はじめに
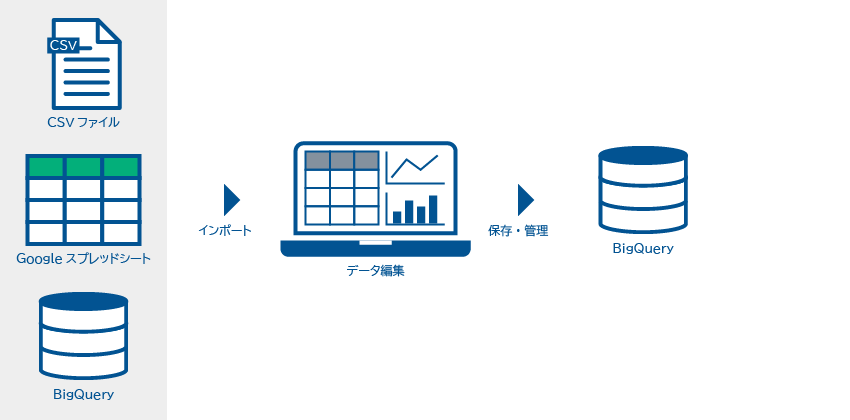
DataEditorは、データの視覚的加工から機械学習モデルの作成・予測まで行えるサービスです。主な機能は以下の通り。
- データの取り込み・加工:
- 対応データ形式:CSVファイル、BigQueryテーブル、Googleスプレッドシート
- 加工データの保存・管理:BigQueryに格納
- インポート機能:ホーム画面のインポートボタンから簡単にデータ取り込み
- データ編集:サマリー表示、グラフ表示、列の編集・追加・結合など多様な機能
- 機械学習モデルの作成・予測:
- 回帰:線形回帰、AutoML、XGBoost、Deep Neural Network
- 分類:ロジスティック回帰、AutoML、XGBoost、Deep Neural Network
- クラスタリング:k-平均法
- 時系列:ARIMA+(限定公開)

DataEditorは、直感的な操作でデータ加工から機械学習モデルの作成、予測まで一貫して行える点が特徴です。
はじめ方
機能紹介
ここでは、以下の主要機能について簡単に解説します。
データ型
DataEditorでは、数値や文字列などさまざまな種類のデータが扱えます。種類毎に型として定義し、使い分けます。
| 型 | 説明 |
|---|---|
| INTEGER |
小数部分を持たない数値(整数)です。 |
| FLOAT |
小数部分を持つ数値(浮動小数点数)です。 |
| NUMERIC |
10進数で38桁(内小数部9桁)の数値です。 (範囲:-99999999999999999999999999999.999999999から99999999999999999999999999999.999999999) |
| BOOLEAN |
キーワードTRUEとFALSE(大文字・小文字の区別なし)で表す2値を表現する値です。 CSV形式ファイルで以下のように定義されたデータ(すべて大文字・小文字の区別なし)は、この型に変換されます。
|
| STRING |
文字列(UTF-8)です。 値が、画像ファイルへのGCS URL(gs://foo/bar.jpgのような形式)の場合、データ表示で画像のプレビューが可能です。画像のプレビューができるのは、以下のいずれかです。
|
| BYTES |
可変長のバイナリーデータです。 |
| DATE |
特定の日です(範囲:0001-01-01から9999-12-31)。 |
| DATETIME |
特定の日時です(範囲:0001-01-01 00:00:00から9999-12-31 23:59:59.999999)。 |
| TIME |
特定の日付に関係ない時刻です(範囲:00:00:00から23:59:59.999999)。 |
| TIMESTAMP |
タイムゾーンや夏時間などの習慣に関係ない、絶対的な時刻です(範囲:0001-01-01 00:00:00から9999-12-31 23:59:59.999999 UTC)。単位はマイクロ秒です。 |
info_outline型は、Google BigQueryのデータ型に準拠しています。詳しくは、BigQueryドキュメント「GoogleSQLデータ型open_in_new」を参照願います。
インポート
