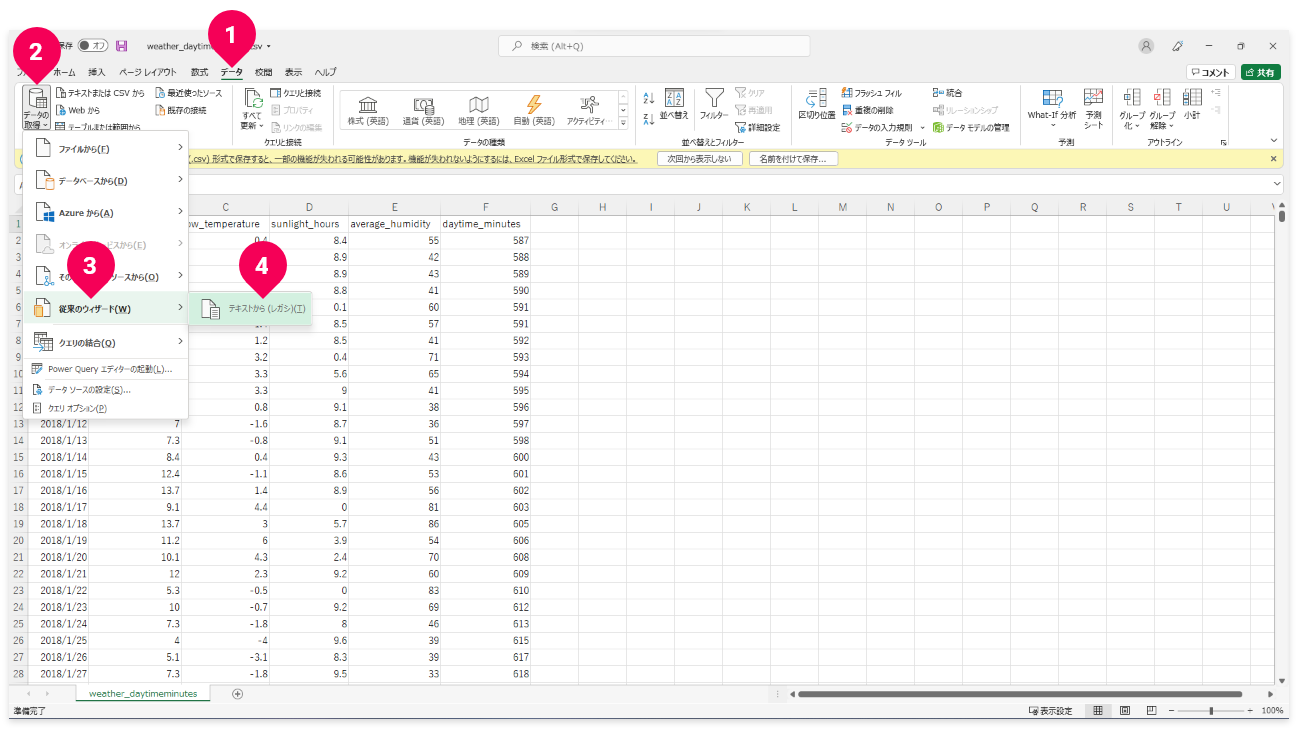
- 「
データ」をクリック - 「
データの取得」をクリック - 「
従来のウィザード」をクリック - 「
テキストから(レガシ)」をクリック
ヒント
Excel 2016以前をお使いの方は、[データ]→[テキストまたはCSVから]の順にクリックします。
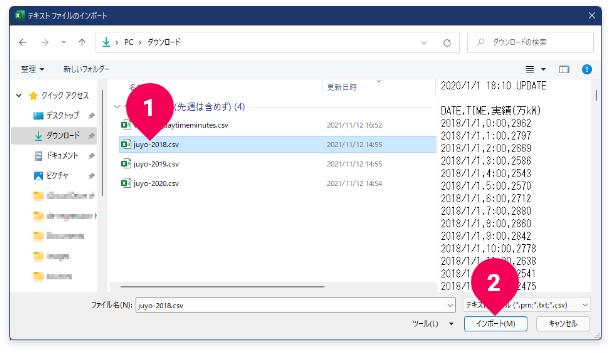
juyo-2018.csvファイルをクリック- [
インポート]ボタンをクリック
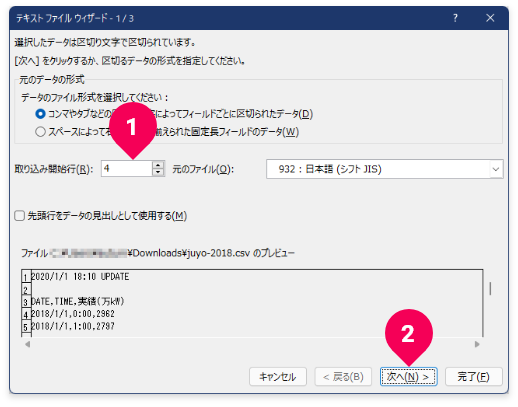
3行分のヘッダを読み飛ばす設定を以下の手順で実施します。
- [
取り込み開始行]を4に変更 - [
次へ]ボタンをクリック
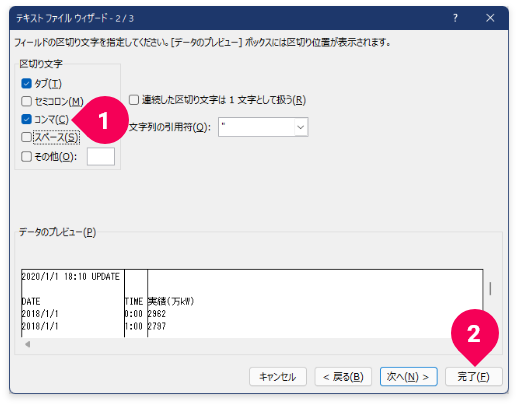
カンマ区切りのCSVファイルを読み込むための設定を以下の手順で実施します。
- 区切り文字の[
コンマ]のチェックボックスをオン - [
完了]ボタンをクリック
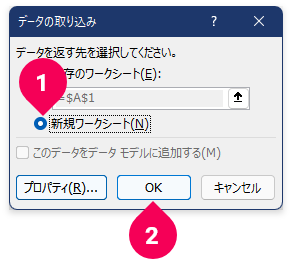
電力使用量のデータファイルは、新しいワークシートに取り込みます。
- [
新規ワークシート]をクリック - [
OK]ボタンをクリック
2つ目のファイルjuyo-2019.csvを取り込む準備として、アクティブなセルの位置を最終行の次行(A8761のセル)に移動させます。キーボード操作で、Ctrl + ↓の後に、↓を1回押します。これで、A8701のセルがアクティブになります。
