音声認識ブロックの使い方
音声認識ブロックの使い方
このドキュメントでは、PCで録音した音声データを使って、音声認識ブロックの使い方を解説します。
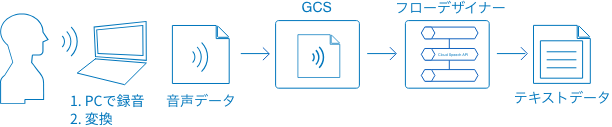
今回、音声データはサンプルを準備しました。音声データの作成方法(PCで録音して変換)については、「付録」にまとめています。ご自身で試すときの参考にしてください。
目次
準備
すぐ試せるように、音声データとフローデザイナーのフローをエクスポートしたデータを準備しました。以下のそれぞれの説明に沿って自身の環境に準備してください。
| データ | 説明 |
|---|---|
| サンプル音声データ |
音声データは、以下の文章を読み上げたものを準備しました。 機械学習や人工知能に関して、様々なサービスが発表されていますが、ビジネスで使おうとするとどれも「高価」で「難しい」ものばかりです。機械学習の専門家が機械学習を使うのではなく、ビジネスの専門家が機械学習を使えなければなりません。だからこそ、MAGELLAN BLOCKSは、誰もが気軽に機械学習を使えるよう、簡単かつリーズナブルな価格で提供しています。
|
| サンプルフロー |
サンプルフローは、音声認識ブロックを使用した最もシンプルなフローと、BigQueryを活用したフローの2種類を準備しました。
|
解説
ひとつ目のフローは、音声認識ブロックを使った音声認識の最もシンプルな例です。
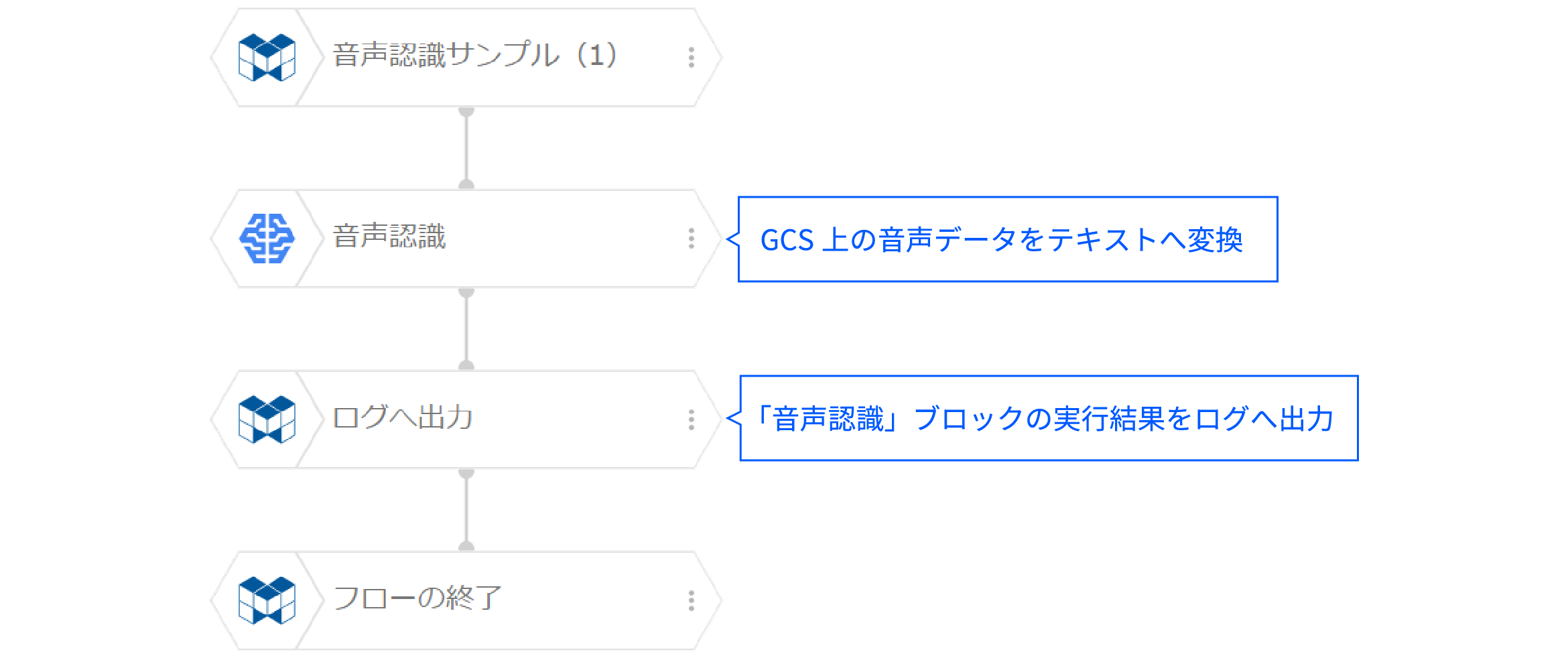
このように「機械学習」カテゴリーの「音声認識」ブロックを配置するだけで、GCS上にアップロードされた音声データを読み取り、テキストデータに変換できます。
以下に、各ブロックのプロパティの設定値を示します(初期値と異なる設定と重要なプロパティのみ)。提供のサンプルフローでは、「ブロックメモ」プロパティに各ブロックの動作説明を記載していますが、ここでは省略します。
| ブロック (カテゴリー) |
プロパティ | 値 |
|---|---|---|
| フローの開始 (基本) |
ブロック名 |
音声認識サンプル(1) もうひとつのフローと区別するため、ブロック名を変更しています。 |
| 音声認識 (機械学習) |
GCPサービスアカウント | 複数のGCPサービスアカウントがある場合は、適切なGCPサービスアカウントを選択 |
| 音声データのGCS上のURL |