データを加工するためには、データをDataEditorに取り込む必要があります。このデータの取り込みには、インポート機能を使います。
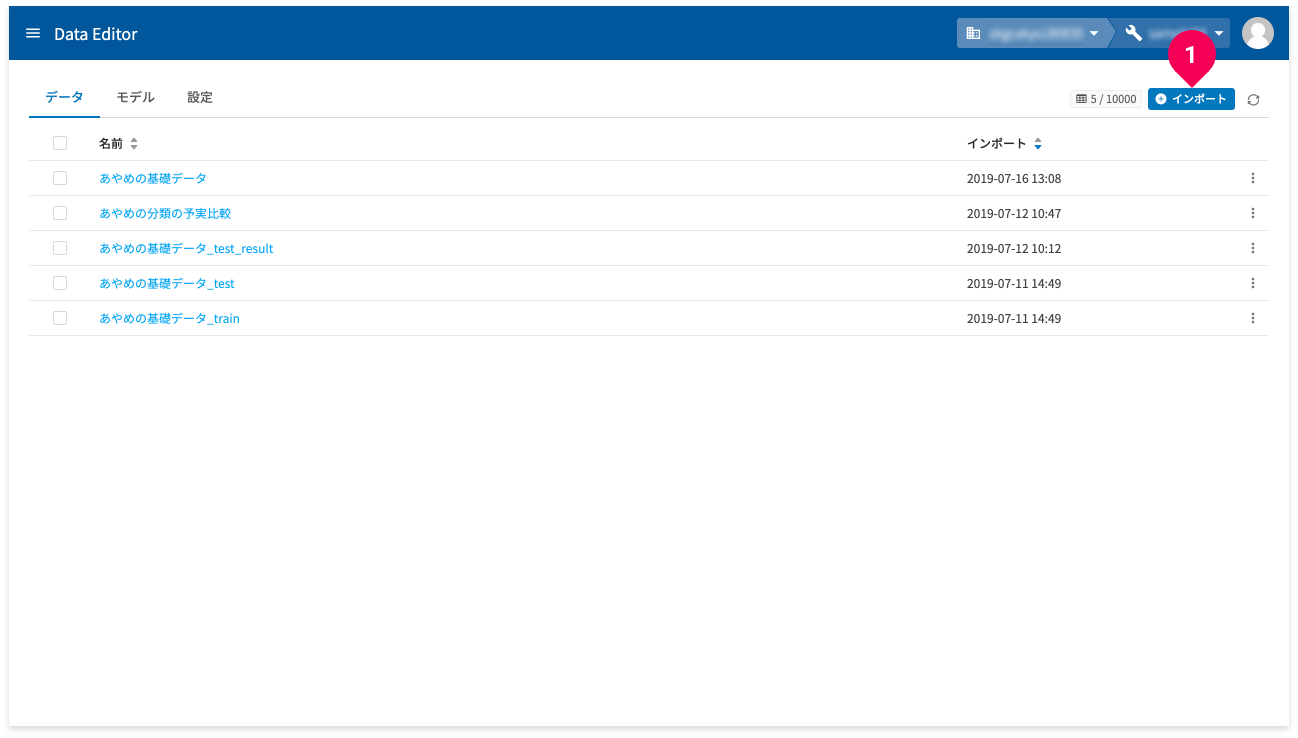
データの取り込みは、ホーム画面の[インポート]ボタン(❶)をクリックします。
インポートのおおまかな手順は、以下のとおりです。
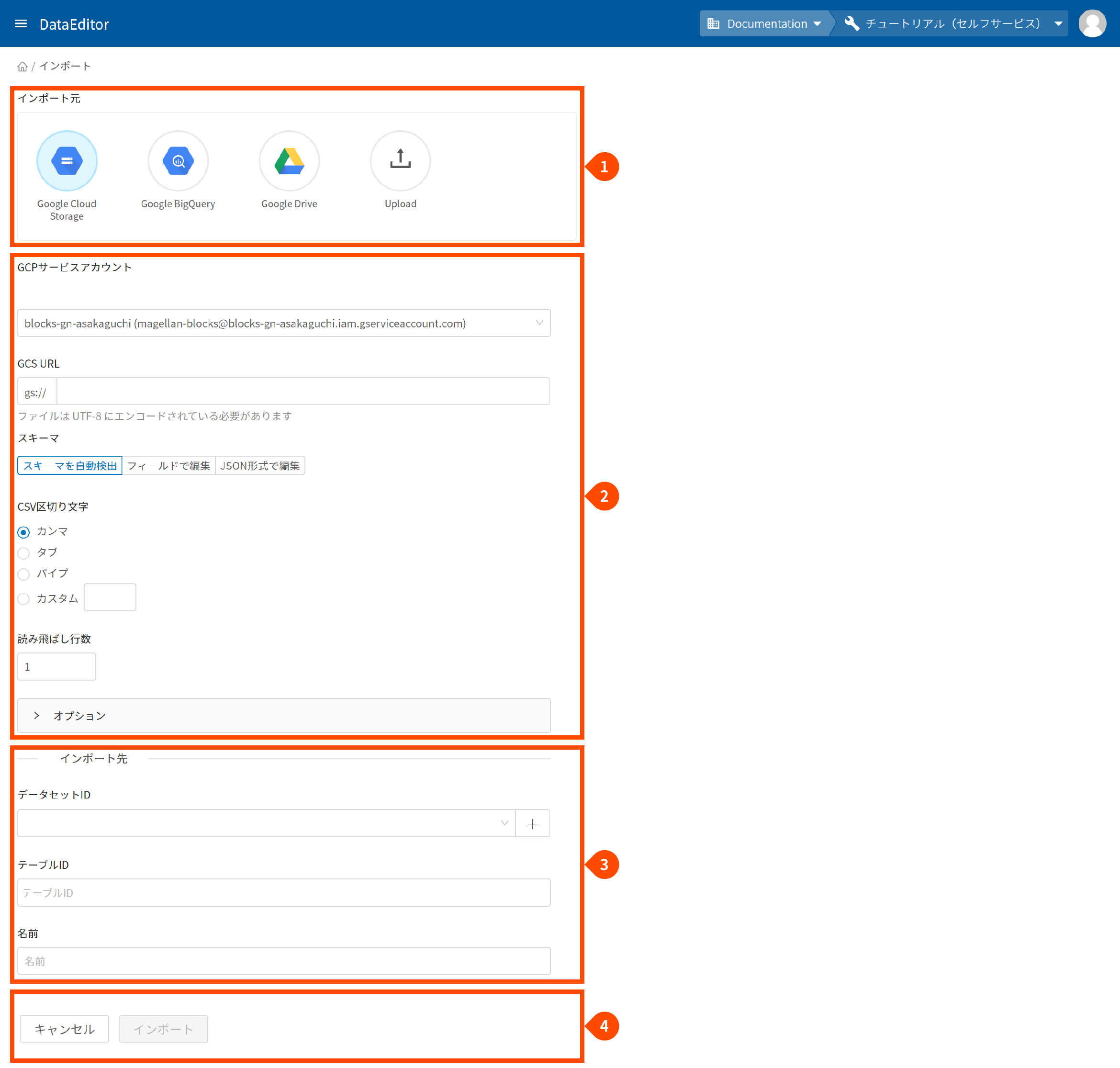
- インポート元を選択
インポート可能なデータは、以下のとおりです。
- Google Cloud Storage:Google Cloud Storage(GCS)上のCSV形式ファイル
- Google BigQuery:Google BigQueryのテーブル
- Google Drive:Google Drive上のスプレッドシート(先頭のシートのみ)もしくはCSV形式ファイル
- Upload:PC上のCSV形式ファイル
- パラメーターを設定
パラメーターの設定は、インポート元ごとに異なります(後述)。
- インポート先を設定
DataEditorは、データをBigQuery上に格納して管理するため、その格納先(以下参照)を指定します。
- データセットID:格納先となるBigQueryのデータセットID
- テーブルID:格納先となるBigQueryのテーブルID
- 名前:DataEditorで管理する名前
info_outlineインポート元がGoogle BigQueryの場合は、名前のみ指定します。
- [インポート]ボタンをクリック
インポート元ごとのパラメーターについては、以下の解説を参照願います。
Google Cloud Storageのパラメーター設定
Google Cloud Storage(GCS)では、GCS上のCSV形式ファイルがインポートできます。パラメーターは、以下のとおりです。
| パラメーター名 | 説明 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GCPサービスアカウント | インポート対象のGCSにアクセス可能なGCPサービスアカウントを指定します。 | ||||||||||||
| GCS URL | インポートするCSV形式ファイルを指定します。 | ||||||||||||
| スキーマ |
データをBigQueryテーブルに格納する際のスキーマ(列名やデータ型など)を指定します。
|
||||||||||||
| CSV区切り文字 |
CSV区切り文字を指定します。
|
||||||||||||
| 読み飛ばし行数 | 先頭から何行読み飛ばすかを指定します。 | ||||||||||||
| オプション |
|
Google BigQueryのパラメーター設定
Google BigQueryでは、指定されたBigQueryテーブルをそのままDataEditorで利用できるようにします。パラメーターについては、以下のとおりです。
| パラメーター名 | 説明 |
|---|---|
| GCPサービスアカウント | インポート対象のBigQueryテーブルにアクセス可能なGCPサービスアカウントを指定します。 |
| データセットID | インポート対象のBigQueryテーブルのデータセットIDを選択します。 |