先ほどと同じ手順(「データ」→「データの取得」→「従来のウィザード」→「テキストから(レガシ)」)で、juyo-2019.csvを取り込みます。
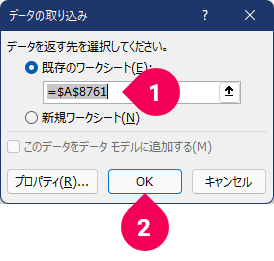
- 「
既存のワークシート」が選択され、=$A$8761となっていることを確認=$A$8761以外の場合は、=$A$8761に変更 - [
OK]ボタンをクリック
3つ目のファイルjuyo-2020.csvを取り込む準備として、アクティブなセルの位置を最終行の次行(A17521のセル)に移動させます。キーボード操作で、Ctrl + ↓の後に、↓を1回押します。これで、A17521のセルがアクティブになります。
先ほどと同じ手順(「データ」→「データの取得」→「従来のウィザード」→「テキストから(レガシ)」)で、juyo-2020.csvを取り込みます。
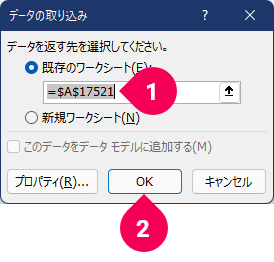
- 「
既存のワークシート」が選択され、=$A$17521となっていることを確認=$A$17521以外の場合は、=$A$17521に変更 - [
OK]ボタンをクリック
これで、3つの電力使用量のデータファイルがワークシートSheet1に取り込めました。データは、日・時・電力使用量の順で並んでいます。
取り込んだ電力使用量のデータを見ると、1時間毎の電力使用量が記録されています。これに対して、今回のトレーニングデータは、気象情報および日中時間を日毎のデータでまとめています。このため、取り込んだこのデータはそのまま使えず、電力使用量を日毎のデータに再集計する必要があります。