gs://my-bucket/speech_api_sample_voice_ja.flac my-bucketの部分は、音声データをアップロードしたバケットのバケット名に置き換えてください。 |
|
| 結果を格納する変数 | _ | |
| 音声データのエンコーディング | FLAC | |
| 音声データのサンプルレート | 16000 | |
| 音声データの言語コード | 日本語(日本) | |
| ログへ出力 (基本) |
ログへ出力する変数 | _ |
このフローを実行するには、フローの開始ブロック(ブロック名: 音声認識サンプル(1))のプロパティ内にある「」ボタンをクリックします。
実行が成功するとログに以下のような内容が出力されます。
{
"results": [
{
"alternatives": [
{
"transcript": "機械学習や人工知能に関して様々なサービスが発表されていますがビジネスで使おうとするとどれも効果で難しいものばかりです機械学習の専門家が機械学習を使うのではなくビジネスの専門家が機械学習を使えなければなりませんだからこそマゼランブロックスは誰もが気軽に機械学習を使えるよう簡単かつリーズナブルな価格で提供しています",
"confidence": 0.95264834
}
],
"resultEndTime": "35.160s",
"languageCode": "ja-jp"
}
],
"gcs_url": "gs://my-bucket/speech_api_sample_voice_ja.flac",
"timestamp": 1661488590.238585
}
「"transcript": "機械学習や. . . (中略) . . .提供しています"」の部分が音声データの変換結果です。
「"confidence": 0.95264834」の部分が変換したテキストデータの信頼度を表す数値です。0.0から1.0の範囲で表します。数値の大きさが、信頼度の高さを表します。
この変換結果では、約96%の信頼度ということで、確かに正しく認識できていない部分(赤字の部分)があります。
「音声認識」ブロックの「音声認識のヒントとなる単語やフレーズ」プロパティに単語やフレーズを指定すると、分野特有の用語やあまり使われない単語を変換するように音声認識をカスタマイズできます。これにより、特定の単語やフレーズの変換精度を向上させられます。
ふたつ目のフローでは、音声の認識精度を高める設定をし、応用例として音声認識の結果をBigQueryに蓄積する例としました。
