モデルジェネレーター予測(オンライン)ブロックを使ったいろいろな予測の方法
モデルジェネレーター予測(オンライン)ブロックを使ったいろいろな予測の方法
「モデルジェネレーター予測(オンライン)」ブロックを使った予測の方法には、「モデルジェネレーターの使い方」(数値分類/数値回帰)で解説している「オブジェクト生成」ブロックを使用する方法以外にもいくつかあります。
ここでは、以下の方法について、解説します。いずれの方法も「モデルジェネレーターの使い方(数値分類タイプ)」の「予測」を例に解説します。
- 予測因子データをファイルから与える方法
- 予測因子データをBigQueryから与える方法
- 予測因子データをフローの外部実行時に与える方法(application/json)
- 予測因子データをフローの外部実行時に与える方法(x-www-form-urlencoded)
info_outline解説の例で使用している名前(ファイル名・バケット名・データセット名・テーブル名など)は、あくまでも例です。自由に名前を付け変えて構いません。ただし、予測因子データの項目名(key含む)だけは、例のままとしてください。
予測因子データをファイルから与える方法
予測因子データをYAML形式かJSON形式のテキストファイルで準備して、それを使って予測する方法です。
「モデルジェネレーター予測(オンライン)」ブロックで予測するためには、予測因子データを変数に設定する必要があります(データは所定の形式で構造化されている必要あり)。
「GCSから変数へロード」ブロック(「GCP」カテゴリー)を使用すると、Google Cloud Storageopen_in_new(GCS)上にあるファイル内容を変数に設定できます。ファイル形式がYAMLかJSONの場合は、その内容を解析し構造化されたデータを変数に設定します。
このため、予測因子データのファイルをGCS上に準備すれば、「GCSから変数へロード」ブロックと「モデルジェネレーター予測(オンライン)」ブロックを組み合わせて予測ができます。ファイルは、「モデルジェネレーター予測(オンライン)」ブロックが期待する形式の構造化されたデータをYAMLかJSONの形式で準備します。

この例では、予測因子データをJSON形式のテキストファイルで準備し予測します。
まず、以下のJSON形式のテキストファイルをiris_predict_data.jsonというファイル名で作成し、GCS(バケット名:magellan-sample)へアップロードしておきます。
{
"data": [
{
"key": "1",
"sepal_length": 5.9,
"sepal_width": 3.0,
"petal_length": 4.2,
"petal_width": 1.5
},
{
"key": "2",
"sepal_length": 6.9,
"sepal_width": 3.1,
"petal_length": 5.4,
"petal_width": 2.1
},
{
"key": "3",
"sepal_length": 5.1,
"sepal_width": 3.3,
"petal_length": 1.7,
"petal_width": 0.5
}
]
}
フローデザイナーのフローは、下図のように作成します。
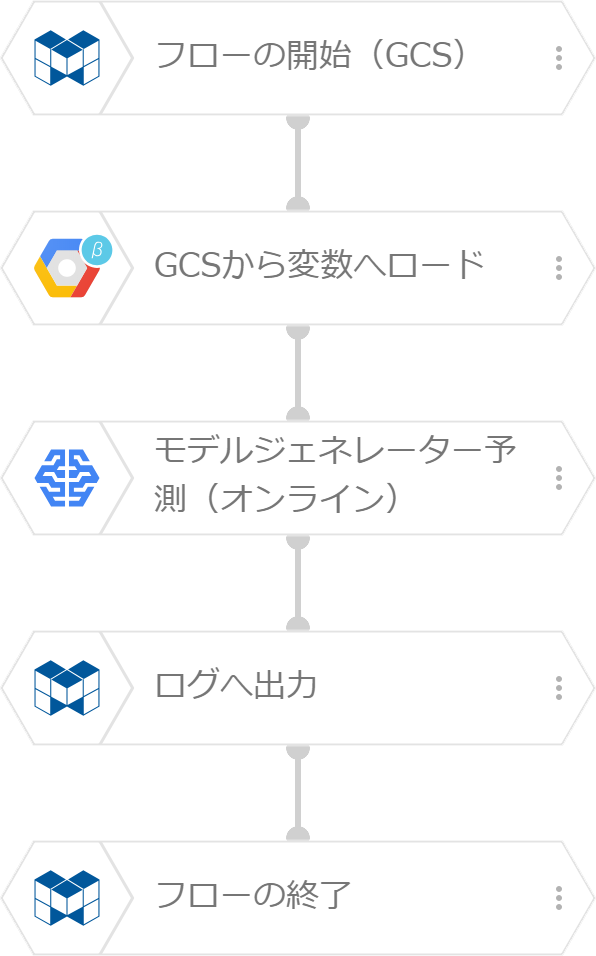
「GCSから変数へロード」ブロックで予測因子データのテキストファイルを読み込み、「モデルジェネレーター予測(オンライン)」ブロックで予測します。この例では、予測結果を「ログへ出力」ブロックでログへ出力し予測結果を確認します。
各ブロックのプロパティ設定は、以下のとおりです(初期値から変更が必要なプロパティおよび重要なプロパティのみ)。
| ブロック | プロパティ | 値 |