それでは、ワークシートSheet1の電力使用量を日毎のデータにまとめて、ワークシートweather_daytimeminutesに記録する手順を紹介します。
- ワークシートを
weather_daytimeminutesに切り替える - セル
G1をクリックし、electricity_usageと電力使用量の見出しを入力
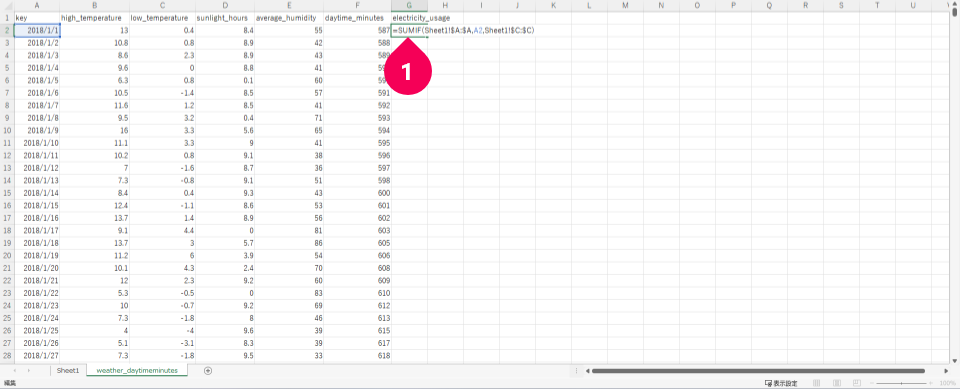
- セル
G2をクリックし、=SUMIF(Sheet1!$A:$A,A2,Sheet1!$C:$C)と日毎の電力使用量を求める計算式を入力
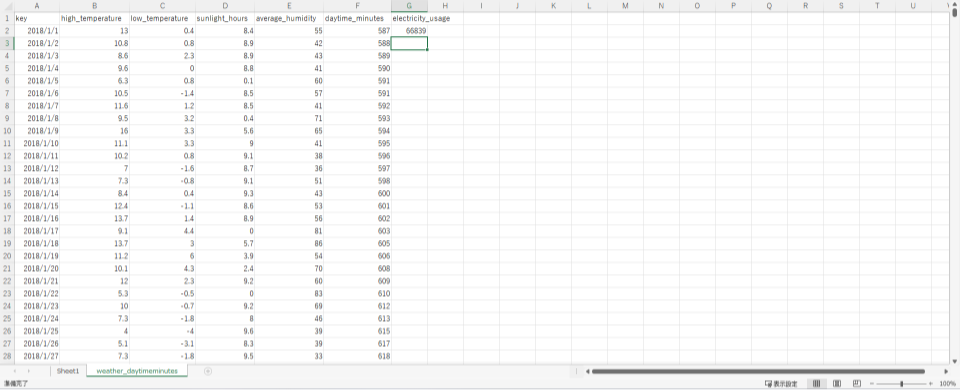
これで、2018年1月1日分の電力使用量が計算されてG2に入力されました。後は、G3以降のセルに同様の式を展開するだけです。
- G2セルをクリック
- G2セル右下隅の矩形部分をダブルクリック
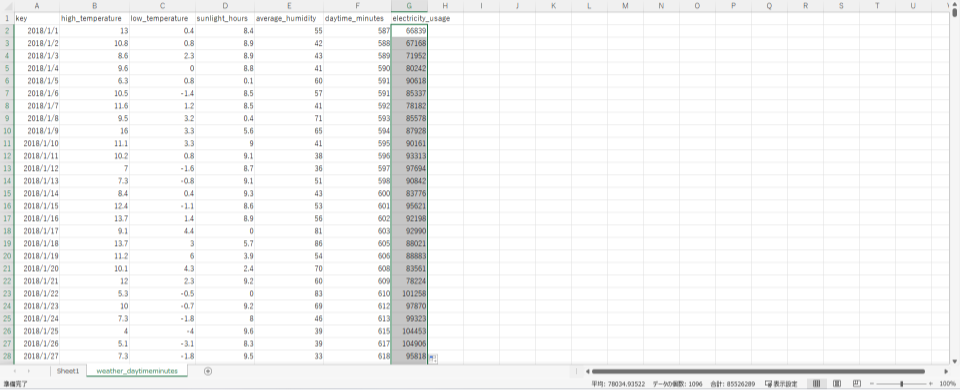
これで、3年分の気象情報・日中時間・電力使用量のデータがひとつにまとまりました。
この後はDataEditorで不正データの除去(クレンジング)と、トレーニング用データ・予測用データへ分割します。
DataEditorでは、カンマ区切りのCSVファイルが取り込めるので、Excelで加工中のデータをカンマ(,)区切りのCSVファイルへ出力します。
Excel上でF12キーを押します。