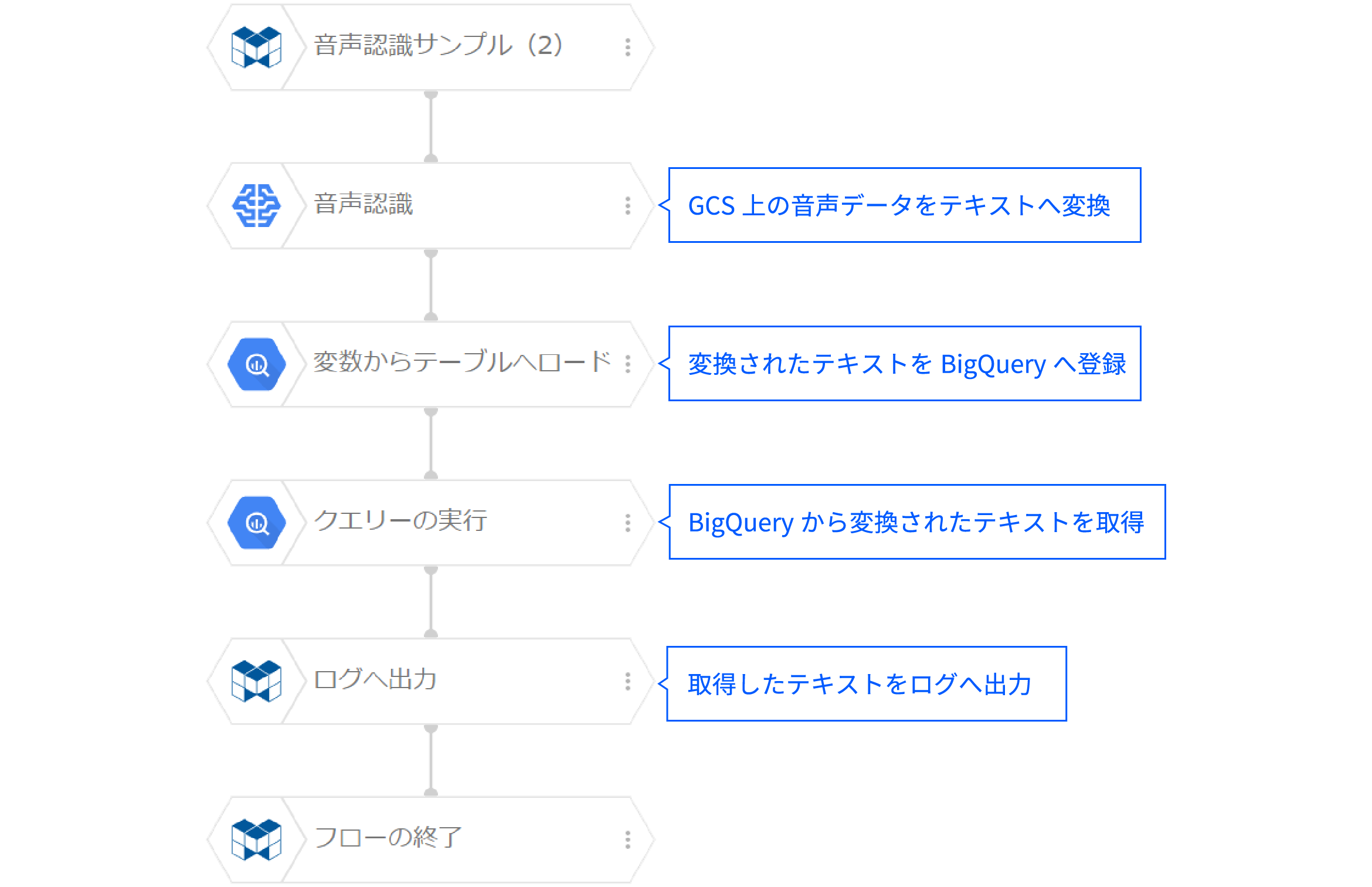
以下に、各ブロックのプロパティの設定値を示します(初期値と異なる設定と重要なプロパティのみ)。提供のサンプルフローでは、「ブロックメモ」プロパティに各ブロックの動作説明を記載していますが、ここでは省略します。
| ブロック (カテゴリー) |
プロパティ | 値 | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| フローの開始 (基本) |
ブロック名 |
音声認識サンプル(2) もうひとつのフローと区別するため、ブロック名を変更しています。 |
||||||||||||||||||||||||||
| 音声認識 (機械学習) |
GCPサービスアカウント | 複数のGCPサービスアカウントがある場合は、適切なGCPサービスアカウントを選択 | ||||||||||||||||||||||||||
| 音声データのGCS上のURL |
gs://my-bucket/speech_api_sample_voice_ja.flac my-bucketの部分は、音声データをアップロードしたバケットのバケット名に置き換えてください。 |
|||||||||||||||||||||||||||
| 結果を格納する変数 | _ | |||||||||||||||||||||||||||
| 音声データのエンコーディング | FLAC | |||||||||||||||||||||||||||
| 音声データのサンプルレート | 16000 | |||||||||||||||||||||||||||
| 音声データの言語コード | 日本語(日本) | |||||||||||||||||||||||||||
| 最大変換候補数 |
3 今回は、BigQueryに結果を記録するため、後で比較検討できるように最大で3つの変換候補を得るようにしています。 |
|||||||||||||||||||||||||||
| 音声認識のヒントとなる単語やフレーズ |
この設定によって、以下のように改善することを期待しています。
|
|||||||||||||||||||||||||||
| 変数からテーブルへロード (BigQuery) |
GCPサービスアカウント | 複数のGCPサービスアカウントがある場合は、適切なGCPサービスアカウントを選択 | ||||||||||||||||||||||||||
| 投入データの変数 | _ | |||||||||||||||||||||||||||