|---|---|---|
| GCSから変数へロード | 読込データのファイルGCS URL | gs://magellan-sample/iris_predict_data.json |
| ファイル形式 | JSON | |
| 結果を格納する変数 | _ |
|
| モデルジェネレーター予測(オンライン) | モデル | 予測で使用するモデル |
| 予測因子データの変数 | _.content.data |
|
| 予測結果変数 |
info_outlineここでは、便宜上、予測因子データを格納している変数 |
|
| ログへ出力 | ログへ出力する変数 | _ |
これで準備ができました。フローデザイナーの保存後、「フローの開始」ブロックプロパティのplay_circle_outlineボタンをクリックして、フローを実行します。
以下は、フローのログ出力結果です(抜粋)。
{
"predictions": [
{
"score": [
0.017455093562602997,
0.7145982980728149,
0.26794660091400146
],
"key": "1",
"label": 1
},
{
"score": [
0.0007236730307340622,
0.40548425912857056,
0.5937920212745667
],
"key": "2",
"label": 2
},
{
"score": [
0.9445222616195679,
0.05332513898611069,
0.0021526541095227003
],
"key": "3",
"label": 0
}
]
}
予測因子データをBigQueryから与える方法
予測因子データをBigQueryのテーブルに準備して、それを使って予測する方法です。
先ほど述べたとおり、「モデルジェネレーター予測(オンライン)」ブロックで予測するためには、予測因子データを変数に設定する必要があります(データは所定の形式で構造化されている必要あり)。
「クエリーの実行」ブロックを使用すると、BigQueryから取得し、構造化されたデータを変数に設定できます。
このため、BigQueryに予測因子データを準備すれば、「クエリーの実行」ブロックと「モデルジェネレーター予測(オンライン)」ブロックを組み合わせて予測ができます。

以下のデータをBigQueryに準備します。
| 項目 | 内容 |
|---|---|
| データセット名 | samples |
| テーブル名 | iris_predict_data |
| 名前 | 型 | モード |
|---|---|---|
| key | STRING | NULLABLE |
| sepal_length | FLOAT | NULLABLE |
| sepal_width | FLOAT | NULLABLE |
| petal_length | FLOAT | NULLABLE |
| petal_width | FLOAT | NULLABLE |
| key | sepal_length | sepal_width | petal_length | petal_width |
|---|---|---|---|---|
| 1 | 5.9 | 3.0 | 4.2 | 1.5 |
| 2 | 6.9 | 3.1 | 5.4 | 2.1 |
| 3 | 5.1 | 3.3 | 1.7 | 0.5 |
フローデザイナーのフローは、下図のように作成します。
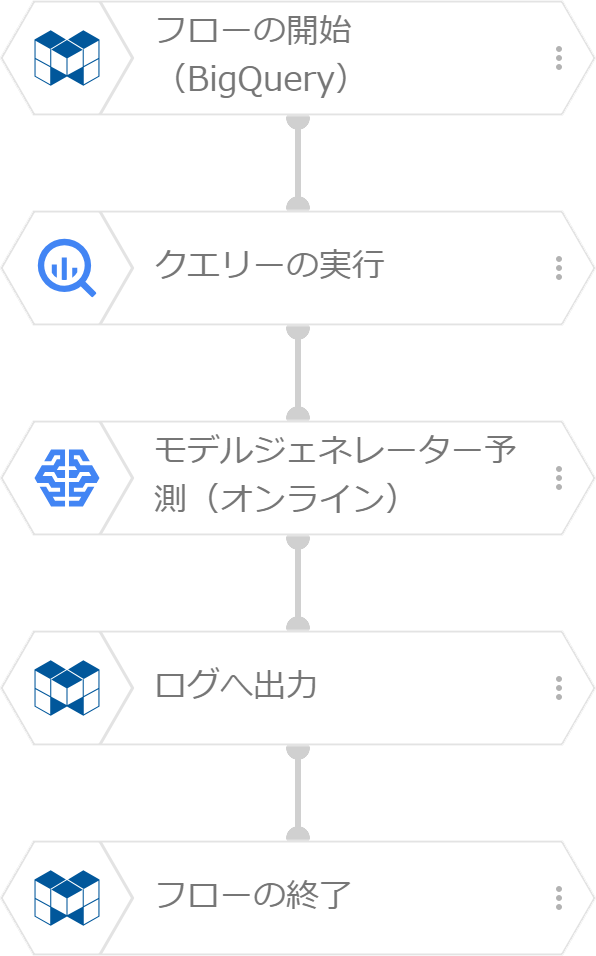
「クエリーの実行」ブロックでBigQueryから予測因子データを取り出し、「モデルジェネレーター予測(オンライン)」ブロックで予測します。この例では、予測結果を「ログへ出力」ブロックでログへ出力し予測結果を確認します。