| テーブルID | インポート対象のBigQueryテーブルIDを選択します。 |
Google Driveのパラメーター設定
Google Driveでは、Google Drive上のGoogleスプレッドシート(先頭のシートのみ)もしくはカンマ(,)区切りのCSV形式ファイルがインポートできます。パラメーターは、以下のとおりです。
| パラメーター名 | 説明 |
|---|---|
| GCPサービスアカウント | インポート対象にアクセス可能なGCPサービスアカウントを指定します。 |
| ファイルURI |
https://drive.google.com/open?id=*****のような形式でGoogleスプレッドシートもしくはCSV形式ファイルのURIを指定します(*****の部分はスプレッドシートやCSV形式ファイルごとに変わる)。 上記形式のURIを取得するには、Googleドライブ上の当該ファイルを右クリックし、[共有可能なリンクを取得]を選択します。 |
| ファイルフォーマット |
上記[ファイルURI]で指定したファイルのフォーマットを指定します。指定できるフォーマットは以下のとおりです。
|
ファイルフォーマットごとに、指定するパラメーターは異なります。
- Googleスプレッドシート
パラメーター名 説明 スキーマ データをBigQueryテーブルに格納する際のスキーマ(列名やデータ型など)を指定します。
- スキーマを自動検出
CSV形式ファイルの内容からスキーマを自動生成します。
- フィールドで編集
列ごとに列名・データ型・モードを指定します。
- JSON形式で編集
JSON形式の文字列でスキーマを指定します。
読み飛ばし行数 先頭から何行読み飛ばすかを指定します。 - スキーマを自動検出
- CSVファイル
パラメーター名 説明 スキーマ データをBigQueryテーブルに格納する際のスキーマ(列名やデータ型など)を指定します。
- スキーマを自動検出
CSV形式ファイルの内容からスキーマを自動生成します。
- フィールドで編集
列ごとに列名・データ型・モードを指定します。
- JSON形式で編集
JSON形式の文字列でスキーマを指定します。
読み飛ばし行数 先頭から何行読み飛ばすかを指定します。 オプション 項目 説明 クオート記号 クオート記号を指定します。 改行有無 クオートされた文字列に改行が含まれているかいないかを指定します。
クオートされた文字列に改行が含まれている場合は、チェックボックスにチェックを付けます。
不正な行の許容数 不正な行の許容数を指定します。この行数を超える不正な行があるとインポートに失敗します。 不足フィールド フィールド数が足らない行を許容するかしないかを指定します。
フィールド数が足らない行を許容する場合は、チェックボックスにチェックを付けます。
余分フィールド 余分なフィールドを無視するかしないかを指定します。
余分なフィールドを無視する場合は、チェックボックスにチェックを付けます。
- スキーマを自動検出
Uploadのパラメーター設定
Uploadでは、PC上のCSV形式ファイルがインポートできます。パラメーターは、以下のとおりです。
| パラメーター名 | 説明 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ファイル |