| 投入先のデータセット |
blocks_samples この名称は変えても支障ありません。 |
|||||||||||||||||||||||||||
| 投入先のテーブル |
speech_api この名称は変えても支障ありません。 |
|||||||||||||||||||||||||||
| スキーマ設定 |
スキーマの設定は、スキーマ設定プロパティの「JSONで編集」リンクをクリックして、以下のコードを貼り付けると簡単です。
[
{
"name": "results",
"type": "RECORD",
"mode": "REPEATED",
"description": "",
"fields": [
{
"name": "alternatives",
"type": "RECORD",
"mode": "REPEATED",
"description": "",
"fields": [
{
"name": "transcript",
"type": "STRING",
"mode": "NULLABLE",
"description": ""
},
{
"name": "confidence",
"type": "FLOAT",
"mode": "NULLABLE",
"description": ""
}
]
},
{
"name": "resultEndTime",
"type": "STRING",
"mode": "NULLABLE",
"description": ""
},
{
"name": "languageCode",
"type": "STRING",
"mode": "NULLABLE",
"description": ""
}
]
},
{
"name": "gcs_url",
"type": "STRING",
"mode": "NULLABLE",
"description": ""
},
{
"name": "timestamp",
"type": "TIMESTAMP",
"mode": "NULLABLE",
"description": ""
}
]
|
|||||||||||||||||||||||||||
| 空でないテーブルが存在したとき |
上書き この例では、フローを実行するたびに音声認識の結果を上書きしています。音声認識の結果を蓄積させたい場合は、「追加」を選択します。 |
|||||||||||||||||||||||||||
| クエリーの実行 (BigQuery) |