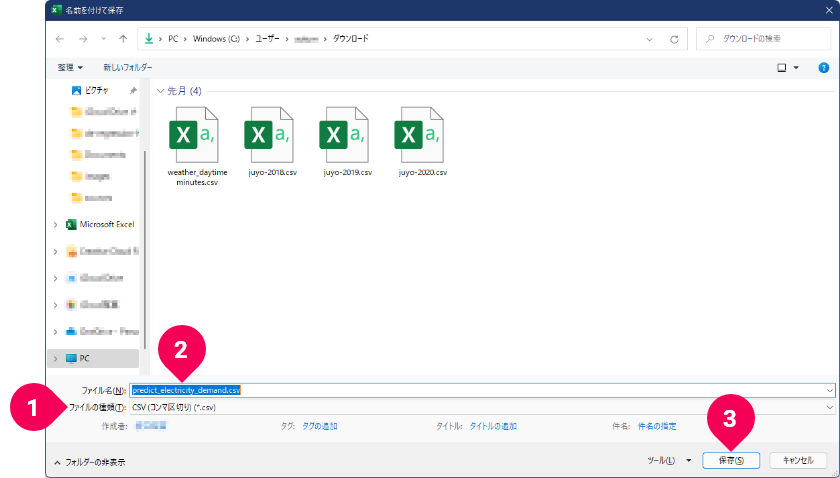
- 「
ファイルの種類」から「CSV(コンマ区切り)(*.csv)」をクリック - 「
ファイル名」をpredict_electricity_demand.csvに変更 - [
保存]ボタンをクリック
- [
OK]ボタンをクリック
これで、カンマ(,)区切りのCSVファイルの出力は完了です。Excelは、このまま保存せずに閉じても構いませんし、ブックとして保存しても構いません。このチュートリアルでは、以降このExcelのデータは使用しません。
DataEditorでデータを分割しよう
続いて、Excelで作成したデータをDataEditorでトレーニング用データと予測用データに分割します。
ウェブブラウザーで、BLOCKSにログインします。以降、BLOCKSログイン後を前提とした操作の解説です。

- グローバルナビゲーション左端のメニューアイコン(menu)をクリック
- 「
DataEditor」をクリック
作成したCSVファイルをDataEditorにインポートします。
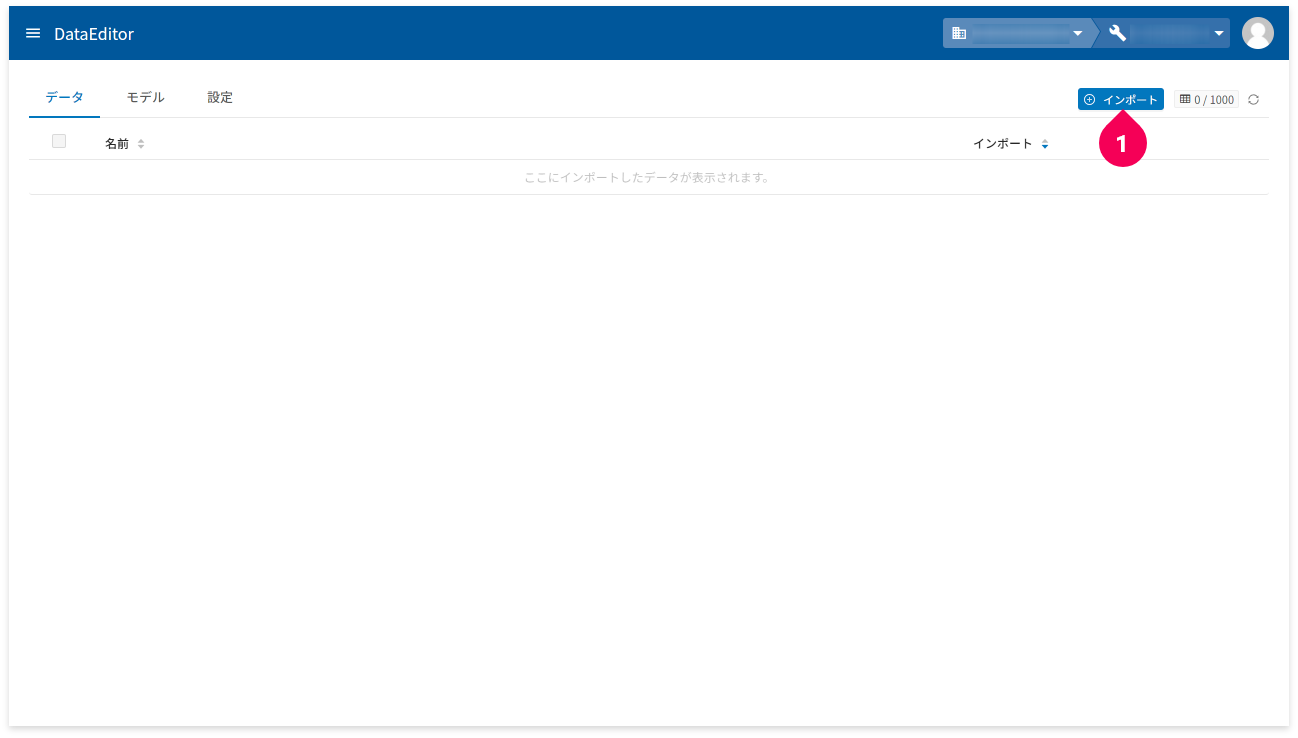
- [
インポート]ボタンをクリック
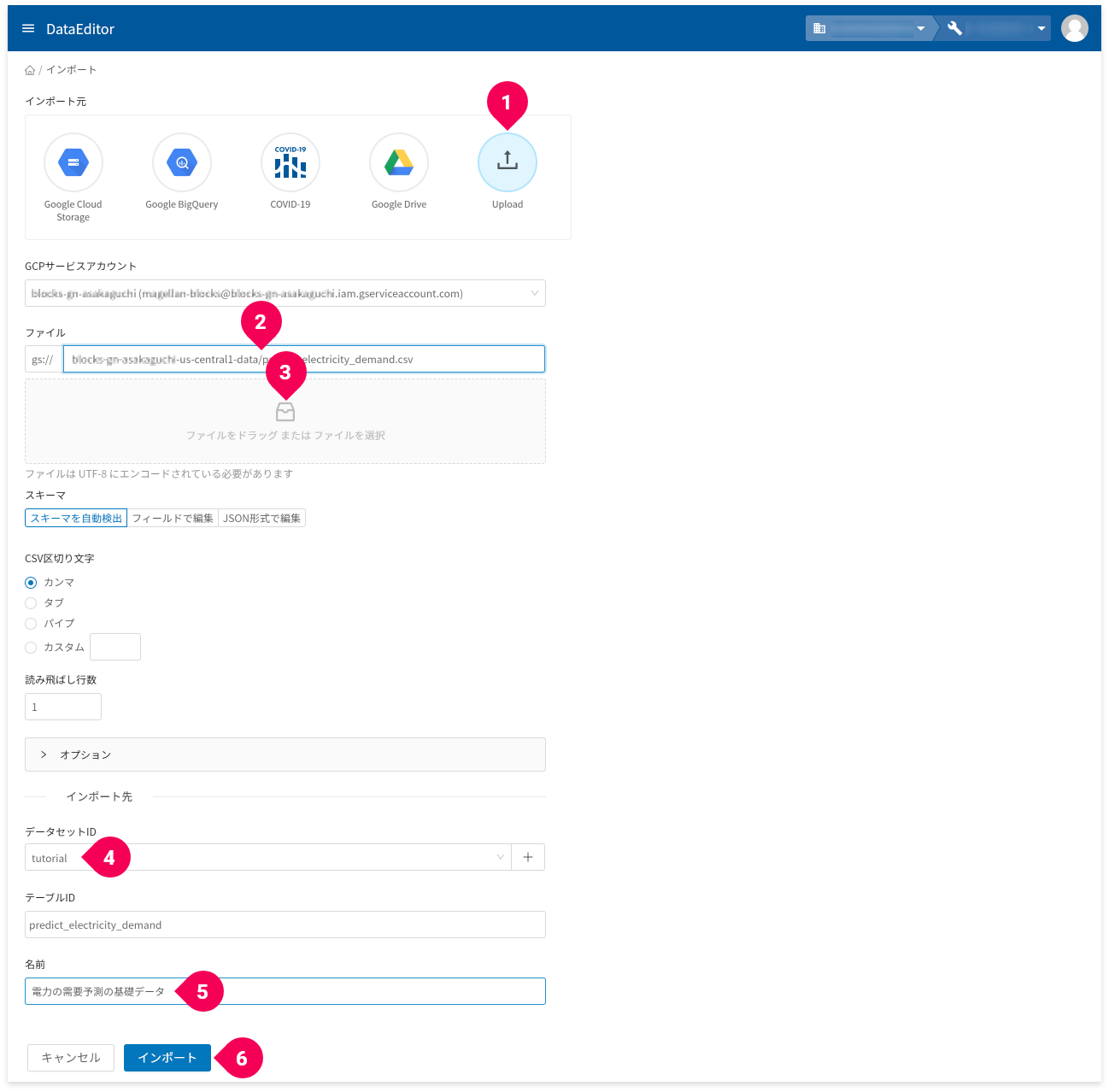
- インポート元から「
Upload」をクリック - GCS URLで
-dataで終わる項目をクリック - ファイル欄に、
predict_electricity_demand.csvファイルをドラッグ・アンド・ドロップ - データセットIDの[