各ブロックのプロパティ設定は、以下のとおりです(初期値から変更が必要なプロパティおよび重要なプロパティのみ)。
| ブロック | プロパティ | 値 |
|---|---|---|
| クエリーの実行 | SQL文法 | Legacy SQL |
| クエリー |
SELECT key, sepal_length, sepal_width, petal_length,
petal_width FROM samples.iris_predict_data
|
|
| 結果を格納する変数 | _ |
|
| モデルジェネレーター予測(オンライン) | モデル | 予測で使用するモデル |
| 予測因子データの変数 | _ |
|
| 予測結果変数 |
info_outlineここでは、便宜上、予測因子データを格納している変数 |
|
| ログへ出力 | ログへ出力する変数 | _ |
これで準備ができました。フローデザイナーの保存後、「フローの開始」ブロックプロパティのplay_circle_outlineボタンをクリックして、フローを実行します。
以下は、フローのログ出力結果です(抜粋)。
{
"predictions": [
{
"score": [
0.017455093562602997,
0.7145982980728149,
0.26794660091400146
],
"key": "1",
"label": 1
},
{
"score": [
0.0007236730307340622,
0.40548425912857056,
0.5937920212745667
],
"key": "2",
"label": 2
},
{
"score": [
0.9445222616195679,
0.05332513898611069,
0.0021526541095227003
],
"key": "3",
"label": 0
}
]
}
予測因子データをフローの外部実行時に与える方法(application/json)
予測因子データをフローの外部実行時に与えて、予測する方法です。
フローの外部実行とは、Web APIでフローを実行する方法です。ここで紹介する方法は、HTTPリクエストのContent-Typeヘッダーにapplication/jsonと指定して、予測因子データを渡す方法です。
フローの外部実行では、JSONテキストで表現したデータを渡して、BLOCKSの変数にさまざまな値を設定できます。
フローの外部実行時のContent-Typeヘッダーをapplication/jsonとして、HTTPリクエストのボディに以下のようなJSONテキストデータを指定すると、変数varに数値の100が設定できます。
{"var": 100}
以下は、変数_に予測因子データを設定するJSONテキストの例です。
{
"_": [
{
"key": "1",
"sepal_length": 5.9,
"sepal_width": 3.0,
"petal_length": 4.2,
"petal_width": 1.5
},
{
"key": "2",
"sepal_length": 6.9,
"sepal_width": 3.1,
"petal_length": 5.4,
"petal_width": 2.1
},
{
"key": "3",
"sepal_length": 5.1,
"sepal_width": 3.3,
"petal_length": 1.7,
"petal_width": 0.5
}
]
}
このときのフローデザイナーのフローは、下図のように作成します。
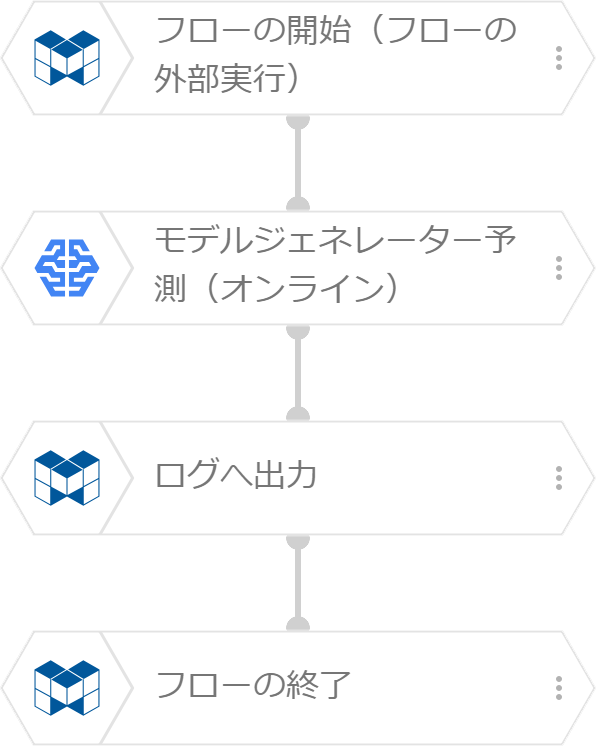
フローは至ってシンプルです。「モデルジェネレーター予測(オンライン)」ブロックで予測するだけです。この例では、予測結果を「ログへ出力」ブロックでログへ出力して、予測結果を確認します。