GCPサービスアカウント | 複数のGCPサービスアカウントがある場合は、適切なGCPサービスアカウントを選択 | ||||||||||||||||||||||||||
| SQL文法 | Legacy SQL | |||||||||||||||||||||||||||
| クエリー |
SELECT
results.alternatives.transcript as transcript
FROM
[blocks_samples.speech_api]
WHERE
results.alternatives.confidence > 0
ORDER BY
timestamp desc
LIMIT
1
4行目のblocks_samplesおよびspeech_apiの部分は、それぞれ「変数からテーブルへロード」ブロックの「投入先のデータセット」プロパティおよび「投入先のテーブル」プロパティの値と合わせてください。 |
|||||||||||||||||||||||||||
| 結果格納先のデータセット | (空欄) | |||||||||||||||||||||||||||
| 結果格納先のテーブル | (空欄) | |||||||||||||||||||||||||||
| 結果を格納する変数 |
(空欄) 「結果格納先のデータセット」プロパティ・「結果格納先のテーブル」プロパティ・「結果を格納する変数」プロパティすべてを空欄(初期値)にすると、クエリーの実行結果は、変数_に格納されます。 |
|||||||||||||||||||||||||||
| ログへ出力 (基本) |
ログへ出力する変数 | _ |
このフローを実行するには、フローの開始ブロック(ブロック名: 音声認識サンプル(2))のプロパティ内にある「」ボタンをクリックします。
実行が成功するとログに以下のような内容が出力されます。
[
{
"transcript": "機械学習や人工知能に関して様々なサービスが発表されていますがビジネスで使おうとするとどれも高価で難しいものばかりです機械学習の専門家が機械学習を使うのではなくビジネスの専門家が機械学習を使えなければなりませんだからこそmagellan blocksは誰もが気軽に機械学習を使えるよう簡単かつリーズナブルな価格で提供しています"
}
]
先ほどと同様に、「"transcript": "機械学習や. . . (中略) . . .提供しています"」の部分が音声データの変換結果です。「音声認識」ブロックの「音声認識のヒントとなる単語やフレーズ」を設定することで、音声認識の結果が変わりました(青字の部分)。