+]ボタンをクリックし、tutorialと入力
既にtutorialがある場合はそれを選択 - 名前欄に、
電力の需要予測の基礎データと入力 - [
インポート]ボタンをクリック
ヒント
DataEditorは、BigQuery上のデータを視覚的に操作できるツールです。BigQueryに関する知識は必要ありませんが、BigQuery上の重要な要素であるデータセットとテーブルは指定する必要があります。Microsoft Excelに例えると、データセットはブックで、テーブルはシートに対応する概念です。
- [
開く]ボタンをクリック
インポートしたデータからトレーニング用データと予測用データに分割したデータを作ります。

- 「
テーブル」タブをクリック - 「
テーブル操作」から「テーブル分割」のアイコンをクリック
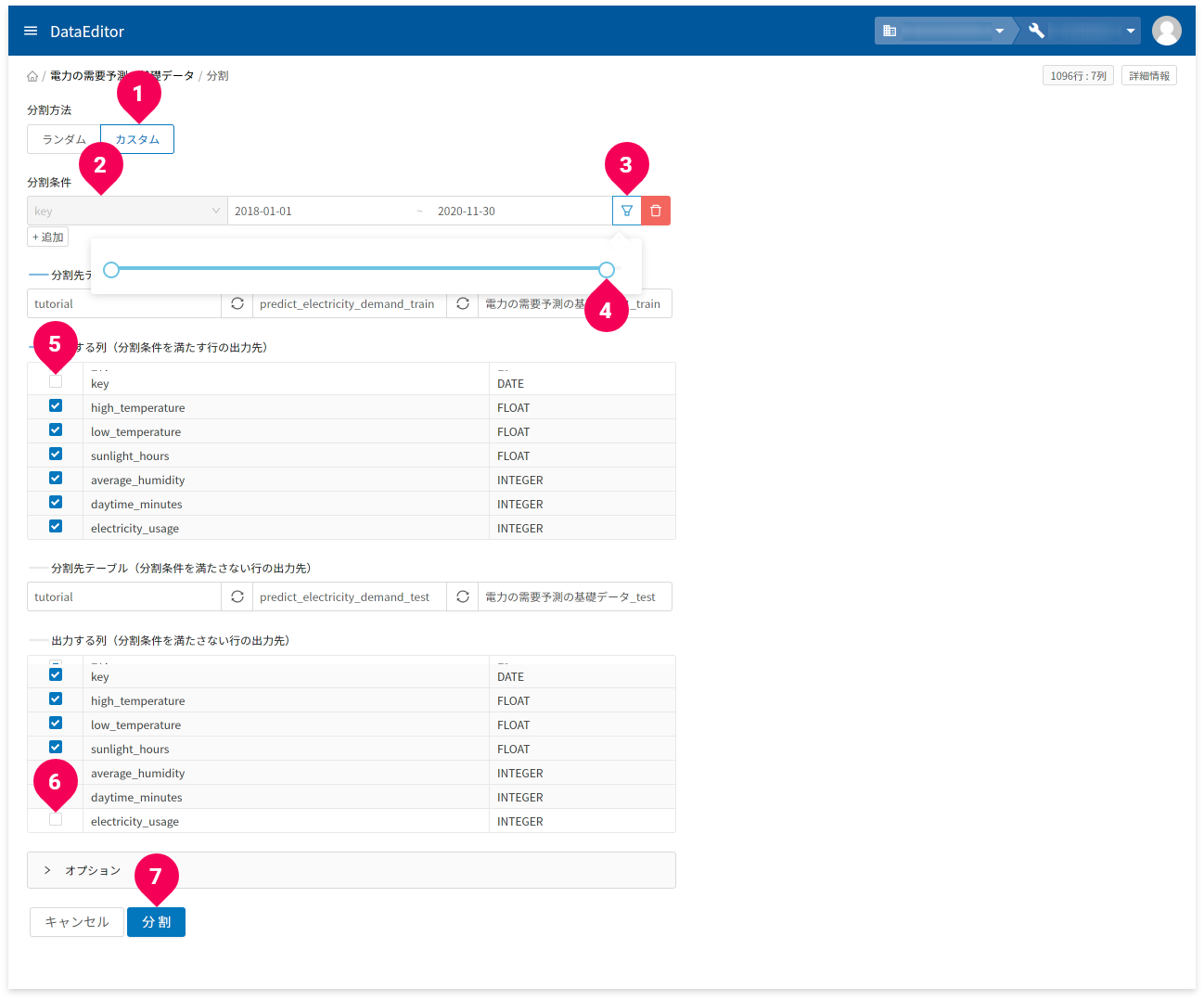
- 分割方法から「
カスタム」をクリック - 分割条件から「
key」をクリック - 同じく分割条件からアイコンをクリック
- スライダーを左にスライドさせ、日付が2020-11-30となるように調整
- 列名が
keyのチェックを外す
(トレーニング用データに必要ない年月日を取り除く) - 列名が
electricity_usageのチェックを外す
(予測用データに必要のない結果となる値を取り除く) - [
分割]ボタンをクリック
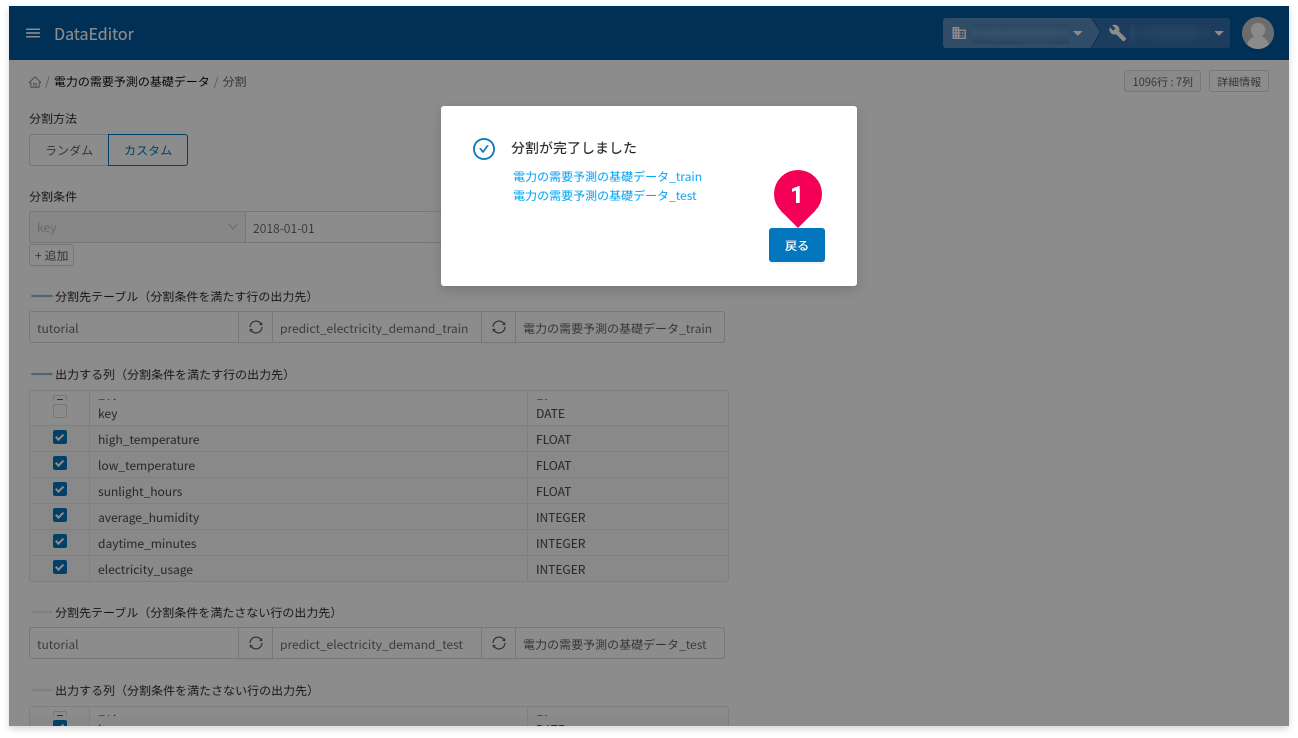
- [
戻る]ボタンをクリック