各ブロックのプロパティ設定は、以下のとおりです(初期値から変更が必要なプロパティおよび重要なプロパティのみ)。
| ブロック | プロパティ | 値 |
|---|---|---|
| フローの開始 | ID | predict_iris |
| モデルジェネレーター予測(オンライン) | モデル | 予測で使用するモデル |
| 予測因子データの変数 | _ |
|
| 予測結果変数 |
予測因子データを格納している変数 |
|
| ログへ出力 | ログへ出力する変数 | _ |
以下は、Unix系curlコマンドでの実行例です。
curl -H 'Authorization: Bearer 951***a16' \
-H 'Content-Type: application/json' \
--data '{"_": [{"key": "1", "sepal_length": 5.9, "sepal_width": 3.0, "petal_length": 4.2, "petal_width": 1.5}, {"key": "2", "sepal_length": 6.9, "sepal_width": 3.1, "petal_length": 5.4, "petal_width": 2.1}, {"key": "3", "sepal_length": 5.1, "sepal_width": 3.3, "petal_length": 1.7, "petal_width": 0.5}]}' \
https://***.magellanic-clouds.net/flows/predict_iris.json
フローの実行に成功すると、以下のようなレスポンスが返ってきます。"job_id"の1の部分は、フローを実行するごとに変わります。この例と異なっていても問題ありません。
{"result":true,"job_id":1}
以下は、フローのログ出力結果です(抜粋)。
{
"predictions": [
{
"score": [
0.017606934532523155,
0.9281915426254272,
0.05420156940817833
],
"key": "1",
"label": 1
},
{
"score": [
0.0002792126906570047,
0.2558387219905853,
0.7438820004463196
],
"key": "2",
"label": 2
},
{
"score": [
0.9730234146118164,
0.026976602151989937,
6.675784813836572e-09
],
"key": "3",
"label": 0
}
]
}
予測因子データをフローの外部実行時に与える方法(x-www-form-urlencoded)
予測因子データをフローの外部実行時に与えて、予測する方法です。
フローの外部実行とは、Web APIでフローを実行する方法です。ここで紹介する方法は、HTTPリクエストのContent-Typeヘッダーにx-www-form-urlencodedと指定して、予測因子データを渡す方法です。
フローの外部実行時のパラメーターは、フロー内でパラメーター名と同名の変数名で参照できます。また、「オブジェクト生成」ブロックでは、変数を使ってデータの生成ができます。
「オブジェクト生成」ブロックのデータプロパティで以下のように設定したとします。
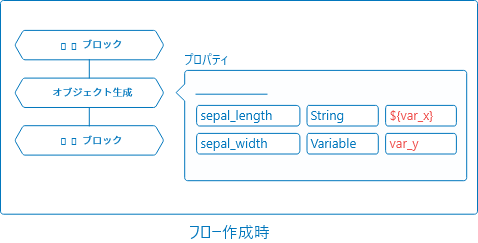
このとき、フローの外部実行時に、var_x=5.9とvar_y=3.0というパラメーターを与えたとすると、以下のように変化します。
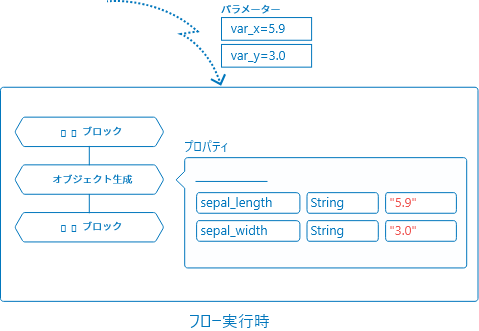