付録
今回用意したサンプル音声データの作成方法を簡単に紹介します。ご自身で音声データを準備して試す場合の参考にしてください。
音声録音は、WindowsやmacOS (OS X)の標準アプリでできますが、音声認識ブロックがサポートする音声データの形式ではないため、そのままでは使えません。別途、専用のアプリをインストールして、音声認識ブロックがサポートする音声データ形式に変換する必要があります。
ここでは、Audacityというアプリをインストールして、音声録音する方法を紹介します。Audacityは、デジタルオーディオの編集および録音ができるオープンソースソフトウエアで、音声認識がサポートするFLAC形式の音声データの出力が可能です。
Audacityのインストール方法とAudacityを使った音声録音の方法について、順を追って解説します。
Audacityのインストール
Windows 10の場合
- Audacityのウェブサイトを開きます。
- 「Download Audacity 2.1.3」のリンクをクリックします。
「2.1.3」は、Audacityのバージョン番号です。バージョン番号は、2017年6月1日時点の情報で記載しているため、異なる可能性があります。異なっている場合は、最新のバージョン番号で読み替えてください。
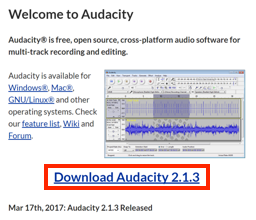
- ダウンロードページが表示されます。ページ内の「Audacity for Windows」のリンクをクリックします。
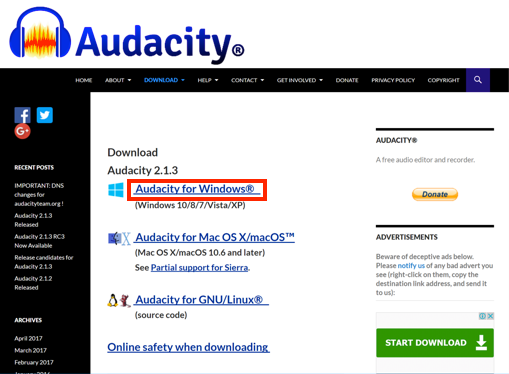
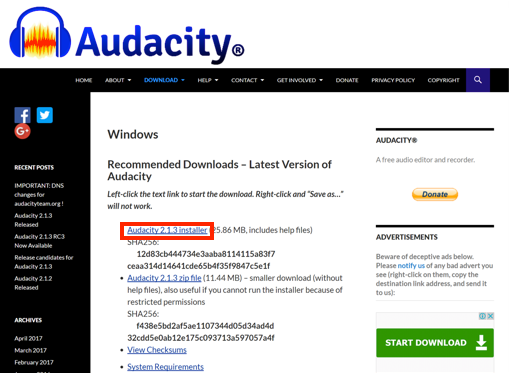
- Windows版Audacityのダウンロードページが表示されます。ページ内の「Audacity 2.1.3 installer」のリンクをクリックして、Audacityのインストーラをダウンロードします。
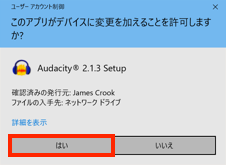
- ダウンロードした「audacity-win-2.1.3.exe」ファイルを実行します。

- Audacityのインストール許可を訪ねてきます。「はい」ボタンをクリックします。
- インストール中に利用する言語を選択して、「OK」ボタンをクリックします。
- 「Audacityセットアップウィザードの開始」が表示されます。「次へ(N) >」ボタンをクリックします。