Uploadでは、PC上のCSV形式ファイルをGCS経由でインポートします。このため、経由先となるGCS上のURLをgs://横の入力フィールドに指定します。その後、PC上のCSV形式ファイルを[ファイルをドラッグまたはファイルを選択]欄にドラッグするか、この欄をクリックしてファイルを選択します。 |
||||||||||||
| スキーマ |
データをBigQueryテーブルに格納する際のスキーマ(列名やデータ型など)を指定します。
|
||||||||||||
| CSV区切り文字 |
CSV区切り文字を指定します。
|
||||||||||||
| 読み飛ばし行数 | 先頭から何行読み飛ばすかを指定します。 | ||||||||||||
| オプション |
|
データ編集
ホーム画面のデータタブ(❶)で、名前(❷)をクリックすると、取り込んだデータの編集ができます。
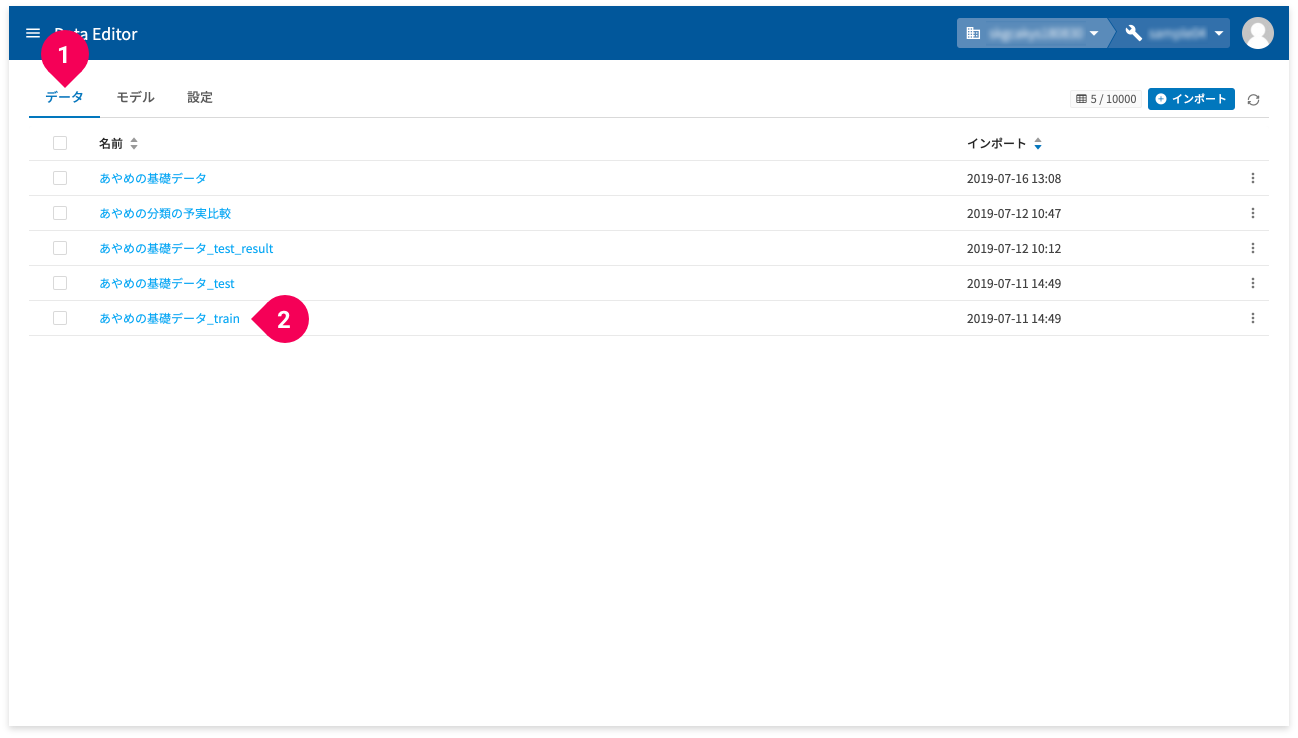
データの編集では、以下のことができます。
サマリー
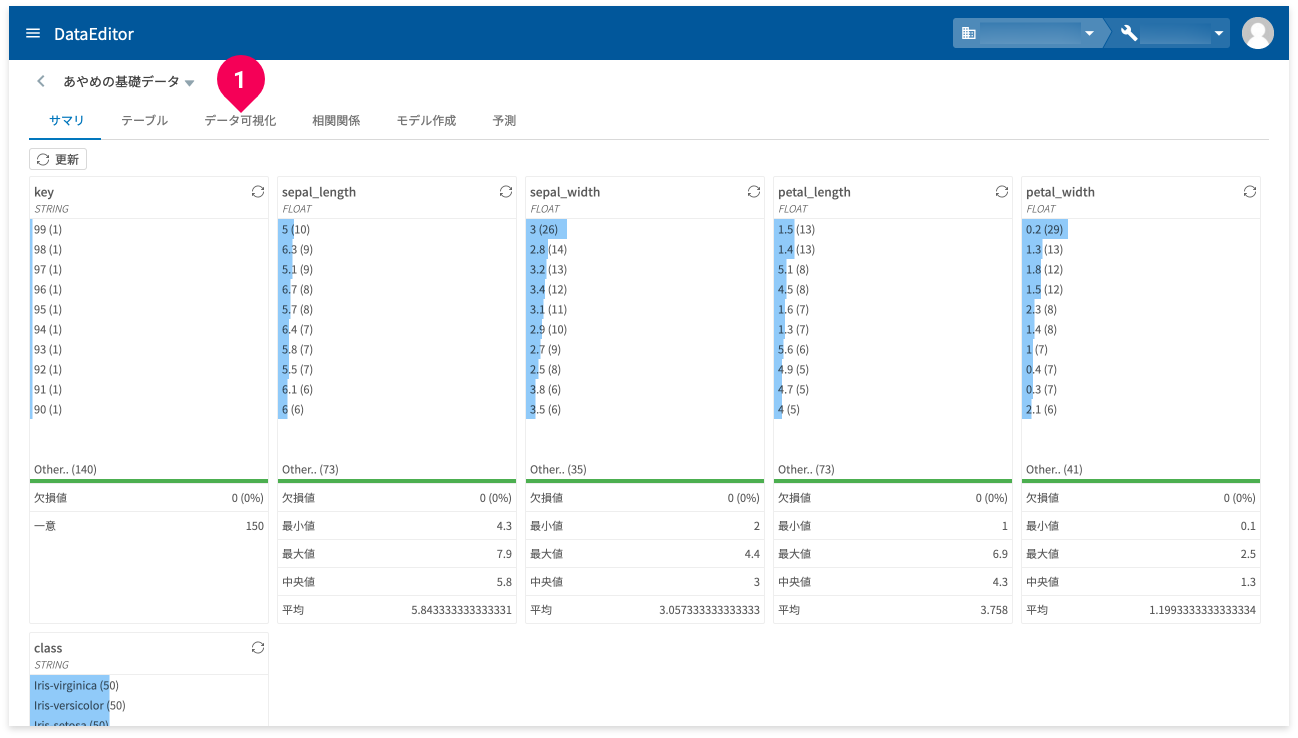
サマリー機能では、データ集計結果の要約が確認できます。
確認できる集計結果は、最頻値上位12個(括弧内はその数値の個数)・欠損値・最小値・最大値・中央値・平均・一意な値の個数です。表示される集計の種類は、型によって異なります。
サマリーは、[サマリ]タブ(❶)で確認できます。
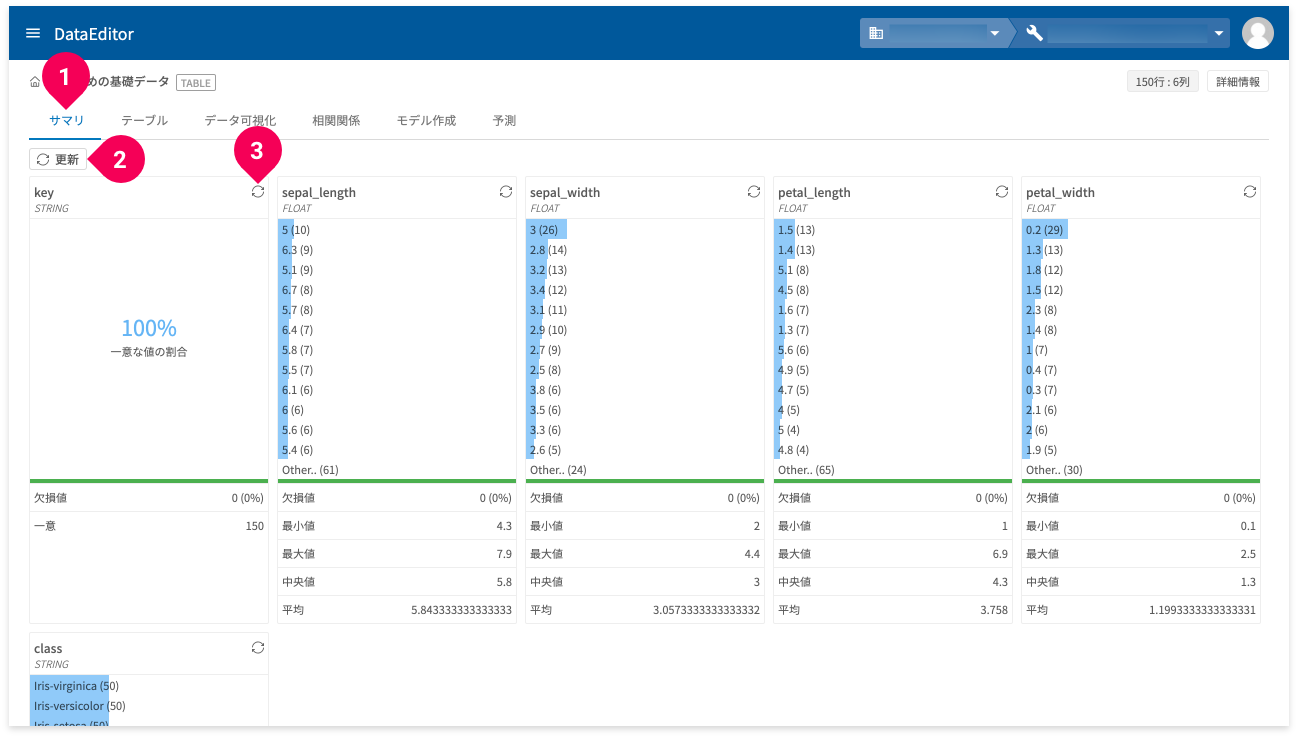
データが集計されていないときは、[すべての列を集計]もしくは[更新]ボタン(❷)をクリックすると、データの集計が行えます。また、集計後にデータを更新した場合もこのボタンで再集計が可能です。カラムごとにある❸のボタンをクリックすることで、カラムごとの再集計も可能です。
インポート機能で、データを取り込んだ場合は、自動集計されます。
下図は、サマリーのグラフ例です。
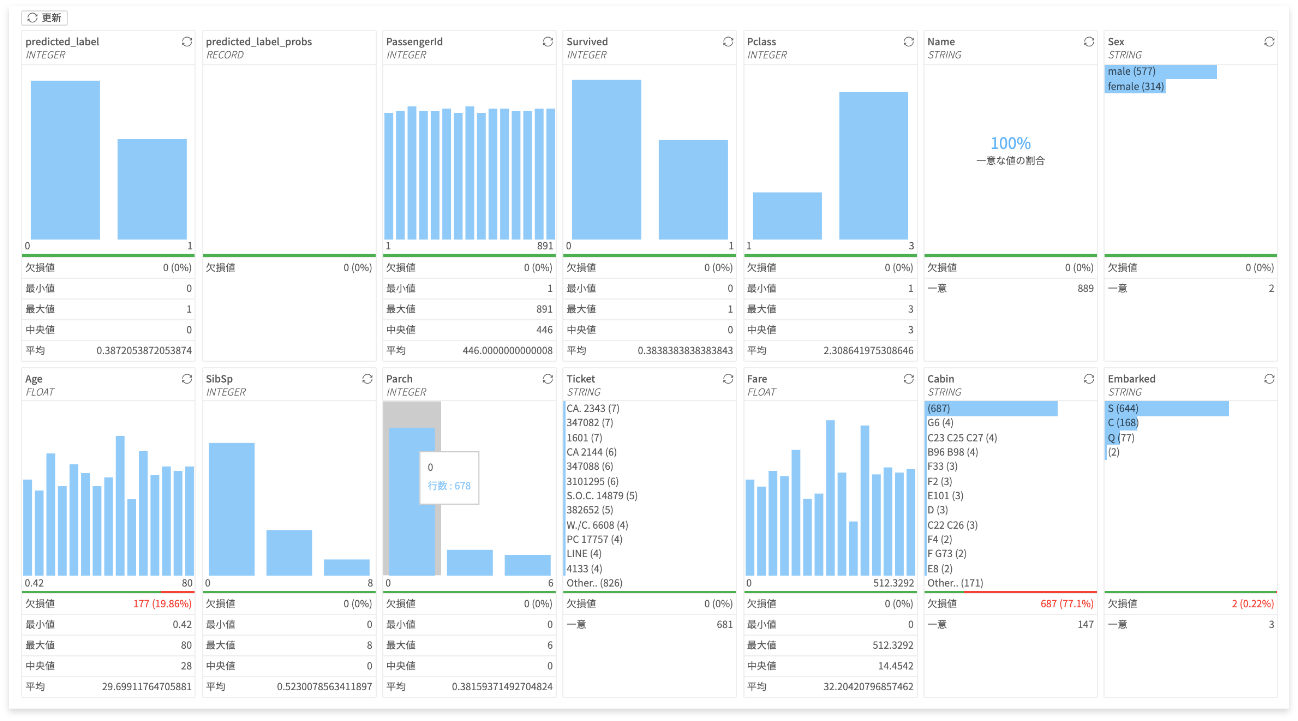
STRING型のサマリーで、otherで省略表示されている場合は、otherのすべて表示アイコンをクリックすると全件表示できます。手順は、以下のとおりです。
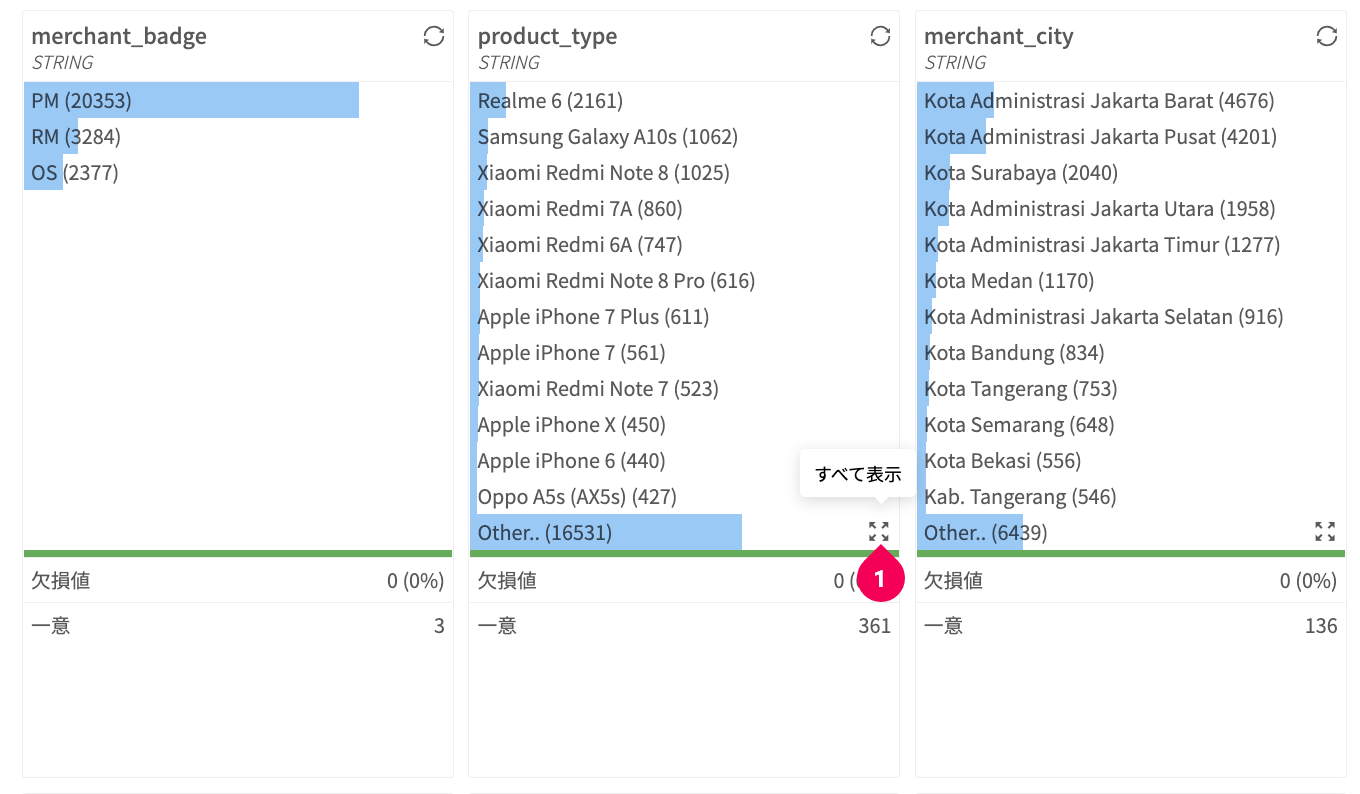
- zoom_out_mapアイコンをクリック
しばらくすると、全件表示の一覧がモーダルダイアログで表示されます。

×ボタン(❶)をクリック(もしくは、モーダル外をクリック)で、画面が閉じます。
info_outline本サマリーは、正確な集計結果ではなく近似的な集計結果となっています(近似集計を採用)。これにより、大規模なデータであっても使用メモリ量を抑え、高速な集計を実現しています。
グラフ表示
グラフ表示は、テーブルタブ(❶)でできます。
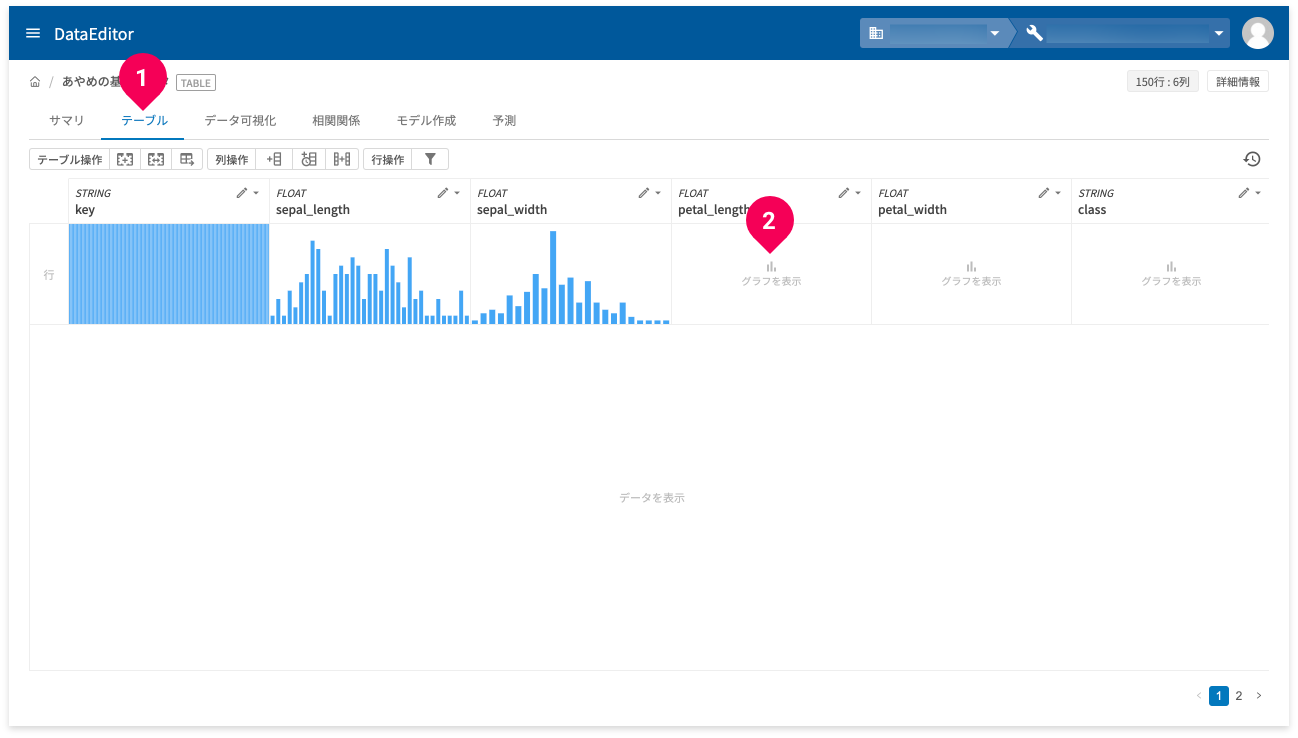
各列の[グラフを表示](❷)をクリックすると、列ごとのグラフが表示できます。これにより、列ごとのデータの分布を視覚的に把握できます。
info_outline欠損値は、赤で表示されます。
データ表示
データ表示は、テーブルタブ(❶)でできます。
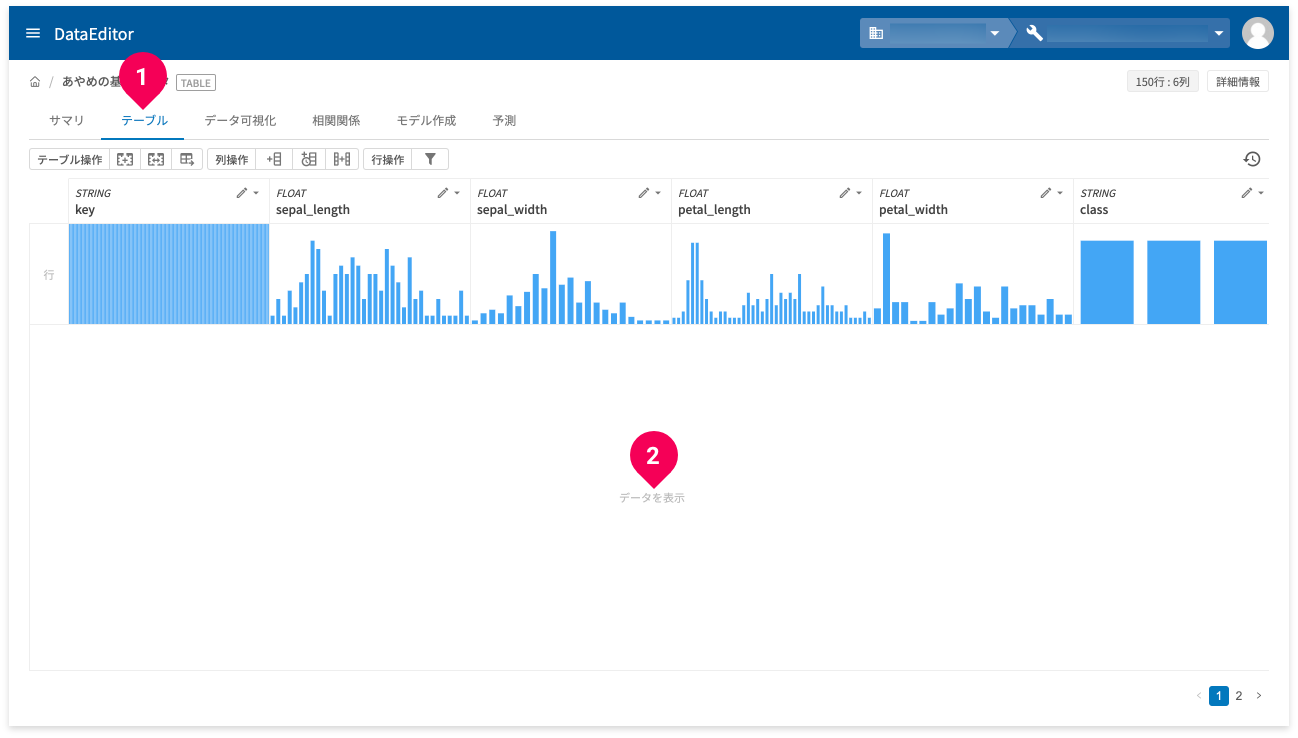