これで、データの分割が完了し、数値回帰のトレーニングと予測に必要なデータの準備ができました。
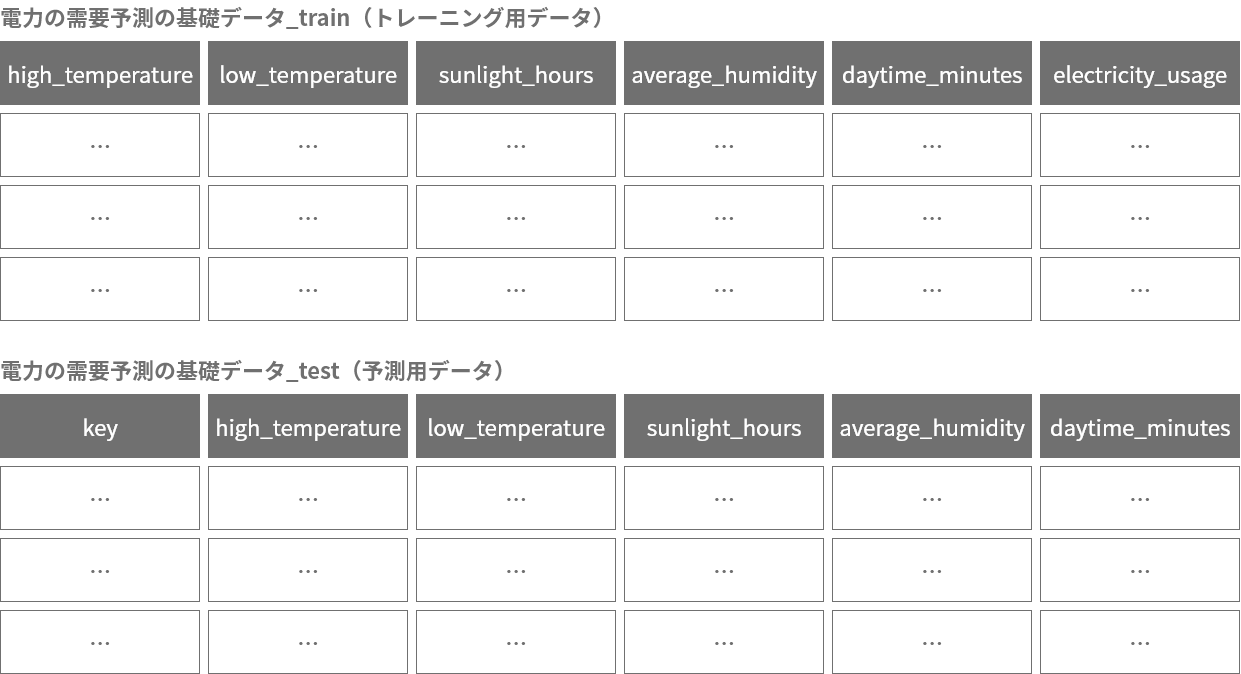
DataEditorでトレーニングしよう
先ほど準備したトレーニングデータを使いDataEditorでトレーニングします。
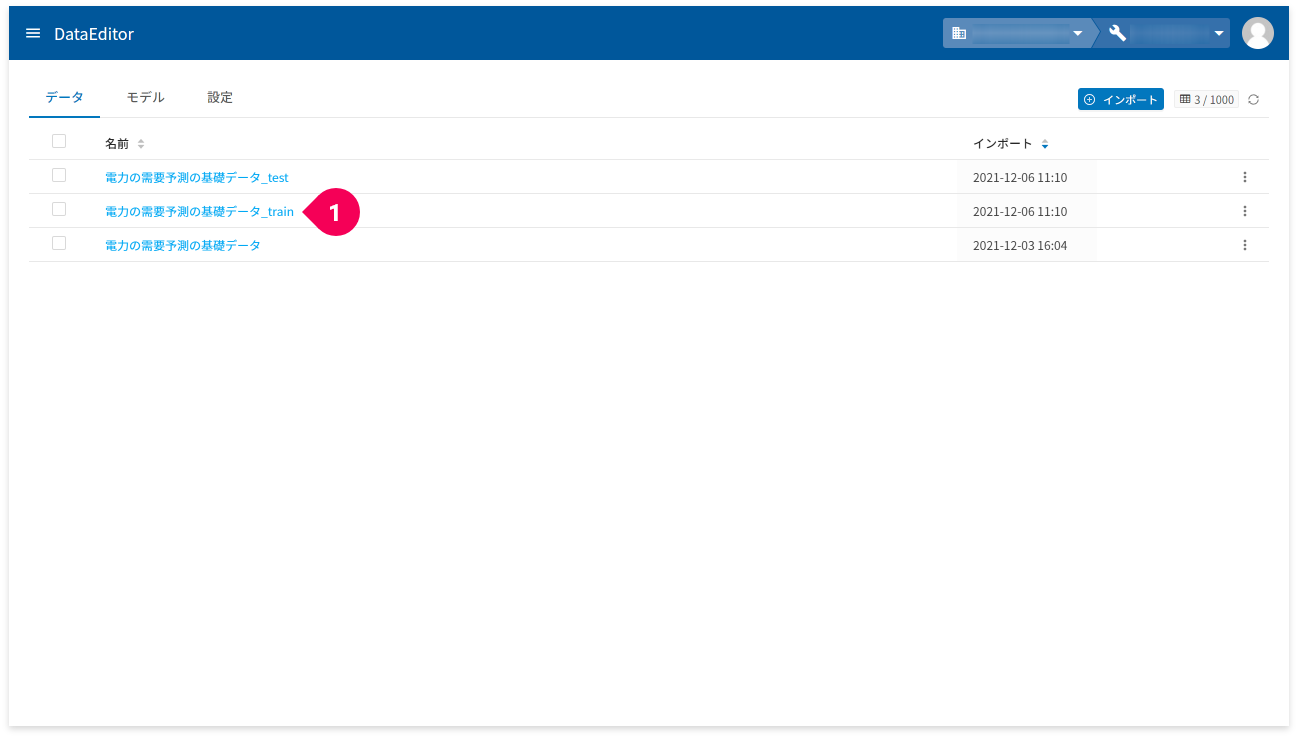
- 「
電力の需要予測の基礎データ_train」をクリック
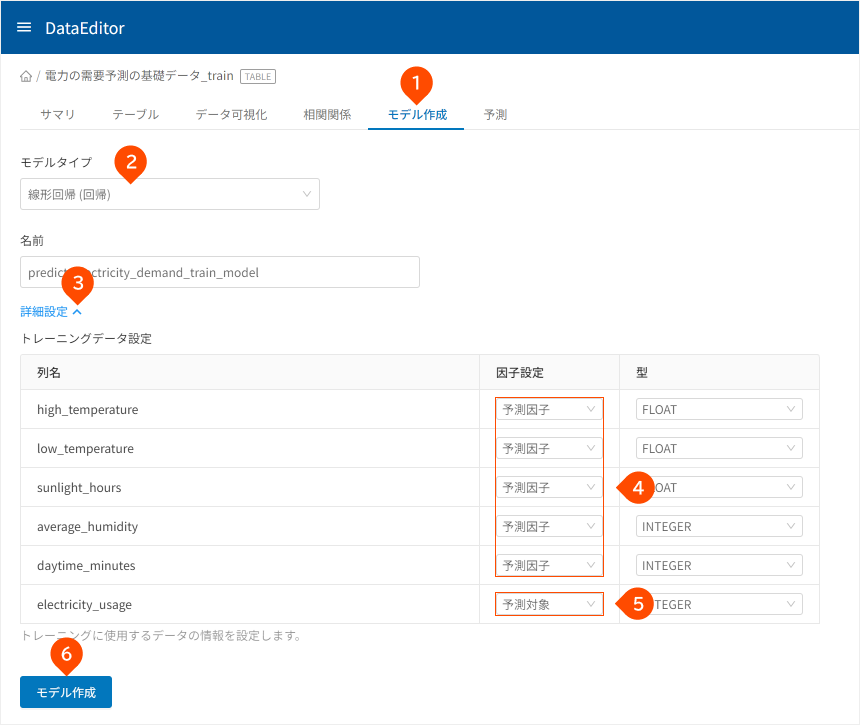
- 「
モデル作成」タブをクリック - 「
線形回帰(回帰)」をクリック - 「
詳細設定」をクリック high_temperature、low_temperature、sunlight_hours、average_humidity、daytime_minutes列の「因子設定」が「予測因子」となっていることを確認electricity_usage列の「因子設定」が「予測対象」となっていることを確認- [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
これで、トレーニングが始まります。しばらくお待ちください。
トレーニングの状況は、モデル一覧画面およびモデルの詳細画面で確認できます。
- homeをクリック
- [
モデル]タブをクリック
モデル名(❶)をクリックすると、そのモデルの更に詳細な情報が確認できます。

トレーニングが成功で終わると、ステータスが「モデル作成完了」と表示されます。