- 重要な情報が表示されます。「次へ(N) >」ボタンをクリックします。
- Audacityをインストールするフォルダーを指定して、「次へ(N) >」ボタンをクリックします。
- 追加タスクの選択が表示されます。「次へ(N) >」ボタンをクリックします。
デスクトップ上にアイコンを作成したくない場合は、「デスクトップ上にアイコンを作成する(D)」のチェックを外します。
- インストール準備完了が表示されます。「インストール(I)」ボタンをクリックすると、Audacityのインストール始まります。
- Audacityのインストールが完了すると、重要な情報が表示されます。「次へ(N) >」ボタンをクリックします。
- 「Audacityセットアップウィザードの完了」が表示されます。「完了(F)」ボタンをクリックするとインストールの完了です。
デフォルトでは、「Audacityを実行する」のチェックが付いているので、「完了(F)」ボタンをクリックすると、Audacityが起動します。
macOS / OS Xの場合
- Audacityのウェブサイトを開きます。
- 「Download Audacity 2.1.3」のリンクをクリックします。
「2.1.3」は、Audacityのバージョン番号です。バージョン番号は、2017年6月1日時点の情報で記載しているため、異なる可能性があります。異なっている場合は、最新のバージョン番号で読み替えてください。
- ダウンロードページが表示されます。ページ内の「Audacity for Mac OS X/macOS」のリンクをクリックします。
- macOS (OS X)版Audacityのダウンロードページが表示されます。ページ内の「Audacity 2.1.3 .dmg file」のリンクをクリックして、Audacityをダウンロードします。
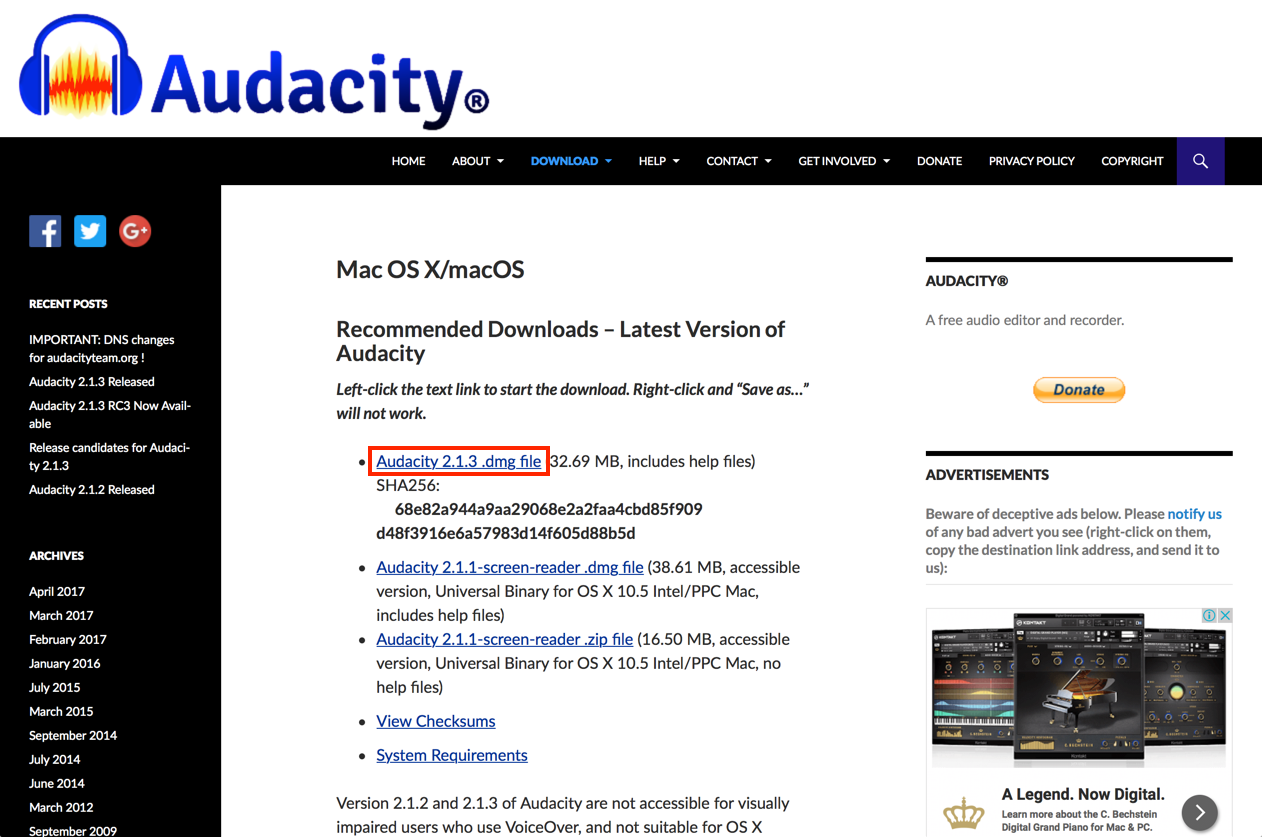
- ダウンロードした「audacity-macos-2.1.3.dmg」ファイルをFinderからダブルクリックして開きます。

- 画面内でAudacityアイコンをApplicationsフォルダーへドラッグ&ドロップします。

- 上記ウィンドウを閉じます。
- デスクトップのAudacity 2.1.3のアイコンをマウスの右ボタンクリックして、表示されるメニューから「"Audacity 2.1.3"を取り出す」をクリックします。