[データを表示](❷)をクリックすると、データを表形式で確認できます。
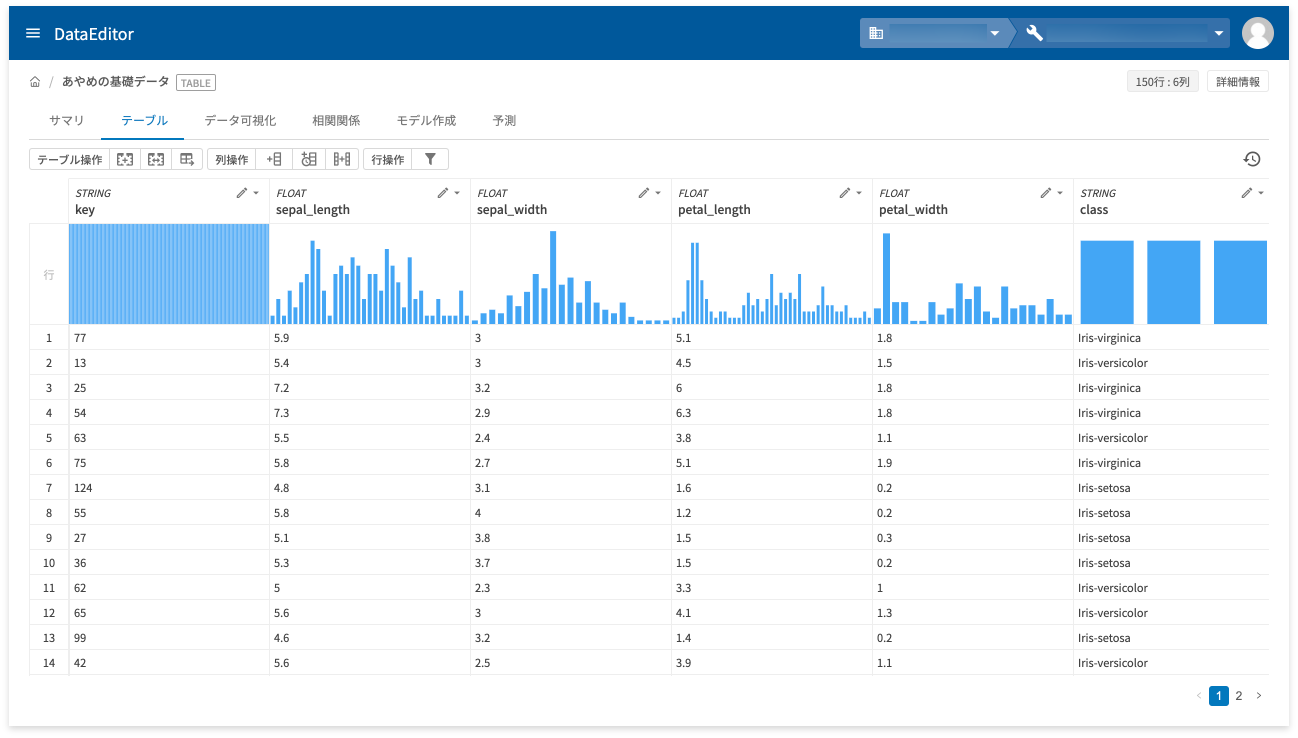
STRING型で値が画像ファイルへのGCS URL(gs://foo/bar.jpgのような形式)の場合、画像のプレビュー表示ができます。画像のプレビューができるのは、以下のいずれかです。
- ファイルの拡張子がJPG・JPEG・PNG・BMP・GIF・SVG(大文字・小文字の区別なし)
- ファイルのタイプ(MIMEタイプ)がimage/*(例:image/jpeg・image/pngなど)
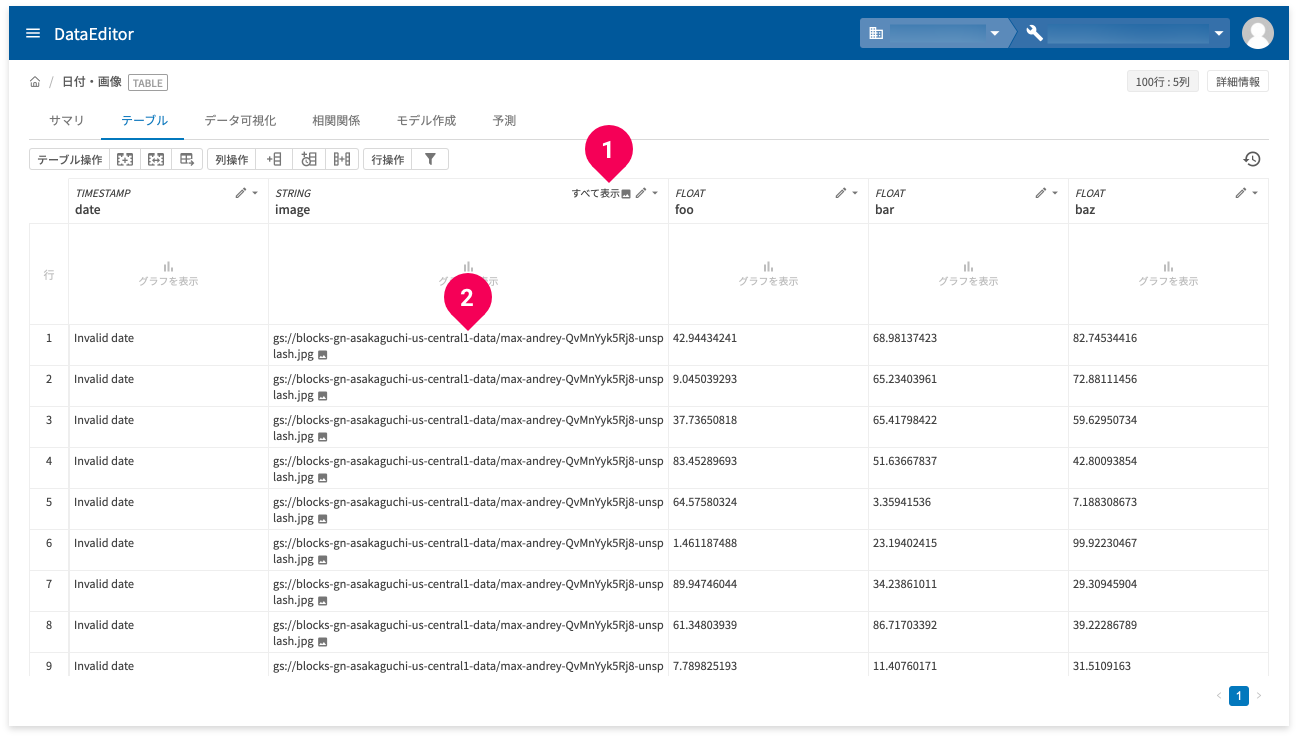
[すべて表示](❶)もしくはGCS URLのセル(❶)をクリックすると、セル内に画像がプレビュー表示されます。[すべて表示]をクリックした場合は、ページ内同列のすべてのセル内に画像がプレビュー表示されます(次ページ以降分は表示されない)。
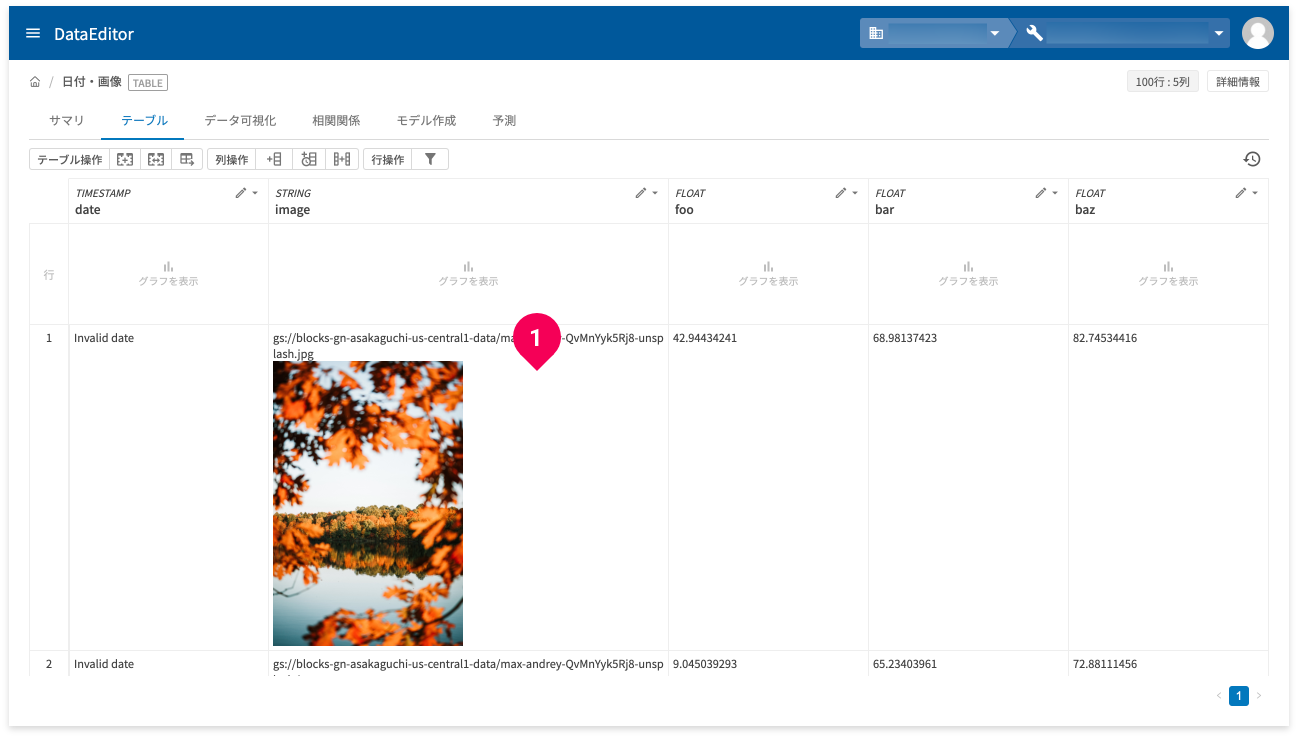
プレビューが表示されたセルをクリックすると、画像が拡大表示されます。
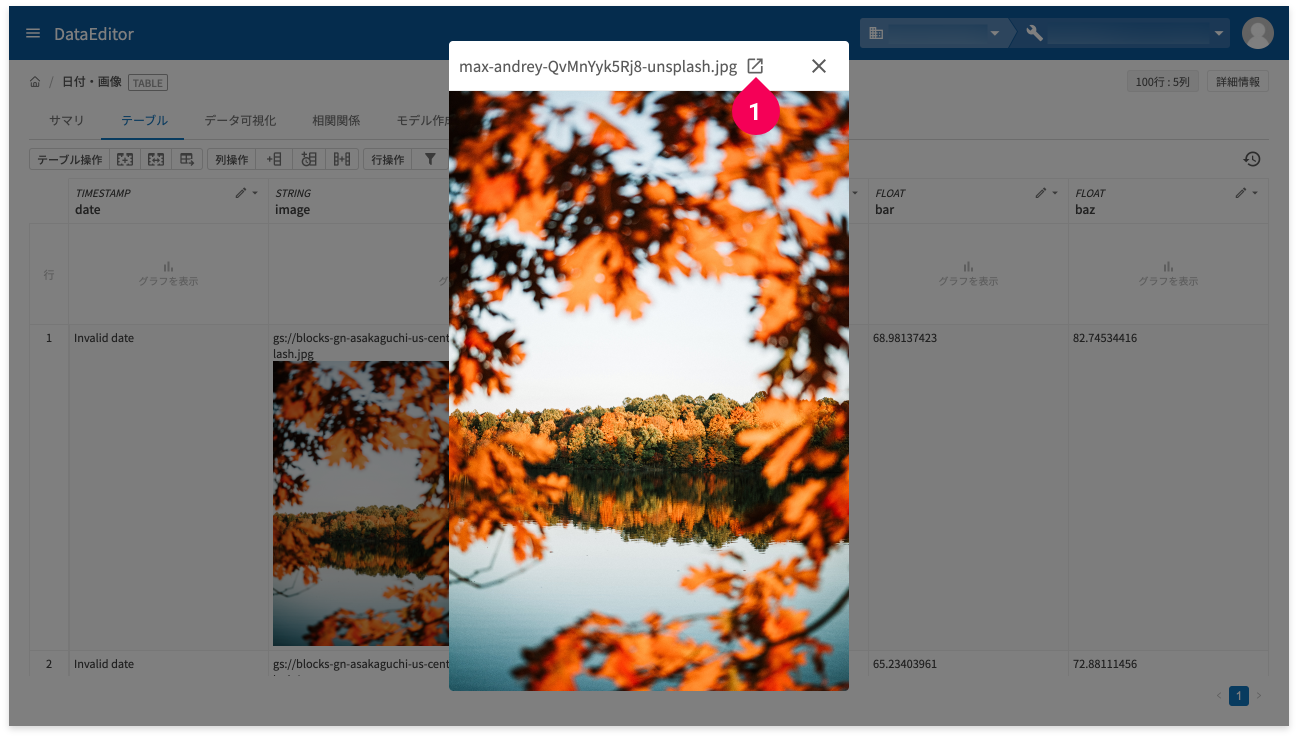
❶部分のアイコンをクリックすると、画像ファイルを別タブに表示するか、ダウンロードができます。画像を別タブに表示するのか、ダウンロードするのかは、ファイルのタイプ(MIMEタイプ)によります。
- タイプがimage/*:別タブに表示
- タイプがimage/*以外:ダウンロード
列の編集
列の編集は、テーブルタブ(❶)でできます。
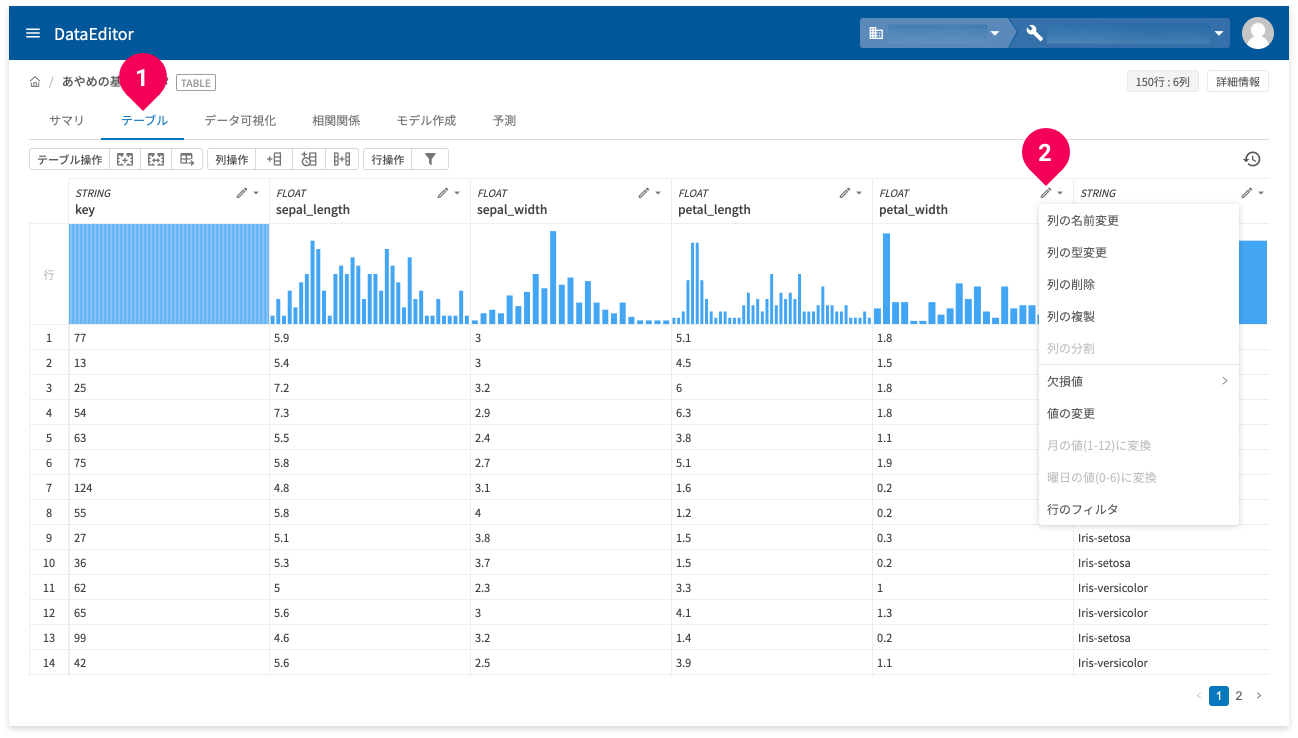
列の編集は、各列のeditアイコン(❷)をクリックし、表示されるメニューから項目を選択します。ここで行った列の編集操作は、別名で保存もしくは上書き保存するまでは、反映されません。保存するまでは、いつでも編集操作をやり直し可能です。
- 列の名前変更
列の名前が変更できます。
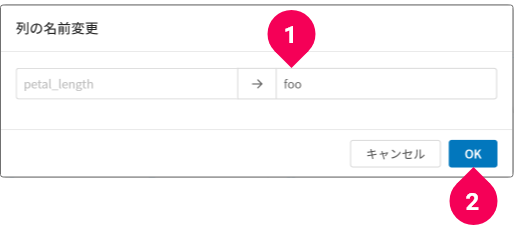
変更後の名前(❶)を入力し、[OK]ボタン(❷)をクリックします。
- 列の型変更
列の型が変更できます。
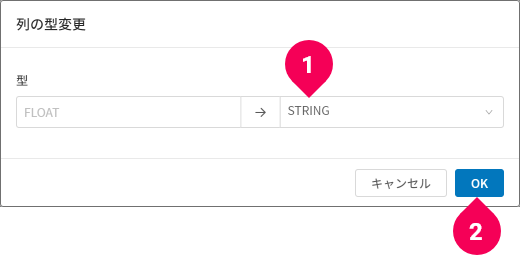
変更後の型(❶)を選択し、[OK]ボタン(❷)をクリックします。
- 列の削除
列の削除ができます。
- 列の複製
列の複製ができます。
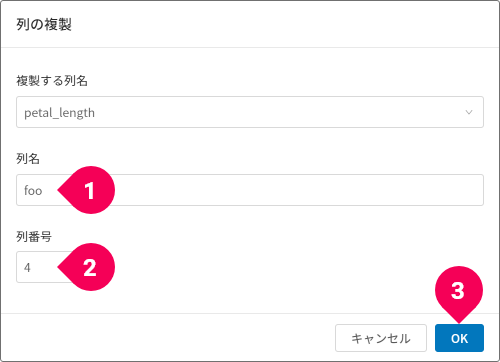
複製後の列名(❶)の入力と列の挿入位置(❷)を指定し、[OK]ボタン(❸)をクリックします。
- 列の分割
型がSTRING(文字列)の場合は、列を複数の列に分割できます。
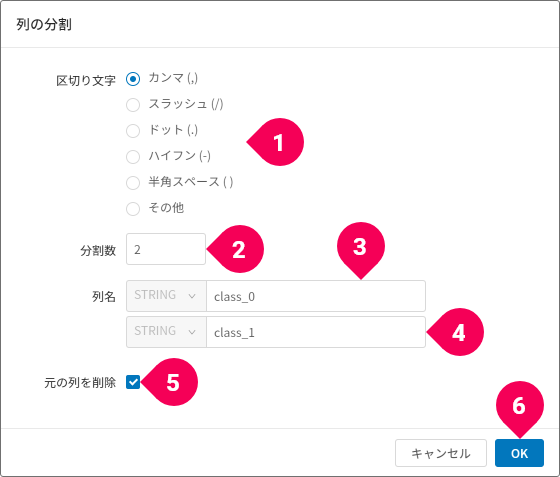
文字列を分割する区切り文字(❶)を選択し、分割する列数(❷)、分割後の各列名(❸・❹)を入力し、[OK]ボタン(❻)をクリックします。デフォルトでは、分割元の列を削除しますが、残したい場合は、[元の列を削除](❺)のチェックを外します。
- 欠損値
欠損値に対して列ごとに以下の操作ができます。
- 行の削除:欠損値を含む行を削除