DataEditorで予測しよう
ここでは、分割した予測用のデータ(電力の需要予測の基礎データ_test)を使って予測します。
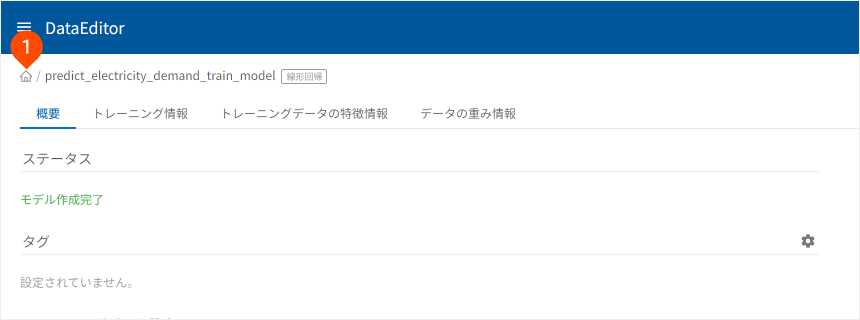
- 「
」をクリック

- 「
電力の需要予測の基礎データ_test」をクリック
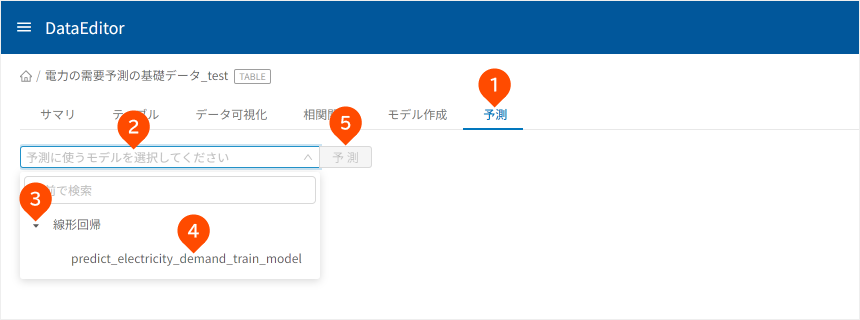
- 「
予測」タブをクリック - 「
予測に使うモデルを選択してください」をクリック - 「
線形回帰」左横の「」をクリック - 「
predict_electricity_demand_train_model」をクリック - [
予測]ボタンをクリック
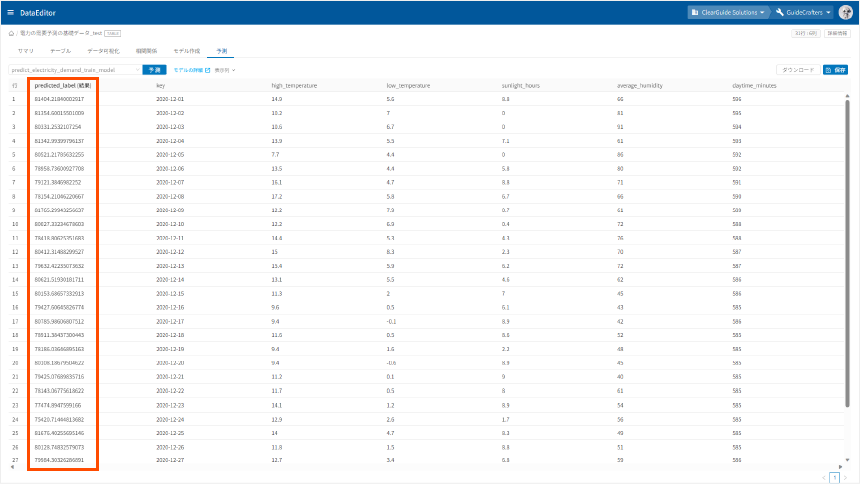
「predicted_label(結果)」列が予測結果です。
操作中にエラーとなったら
DataEditorのモデル作成時のエラー内容は、モデル詳細画面の「エラーログ」で確認できます。以下に、そのエラー内容の確認方法を紹介します。
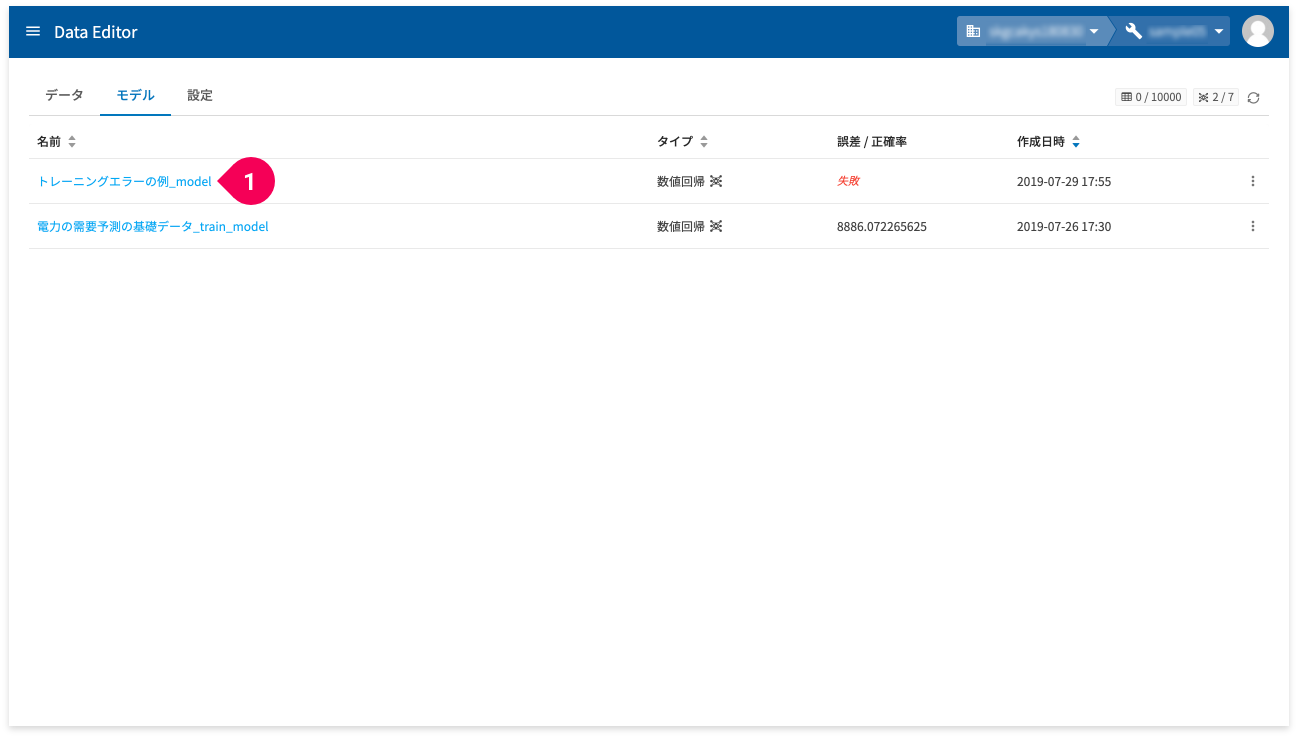
- モデル一覧の[
誤差/正確率]の欄が[失敗]と表示されている名前をクリック
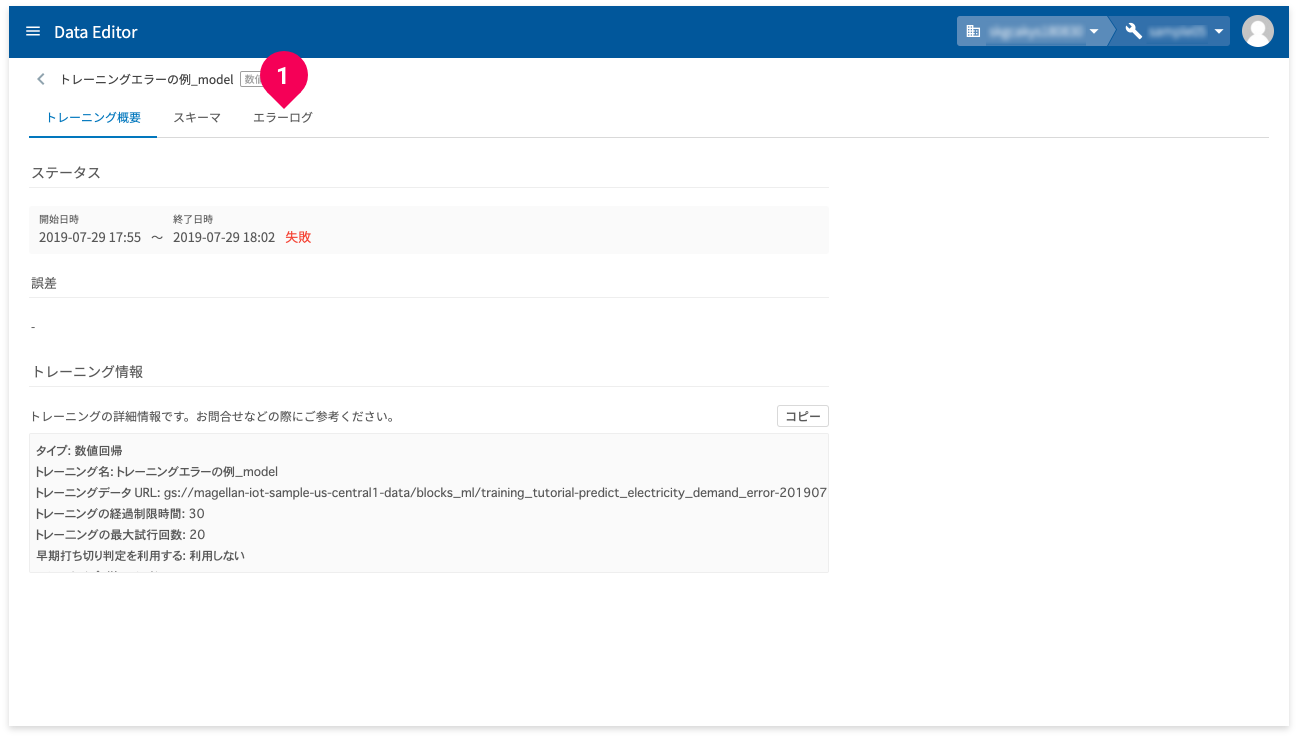
- [
エラーログ]をクリック
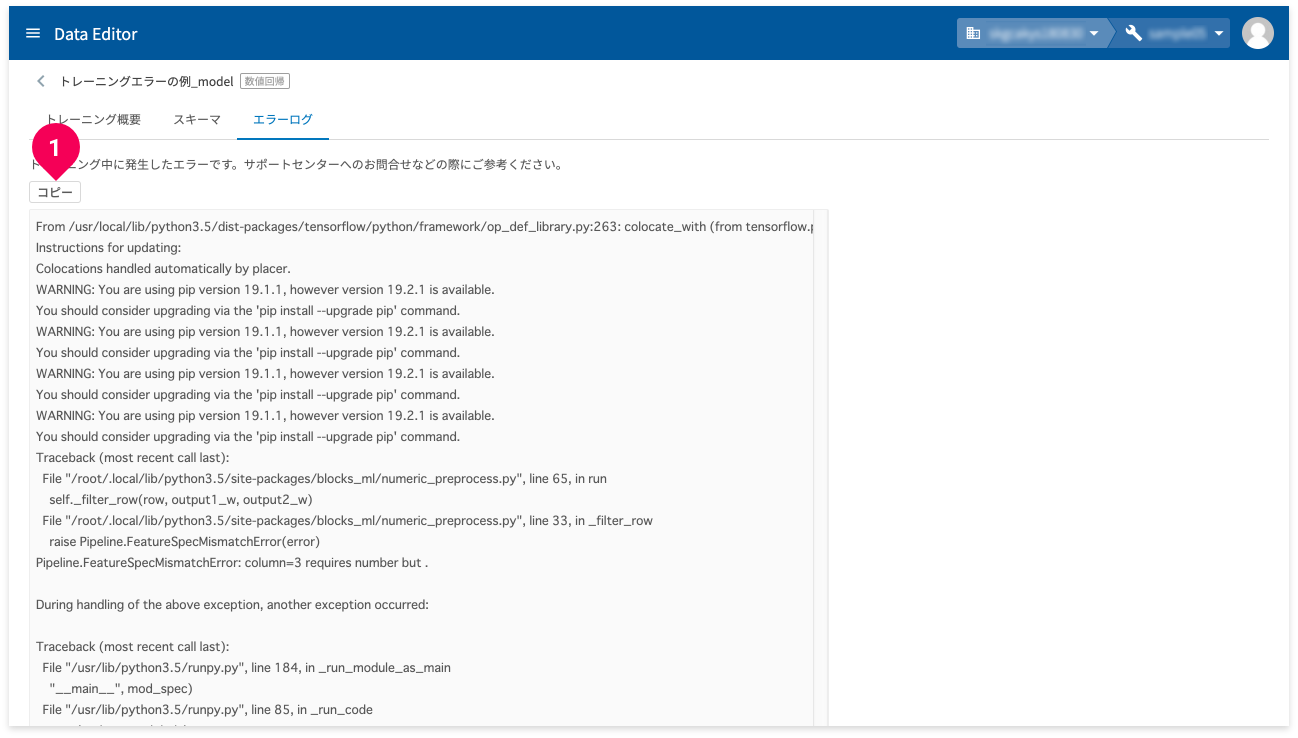
- [
コピー]ボタンをクリック
エラーの内容がクリップボードにコピーされます。
参考