これでインストールの完了です。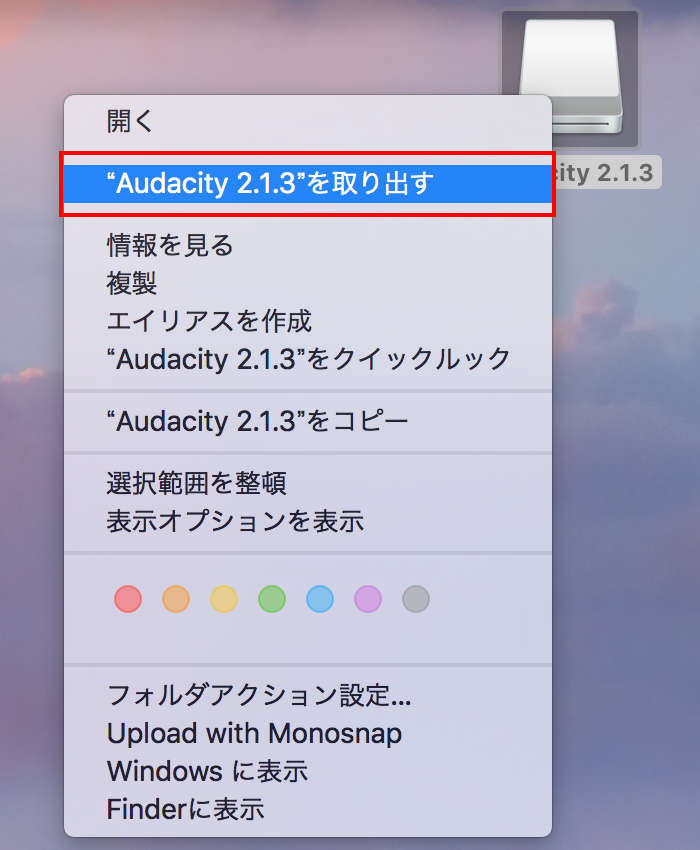
Audacityを使った音声録音
Audacityの画面は、いくつかのパーツで構成されています。音声録音に必要なパーツとその名称は、下図のとおりです。
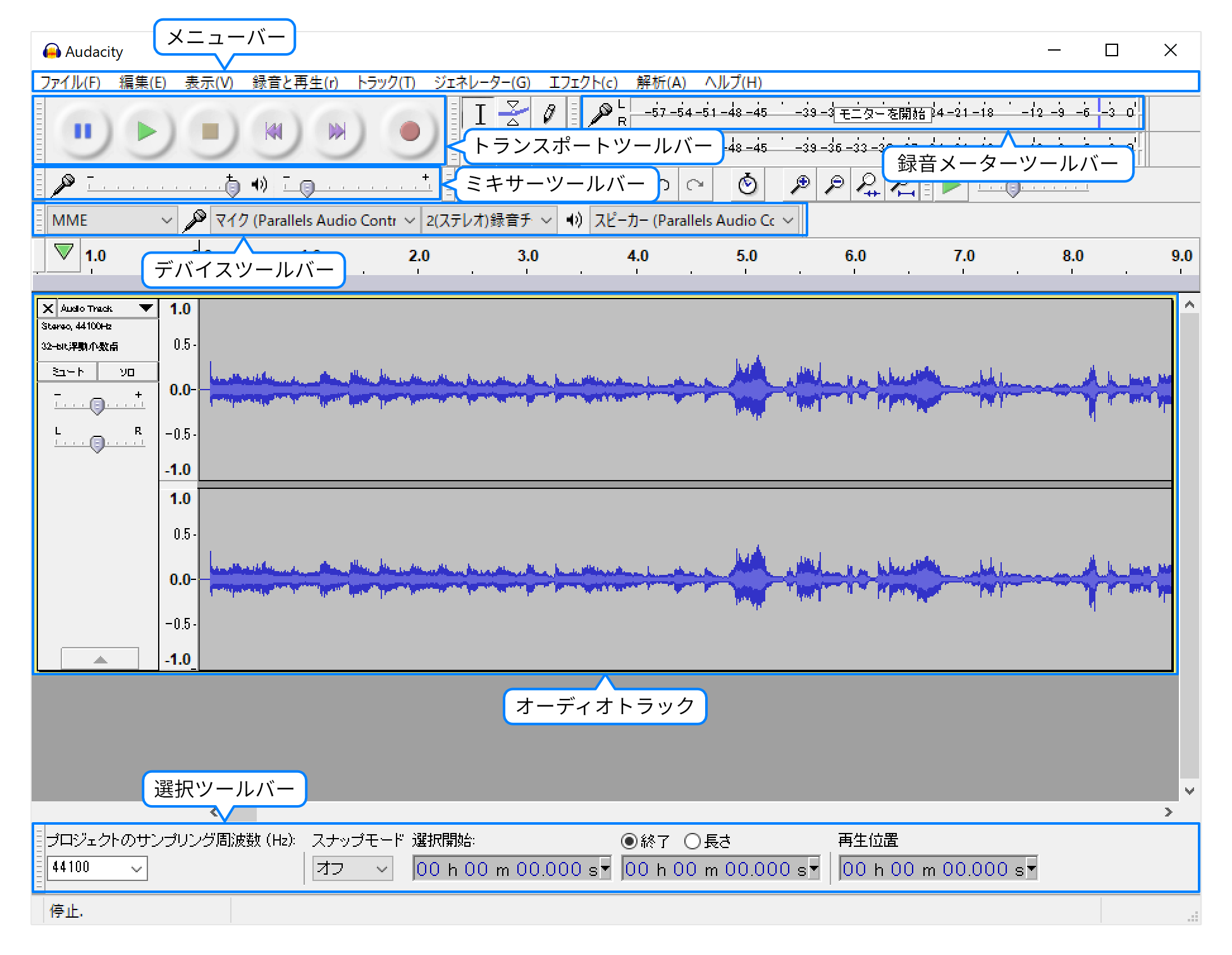
macOS / OS Xの場合、メニューバーはAudacityウィンドウ内ではなく、画面上部にあります。
音声録音の操作手順は、以下のとおりです。
-
デバイスツールバーから「録音デバイス」と「録音チャンネル」を設定します。

- 録音デバイスから録音に使用するデバイスを選択します。
- 録音チャンネルから「1(モノ)録音チャンネル」を選択します。
-
選択ツールバーから「プロジェクトのサンプリング周波数(Hz)」をCloud Speech API推奨の
16000Hzに設定します。
-
これで、録音の準備が整いました。録音を開始する前に、録音時の音声の大きさ(録音レベル)をチェックしておきます。録音メーターツールバーをマウスでクリックすると、録音せずに録音レベルのチェックができます。

-
ミキサーツールバーの録音ボリュームを使って録音レベルを調整します。

-
録音レベルの調整が済んだら、録音メーターツールバーをもう一度マウスでクリックして、録音レベルのチェックを終了させます。
- 録音は、トランスポートツールバーの「録音」ボタンをクリックすると始まります。録音を停止するには、停止ボタンをクリックします。

-
録音データをFLAC形式の音声データとして出力するには、「ファイル」メニューから「オーディオの書き出し」をクリックします。
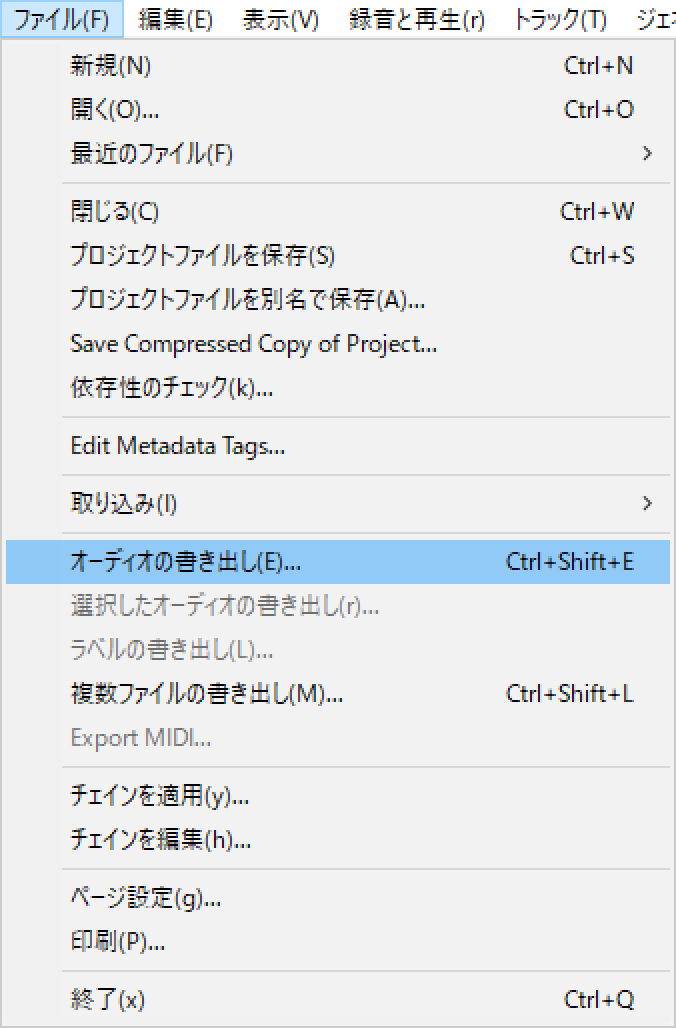
-
オーディオの書き出しウィンドウで、各項目を適切に指定して、「保存」ボタンをクリックします。
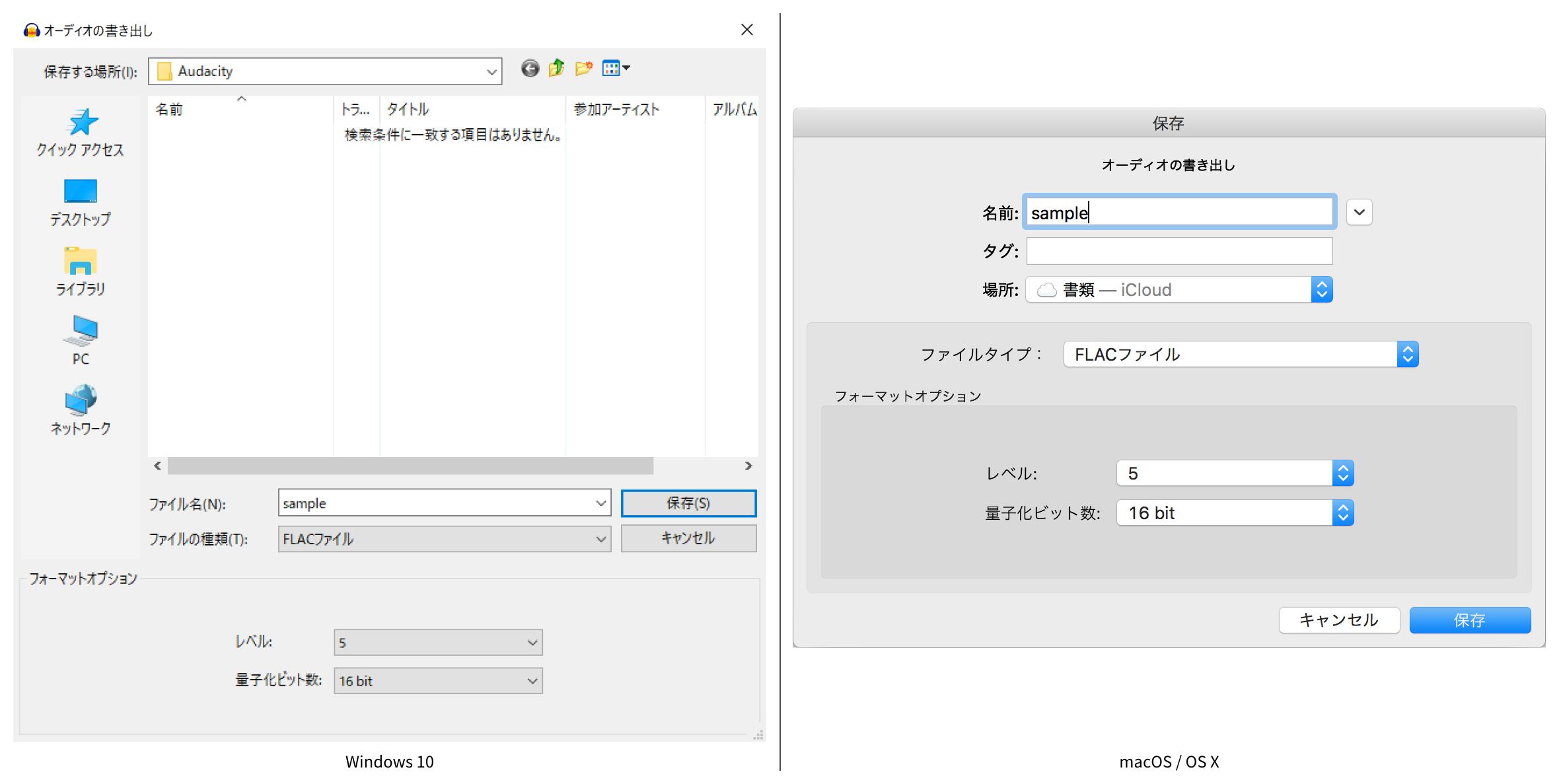
各項目の内容は、以下を参考にしてください(括弧内はmacOS / OS Xの表記)。
- ファイル名(名前):ファイル名を指定します。
- 保存する場所(場所):ファイルを保存する場所を指定します。
- ファイルの種類(ファイルタイプ):「FLACファイル」を選択します。
- レベル:圧縮レベルを「0」から「8」までの数値で指定します。初期値は「5」です。「0」が圧縮なしで、数値が上がるほど圧縮率が上がります。
- 量子化ビット数:「16 bit」を選択します。