- 行のみ残す:欠損値を含む行のみ残す
- 集計値で補完:列の平均値・中央値・最小値・最大値のいずれかで補完
- 任意の値で補完:欠損値を指定した任意の値で補完
- ほかの列の値で補完:欠損値を指定したほかの列値で補完
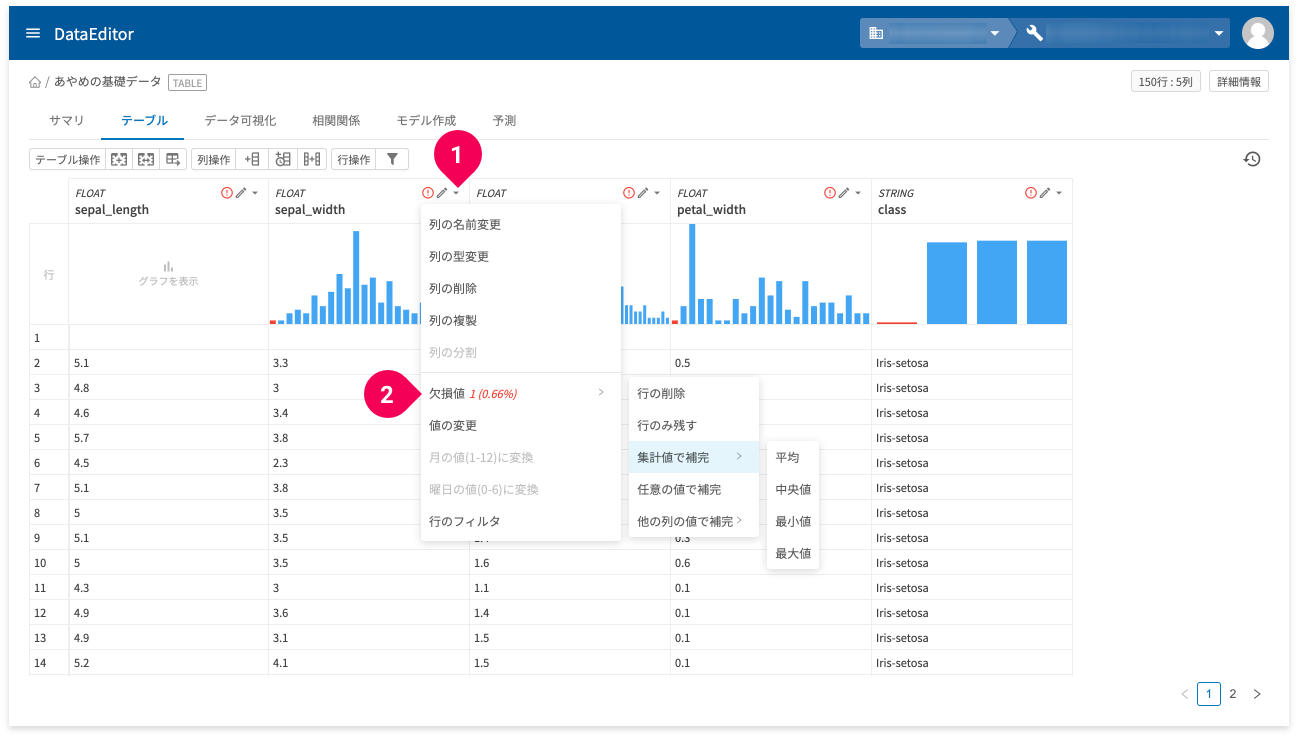
列の編集(❶)メニューの[欠損値](❷)から[行の削除]・[行のみ残す]・[集計値で補完]・[任意の値で補完]・[他の列の値で補完]のいずれかを選択します。
info_outline「行のみ残す」操作を複数列に対して行うと、操作した列すべてに欠損値のある行が残されます。
- 値の変更
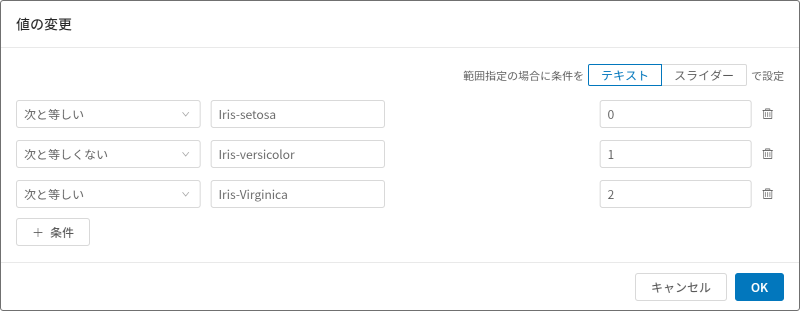
条件指定による値の変更ができます。
- 月の値(1-12)に変換
DATE型・DATETIME型・TIMESTAMP型の日付データを1から12の月の値に変換ができます。変換後の型は、INTEGER型です。
TIMESTAMP型の場合は、指定のタイムゾーンもしくは協定世界時(UTC)から選択して変換ができます。
- 曜日の値(0-6)に変換
STRING型・DATE型・DATETIME型・TIMESTAMP型の日付データを曜日の値に変換ができます。変換後の型は、INTEGER型です。
TIMESTAMP型の場合は、指定のタイムゾーンもしくは協定世界時(UTC)から選択して変換ができます。
曜日の値 曜日 0 日曜日 1 月曜日 2 火曜日 3 水曜日 4 木曜日 5 金曜日 6 土曜日 STRING型の場合は、年-月-日 時:分:秒の書式が変換対象となります。
- 行のフィルタ
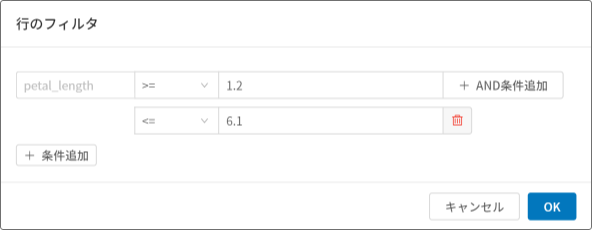
各行値の条件による行の絞り込み表示ができます。
列の追加
列の追加は、テーブルタブ(❶)でできます。
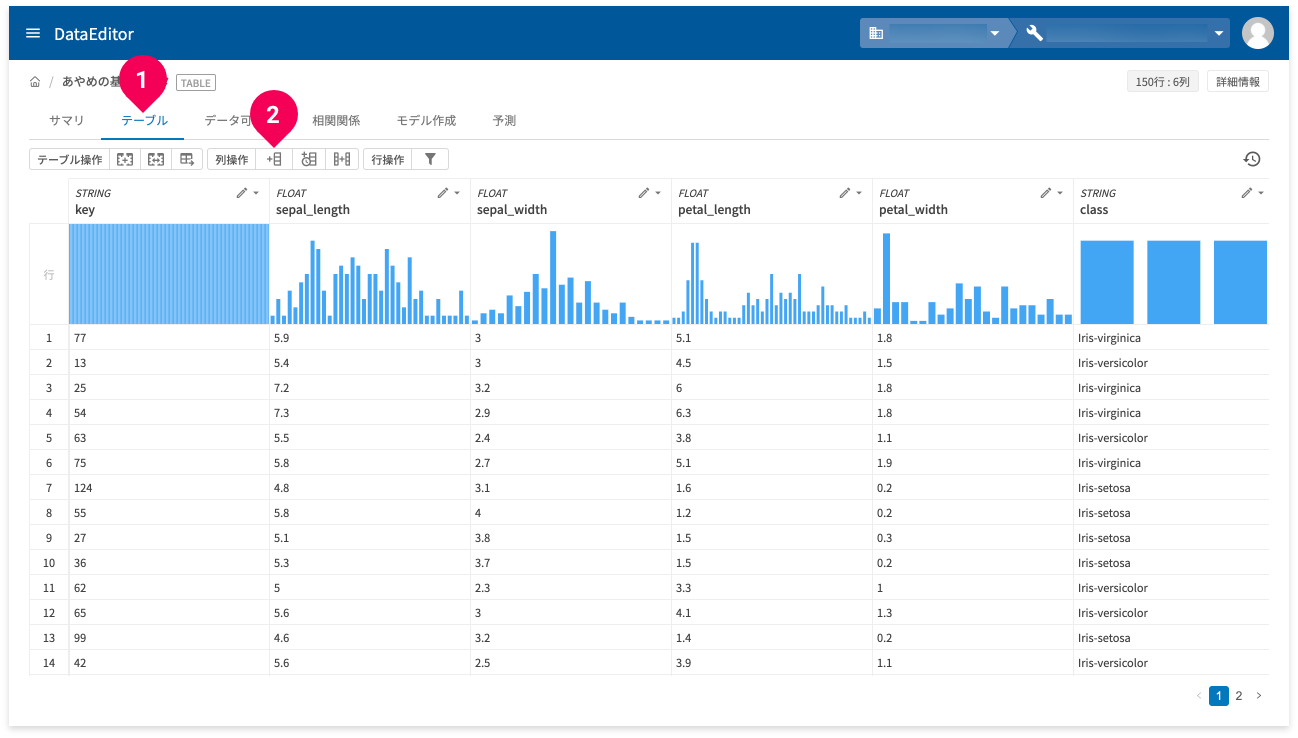
列の追加アイコン(❷)をクリックします。
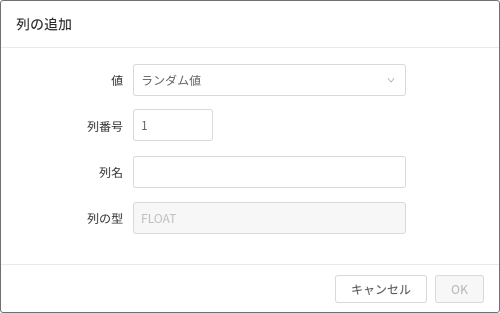
列の追加では、以下2種類の列の追加ができます。
- ランダム値(FLOAT型)
- シーケンシャル値(INTEGER型)
時系列データの列追加
時系列データの列追加は、テーブルタブ(❶)でできます。
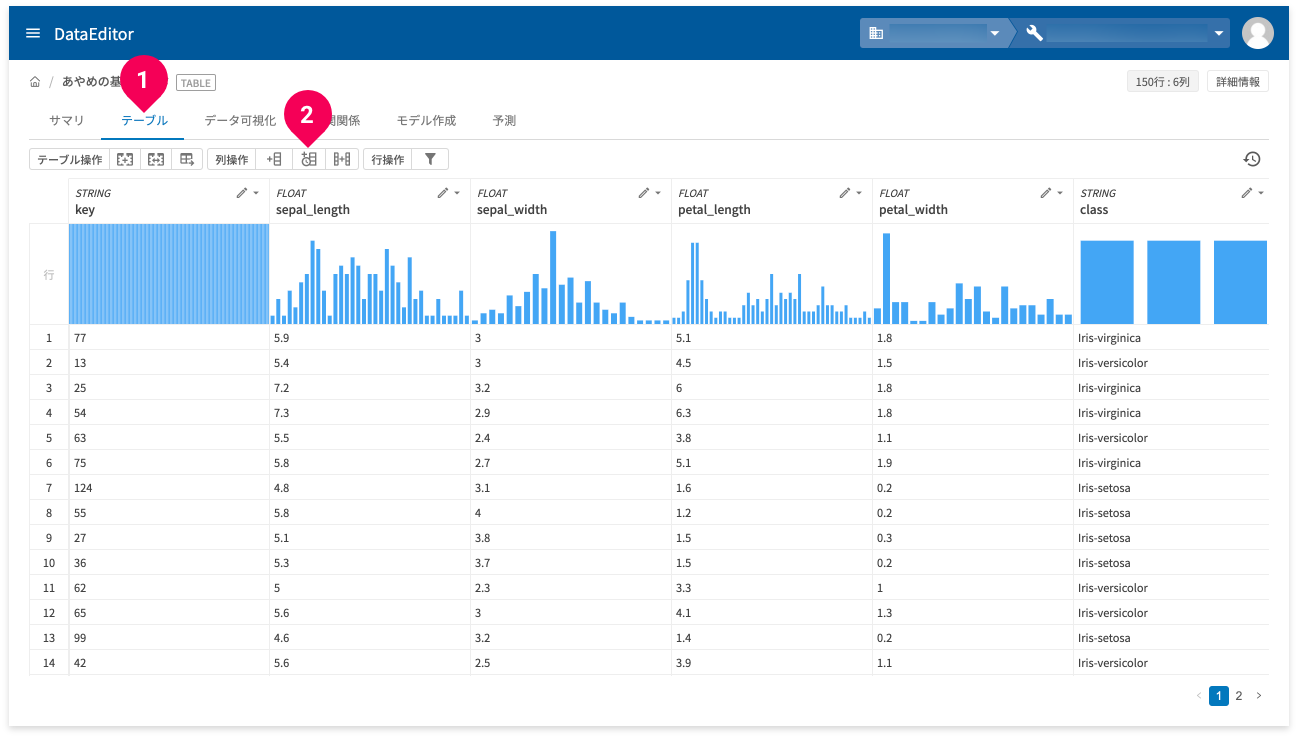
時系列データ用の列追加アイコン(❷)をクリックします。
時系列データの列が追加できます。
列の結合
列の結合は、テーブルタブ(❶)でできます。
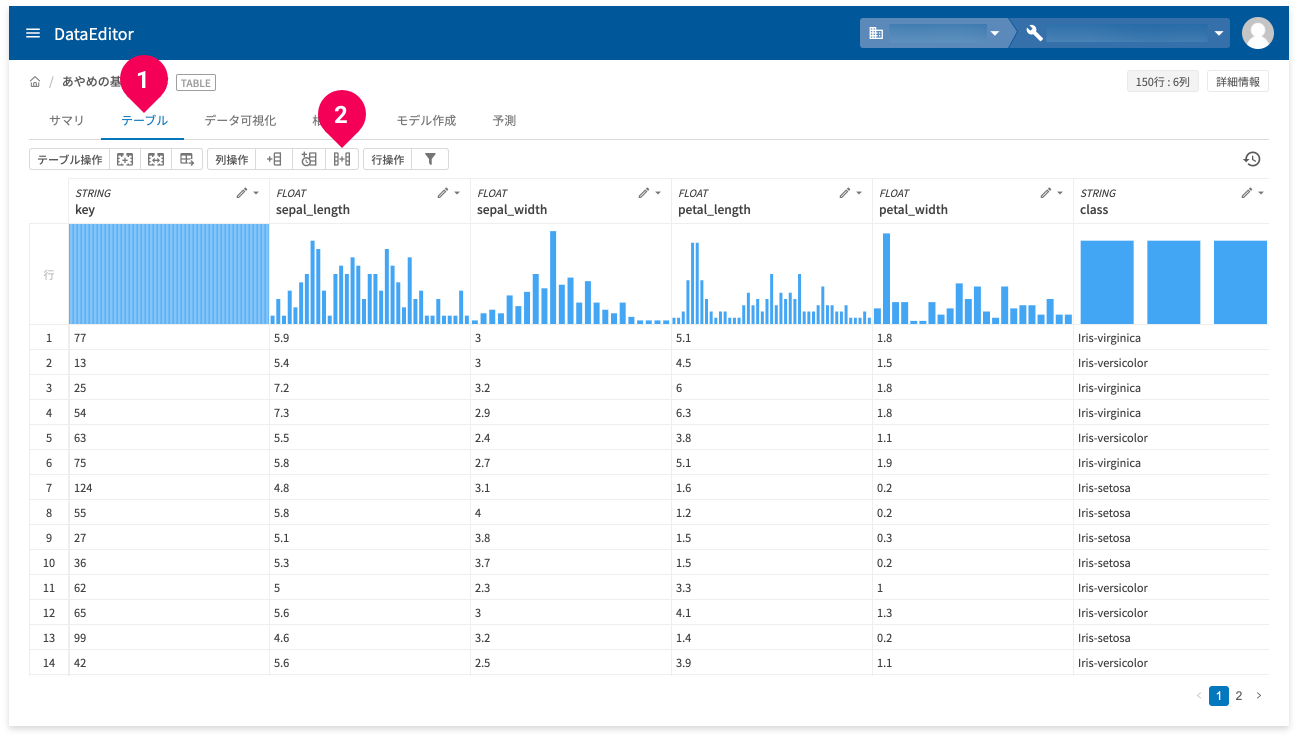
列の結合アイコン(❷)をクリックします。
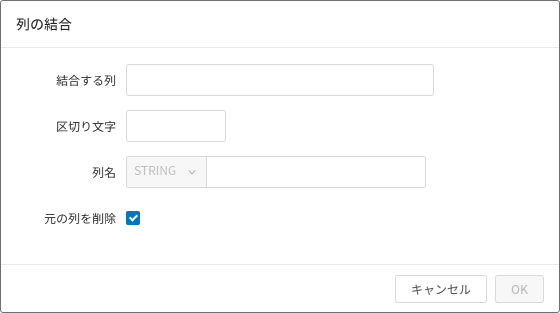
複数の列を1つの列に結合できます。
変更手順
変更手順は、一連の編集操作を記録し、その記録を再生できる機能です。
複数のデータ間で、繰り返し行う一連の操作を記録しておけば、1回の指示でその一連の操作を他のデータに対して適用できます。
変更手順に記録できる一連の操作は、プロジェクトごとに20件までです。
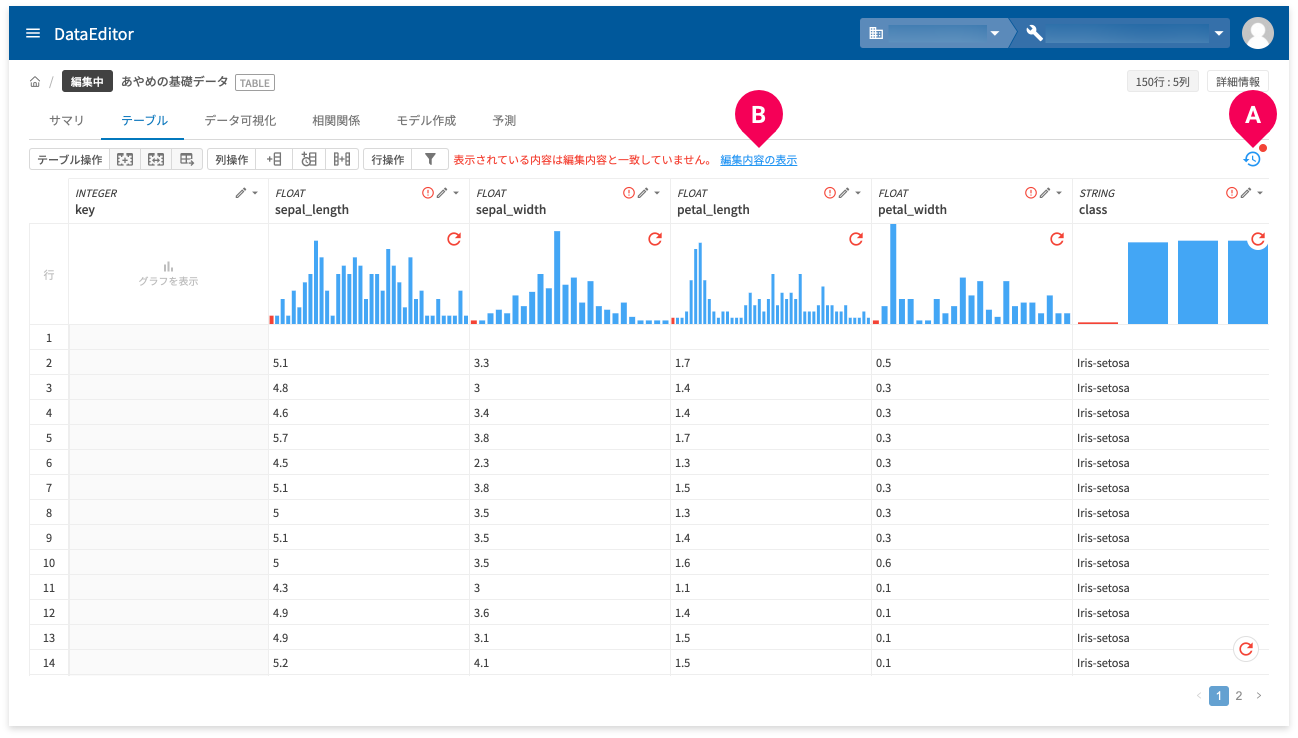