-
${var_x}の部分は、パラメーター名var_xの値"5.9"になります。 -
var_yの部分は、パラメーター名var_yの値"3.0"になります。
VariableはString扱いになります。
info_outlineパラメーターの値は、すべて文字列として扱われます。
このように、パラメーターを使った変数の参照を使うと、フローの実行ごとに生成するデータを変えられます。
予測因子データには、文字列以外にも数値を期待する型(数値型・月・曜日)がありますが、そこに数値を文字列にしたデータ("5.9"や"0"など)を与えても問題ありません。
「モデルジェネレーター予測(オンライン)」ブロックでは、数値が期待される項目に、文字列のデータがあると数値に変換してくれます。もちろん、"one"や"abc"などの明らかに数値に変換できない文字列があると予測が失敗します。
フローデザイナーのフローは、下図のように作成します。
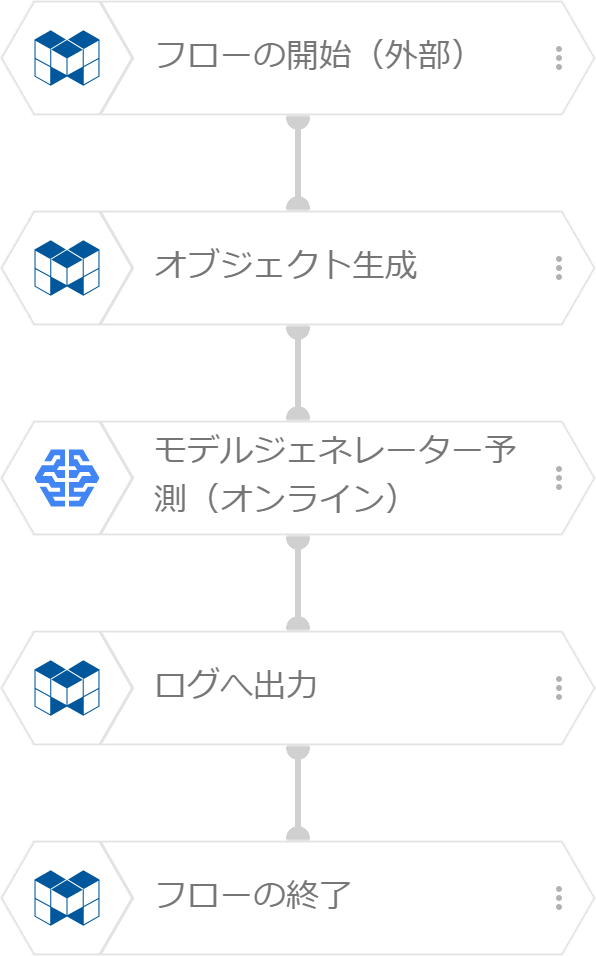
「オブジェクト生成」ブロックで、フローの外部実行時のパラメーターを使って予測データを生成します。この生成されたデータを使って「モデルジェネレーター予測(オンライン)」ブロックで予測します。この例では、予測結果を「ログへ出力」ブロックでログへ出力し予測結果を確認します。
各ブロックのプロパティ設定は、以下のとおりです(初期値から変更が必要なプロパティおよび重要なプロパティのみ)。
| ブロック | プロパティ | 値 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| フローの開始 | ID | predict_iris | |||||||||||||||||
| オブジェクト生成 | 結果を格納する変数 | _ |
|||||||||||||||||
| データ |
値は、変数展開を使って、パラメーター値を設定します。この例では、予測因子データとパラメーターの対応をわかりやすくするために、予測因子データの項目名(キー)とパラメーター名を合わせています。 |
||||||||||||||||||
| モデルジェネレーター予測(オンライン) | モデル | 予測で使用するモデル | |||||||||||||||||
| 予測因子データの変数 | _ |
||||||||||||||||||
| 予測結果変数 |
info予測因子データを格納している変数 |
||||||||||||||||||
| ログへ出力 | ログへ出力する変数 | _ |
以下は、Unix系curlコマンドでの実行例です(--data "xxx=#"の部分が予測因子データ用のパラメーター)。
curl -H "Authorization: Bearer 951***a16" \ --data "key=1" \ --data "sepal_length=5.9" \ --data "sepal_width=3.0" \ --data "petal_length=4.2" \ --data "petal_width=1.5" \ https://***.magellanic-clouds.net/flows/predict_iris.json
フローの実行に成功すると、以下のようなレスポンスが返ってきます。"job_id"の1の部分は、フローを実行するごとに変わります。この例と異なっていても問題ありません。
{"result":true,"job_id":1}
以下は、フローのログ出力結果です(抜粋)。
{
"predictions": [
{
"score": [
0.017455093562602997,
0.7145982980728149,
0.26794660091400146
],
"key": "1",
"label": 1
}
]
}