お問い合わせについて詳しくは、基本操作ガイドの「お問い合わせ」を参考にしてください。
まとめ
このようにBLOCKSを使うと、データを準備するだけで、機械学習の専門的な知識は必要なく簡単に数値回帰が利用できます。ただし、データの準備に際し、留意点があります。準備するカンマ(,)区切りのCSVファイルは、BOMなし・UTF-8にしてください。これ以外だと、BLOCKSで扱うことができません。
参考
BOMなし・UTF-8について詳しくは、弊社ブログの「MAGELLAN BLOCKSを利用する上で文字コードのお話し」を参考にしてください。
なお、トレーニングの精度について評価はしませんでしたが、因子を見直すことで改善の余地はあると思われます。
例えば、企業が休みの休日は電力使用量が平日よりも少なくなる可能性があります。また、季節によっても電力使用量の度合いは異なってくるでしょう。これらのことから、月や曜日を因子として追加することで、トレーニングの精度はより良くなる可能性があると思われます。
今回のチュートリアルの応用課題として、データの準備段階でこれらの因子を追加して試してみてはいかがでしょうか。
重要
機械学習を使ってビジネスの課題を解決するには、チュートリアル同様にまずデータ収集から始めます。社内にある既存のデータを集めたり、新たにアンケートを採ってデータを集めたり、データを購入することもあります。更にそれらデータを精査し、データを選別したり、不正なデータを除去するなどのデータ加工の作業も必要です。このデータ収集と加工作業が、機械学習のステップの大半を占めると言っても過言ではありません。