変更手順を利用するには、restore(A)をクリックします。グラフやデータを表示した状態で、編集操作を行った場合は、[編集内容を表示](B)をクリックでも変更手順が利用可能です。
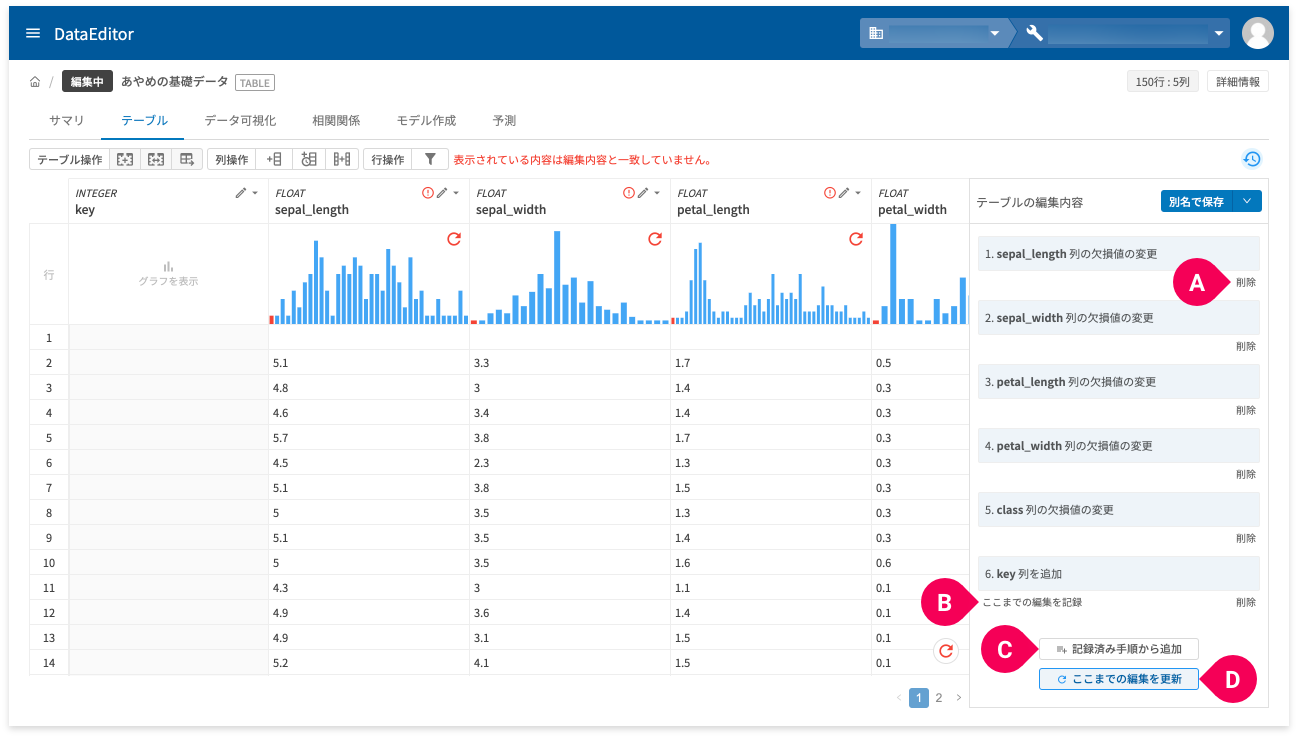
| A | 削除 | 当該の編集操作を削除します。 |
|---|---|---|
| B | ここまでの編集を記録 | ここまでの変更手順(上に表示されている順序での編集操作)に名前を付けて保存します。 |
| C | 記録済み手順から追加 | 保存済みの変更手順の一覧から選択した変更手順を追加します。 |
| D | ここまでの編集を更新 | グラフやデータを表示している場合、編集操作の結果は画面上に反映されません。このボタンをクリックすると、一覧表示されている編集操作の結果を画面に反映します。 |
データ可視化
データ可視化では、さまざまな角度でデータを分析し、データの視覚化ができます。これにより、データの相関関係が視覚的に確認でき、トレーニングデータ各因子の要不要の判断ができます。また、可視化したデータをトレーニングデータに取り込んだりもできます。
データ可視化は、データ可視化タブ(❶)でできます。
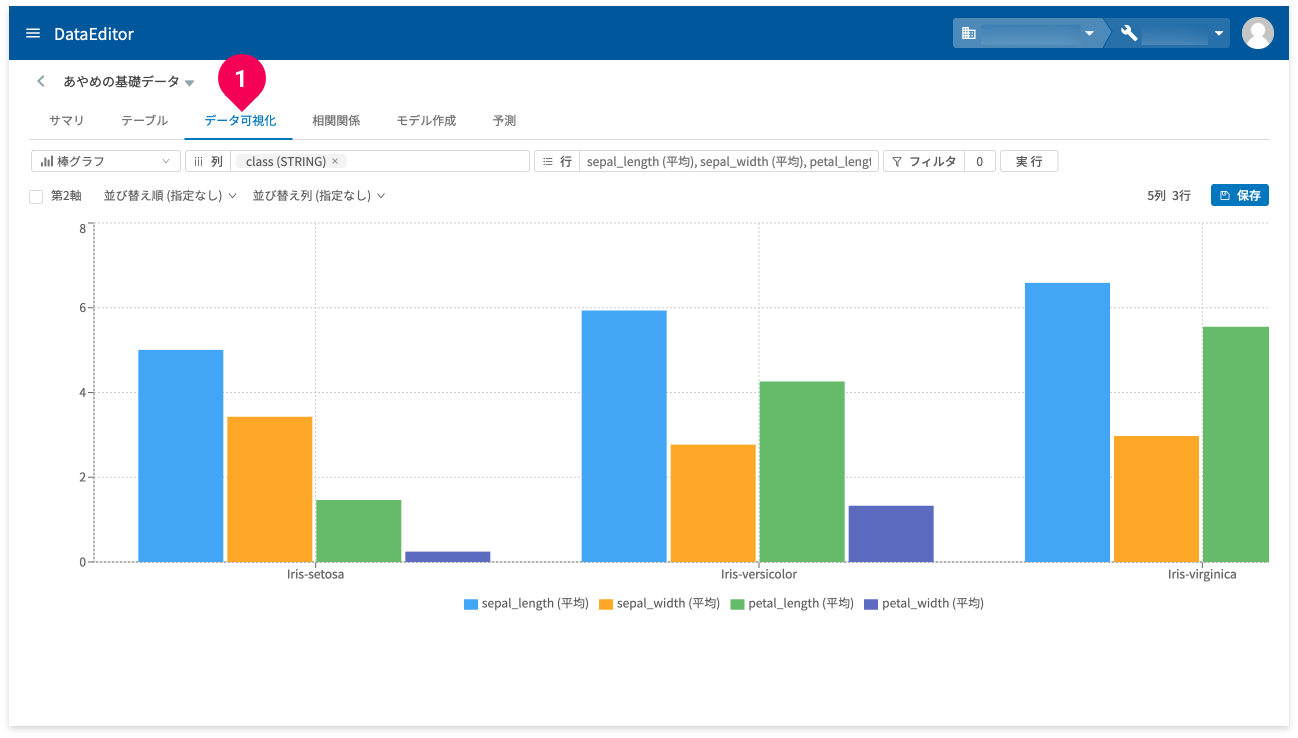
データ可視化のおおまかな流れは以下のとおりです。
- 画面左上の[データ可視化]をクリック
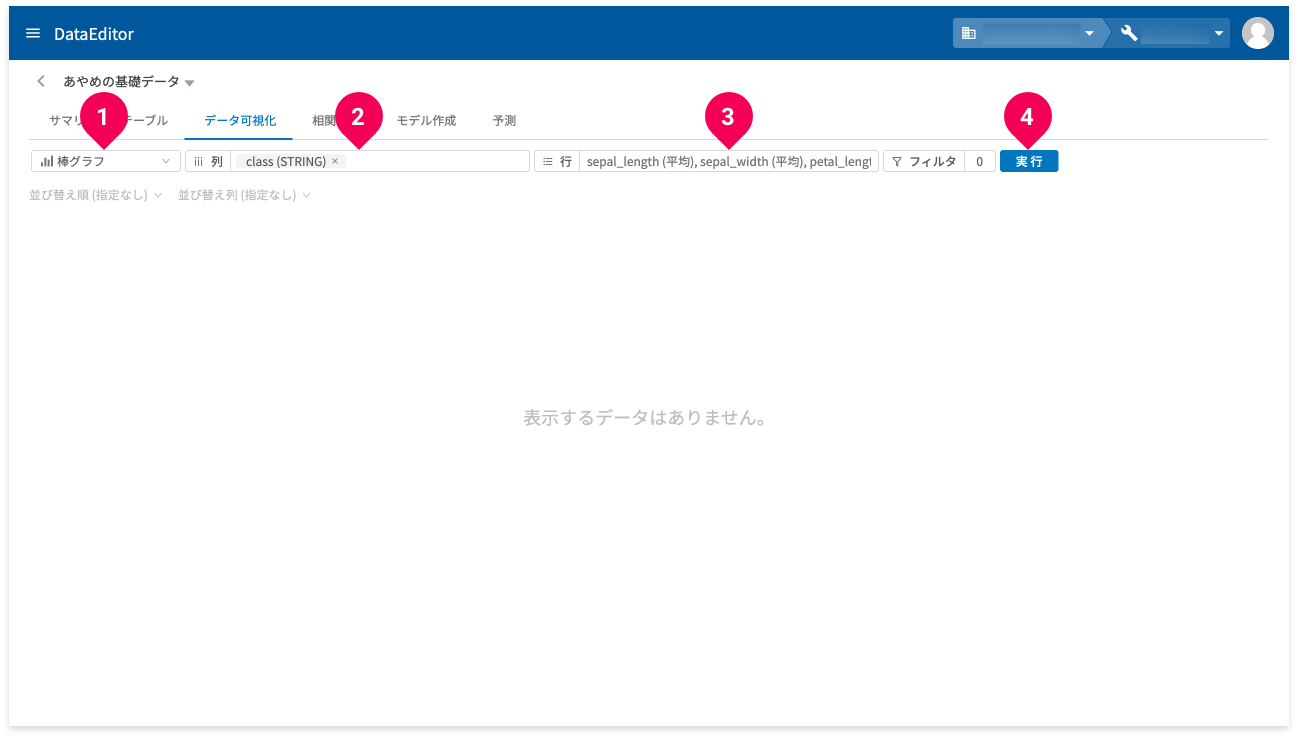
- グラフの種類を以下から選択
- テーブル
- 棒グラフ
- 線グラフ
- 複合グラフ
- エリア
- 円グラフ
- 散布図
- 混同行列
- ベクトル
- 列を選択(列のフィールドをクリックすると選択肢が表示される)
- 行を選択(行のフィールドをクリックすると選択肢が表示される)
- [実行]ボタンをクリック
info_outline列の入力フィールドをクリックすると、選択肢をディメンションとメジャーにグループ分けして表示します。ディメンションには、項目の型が文字列や日付などの定性的数値が含まれます(データの分類や区分に利用可能)。メジャーには、項目の型が数値などの定量的な値が含まれます(集計可能)。
しばらくすると棒グラフが表示されます。
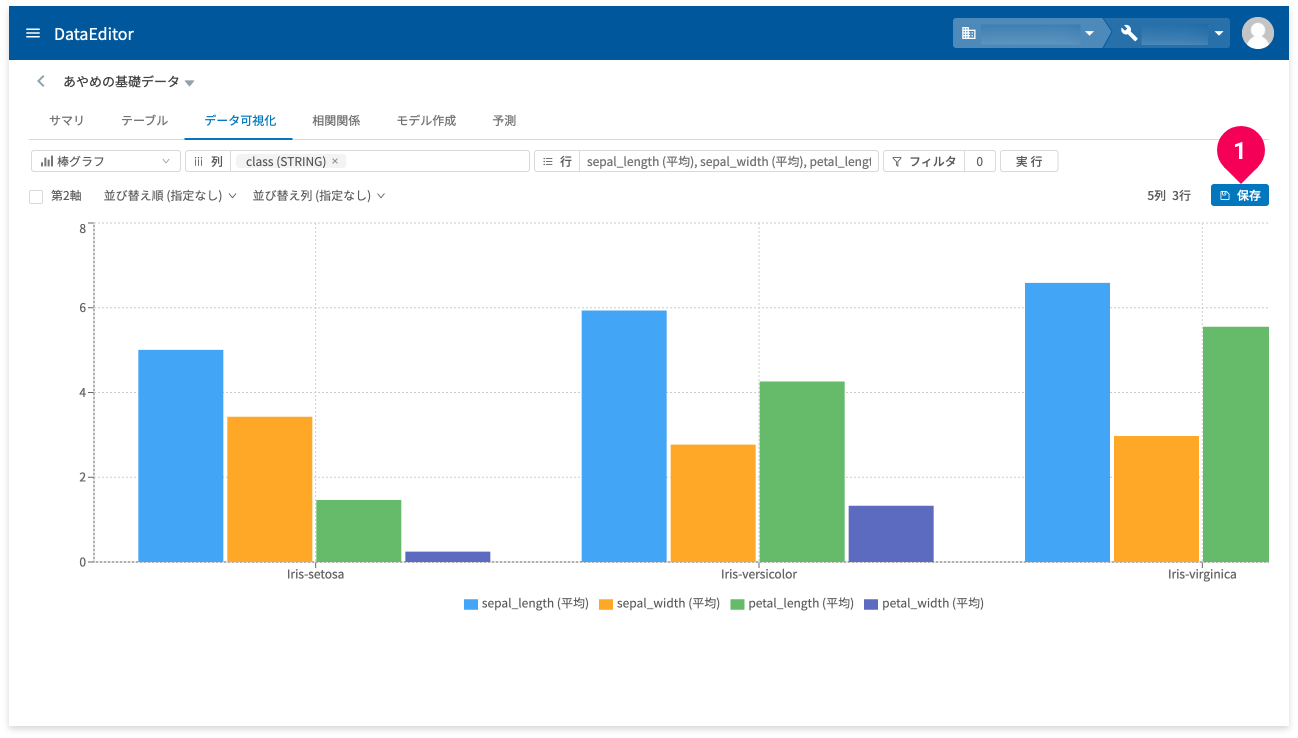
[保存]ボタン(❶)をクリックすると、可視化結果をBigQueryのテーブルに保存できます。
相関関係
相関関係では、データ中の選択した列同士の相関係数を求めます。これにより、データの相関関係が視覚的に確認でき、トレーニングデータ各因子の要不要の判断ができます。
相関係数の算出対象となる列の型は、INTEGER・FLOAT・NUMERIC・STRING・BOOLEANのみです。STRING型は、文字列列挙型として扱います(数量を表すデータの場合は、あらかじめ数値型に変換してください)。BOOLEAN型は数値に変換して変換係数を求めます。
info_outline相関係数の結果内のSTRING型の列名は、[STRING型の列名]_[各文字列列挙値]という形式で表示されます(列名がaで、値が "foo"・"bar"・"baz"の場合は a_foo・a_bar・a_baz)。また、文字列列挙の値が英数字以外の文字を含む場合、[各文字列列挙値]の部分は英数字のみ抽出して組み立てます。使える文字が1文字もない場合や重複する場合には、通し番号を付与します。
相関関係は、相関関係タブでできます。
相関関係の使い方は以下のとおりです。
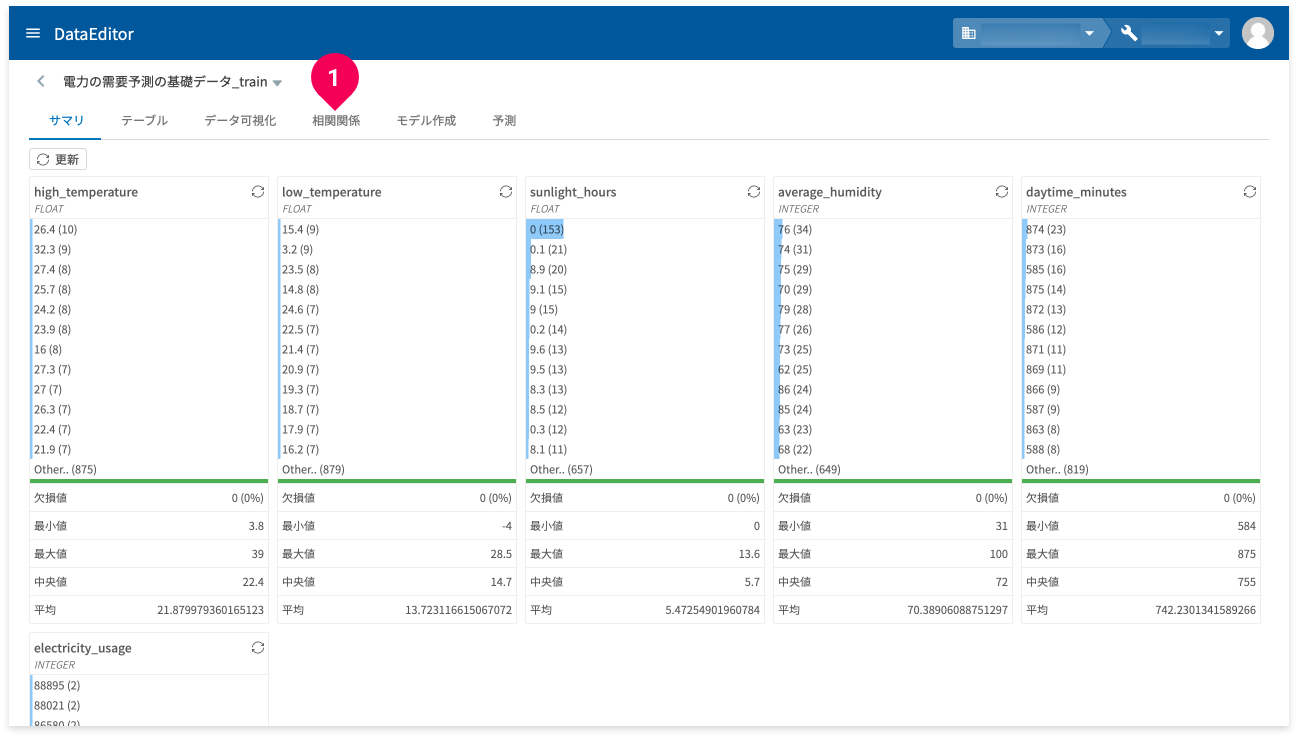
画面左上の[相関関係](❶)をクリックします。
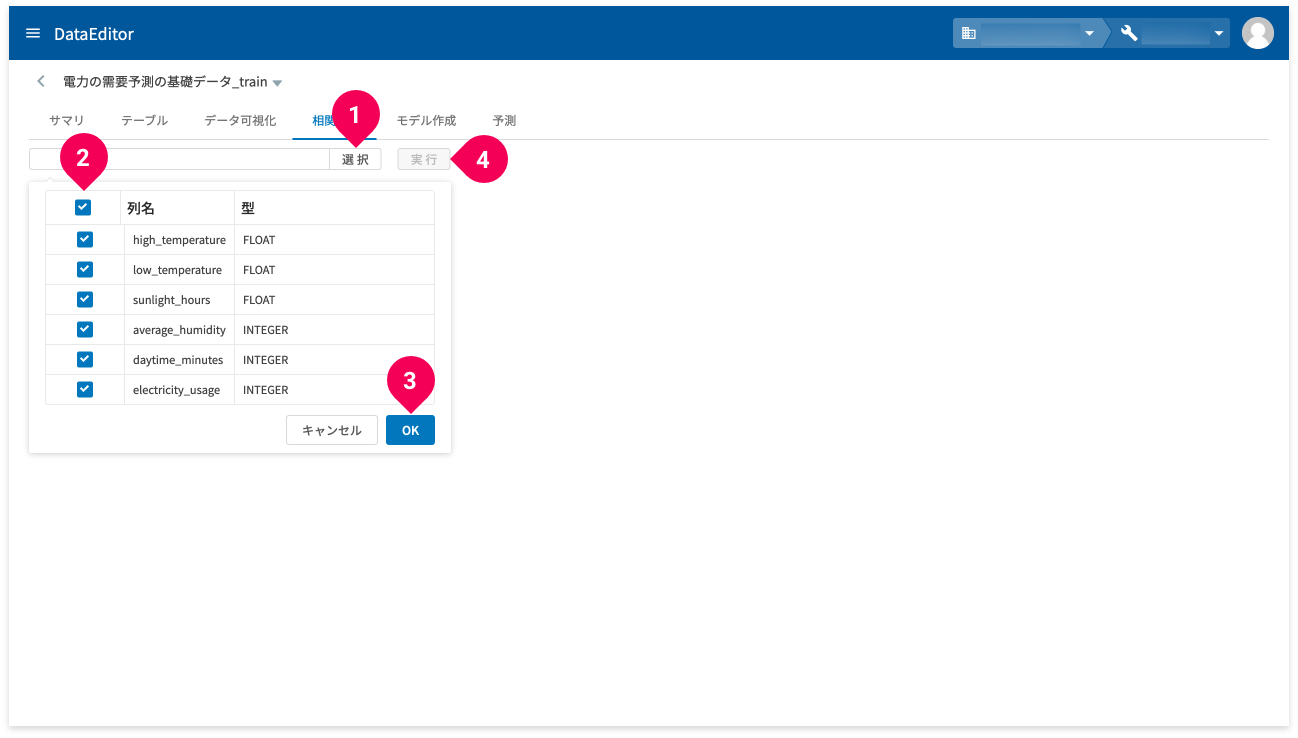
- [選択]ボタンをクリック(❶)
- 相関係数を求める列を複数選択(❷)
- [OK]ボタンをクリック(❸)
- [実行]ボタンをクリック(❹)
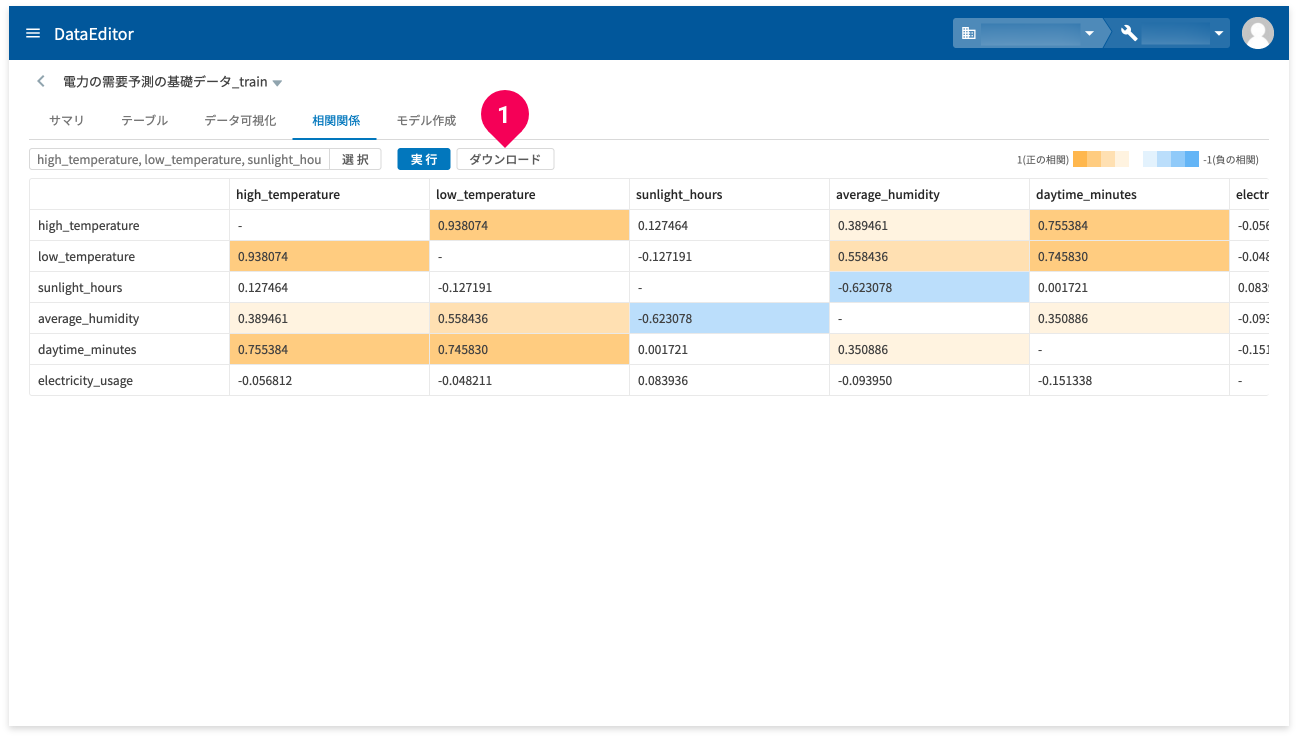
相関関係が係数の値に応じて、色つきで視覚的に表示されます。
[実行]ボタン横の[ダウンロード]ボタン(❶)をクリックすると、上記の表をCSV形式のデータでダウンロードできます。
- 表中の-は1に置換して出力
- 各係数は生のデータを出力(画面上の数値は小数点以下6桁までに補正されている)
モデル作成
モデル作成で、対応するモデルの種類は、以下のとおりです。
| モデルの種類 | モデル |
|---|---|
| 回帰 | 線形回帰(回帰) |
| AutoML(回帰) | |
| XGBoost(回帰) | |
| Deep Neural Network(回帰) | |
| 分類 | ロジスティック回帰(分類) |
| AutoML(分類) | |
| XGBoost(分類) | |
| Deep Neural Network(分類) | |
| クラスタリング | k-平均法 |
| 時系列 | ARIMA+(時系列)【限定公開】 |
重要
限定公開モデルの利用にあたっては、ライセンス購入申請が必要です。限定公開のモデルを利用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
モデルの作成について詳しくは、「DataEditorによるモデルの作成と予測」を参照願います。
予測
予測では、DataEditorにインポートしたデータを使った予測ができます。
予測について詳しくは、「DataEditorによるモデルの作成と予測」を参照願います。
テーブル結合
テーブル結合では、以下のデータとの結合ができます。
- DataEditor内の他のデータ
- 気象データ
- カレンダーデータ
テーブル結合は、ホーム画面からとデータ編集画面のテーブルタブから実行できます。
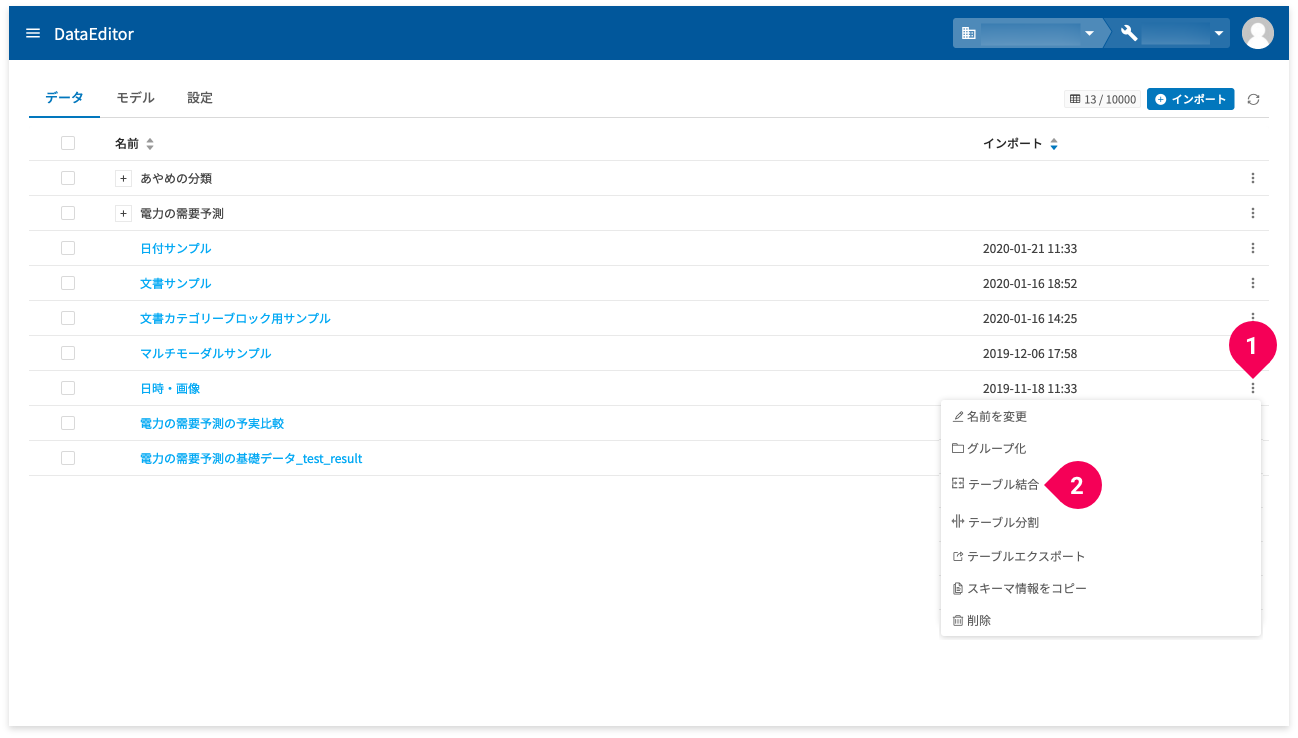
ひとつは、ホーム画面のmore_vert(❶)をクリックして表示されるメニューから[テーブル結合](❷)をクリックして実行します。
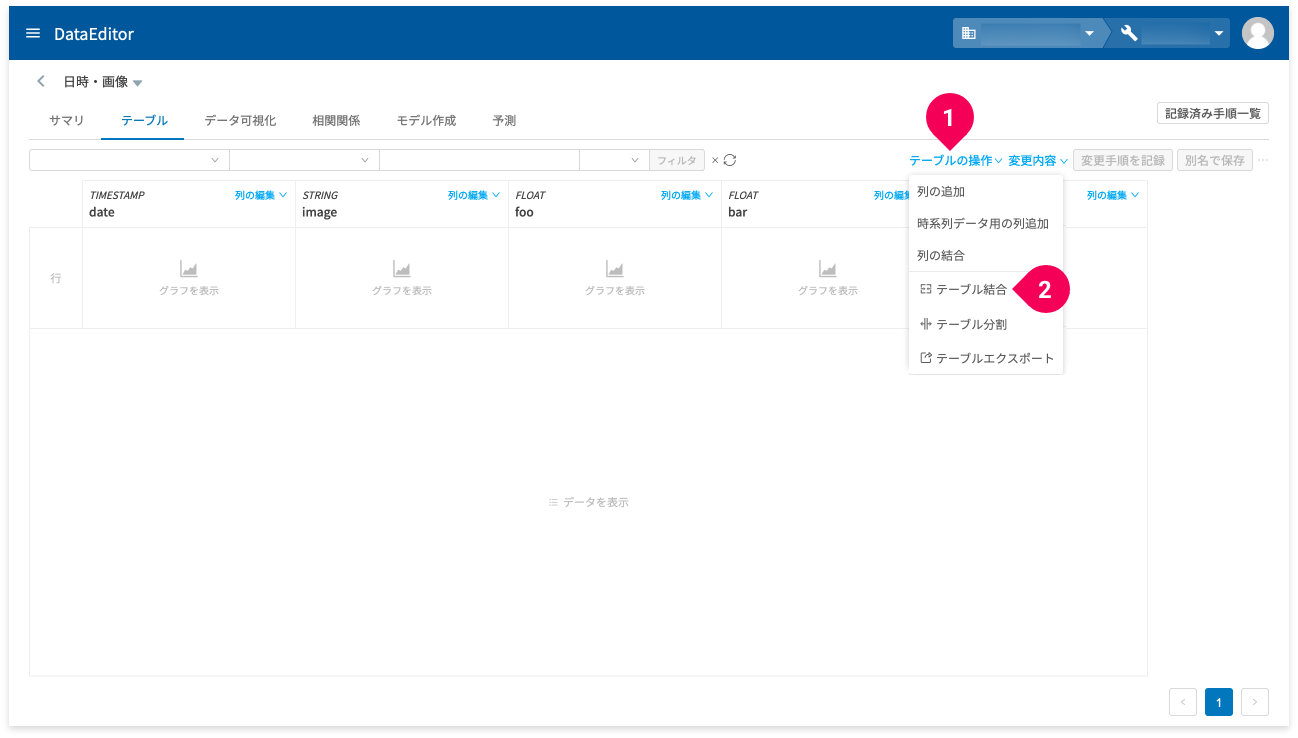
もうひとつは、データ編集画面のテーブルタブ内の[テーブルの操作](❶)をクリックして表示されるメニューから[テーブル結合](❷)をクリックすることでも実行できます。
DataEditorのデータと結合
DataEditor内の他のデータと結合する場合は、以下の手順を踏みます。
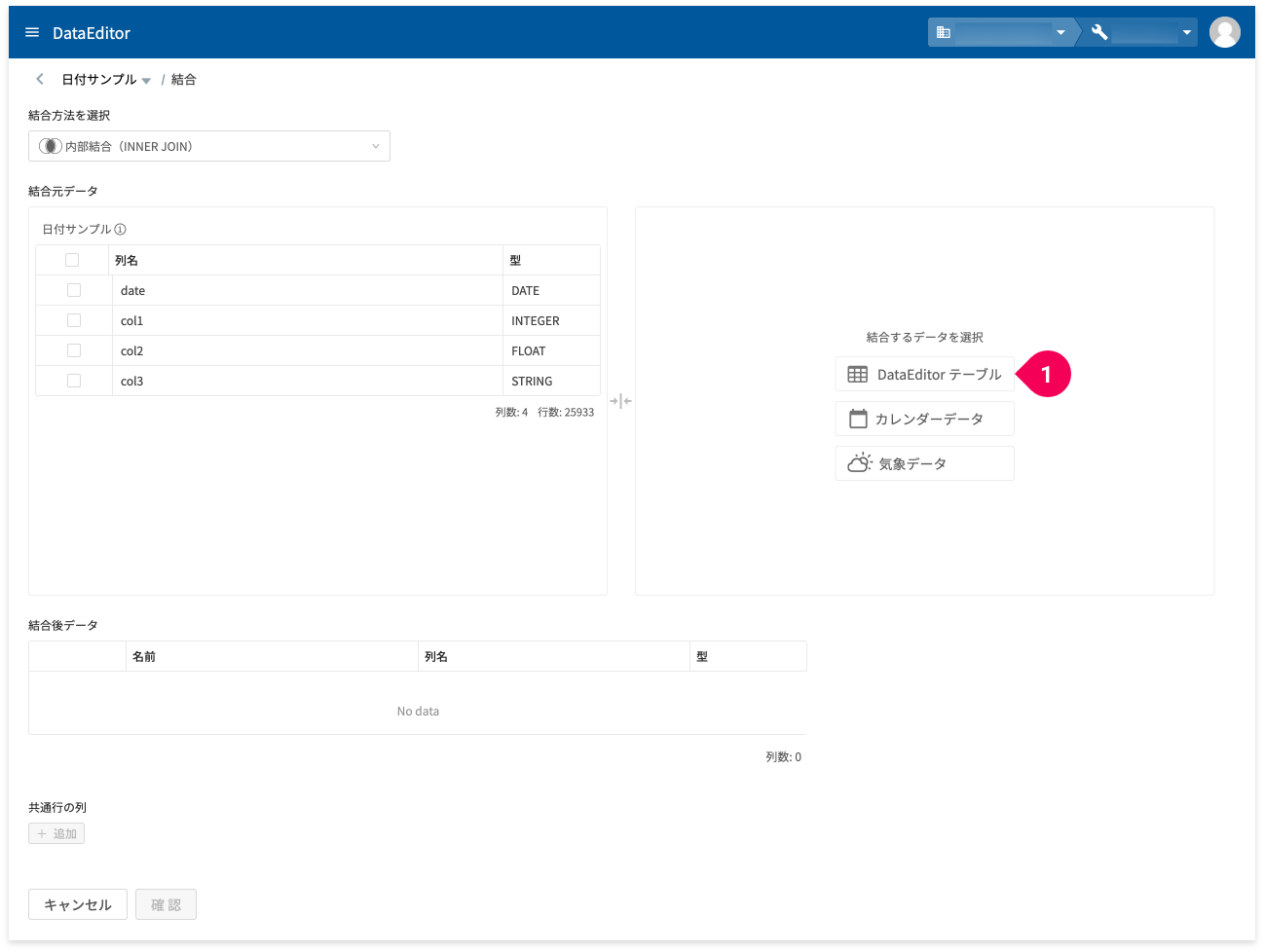
[DataEditorテーブル]ボタン(❶)をクリックします。
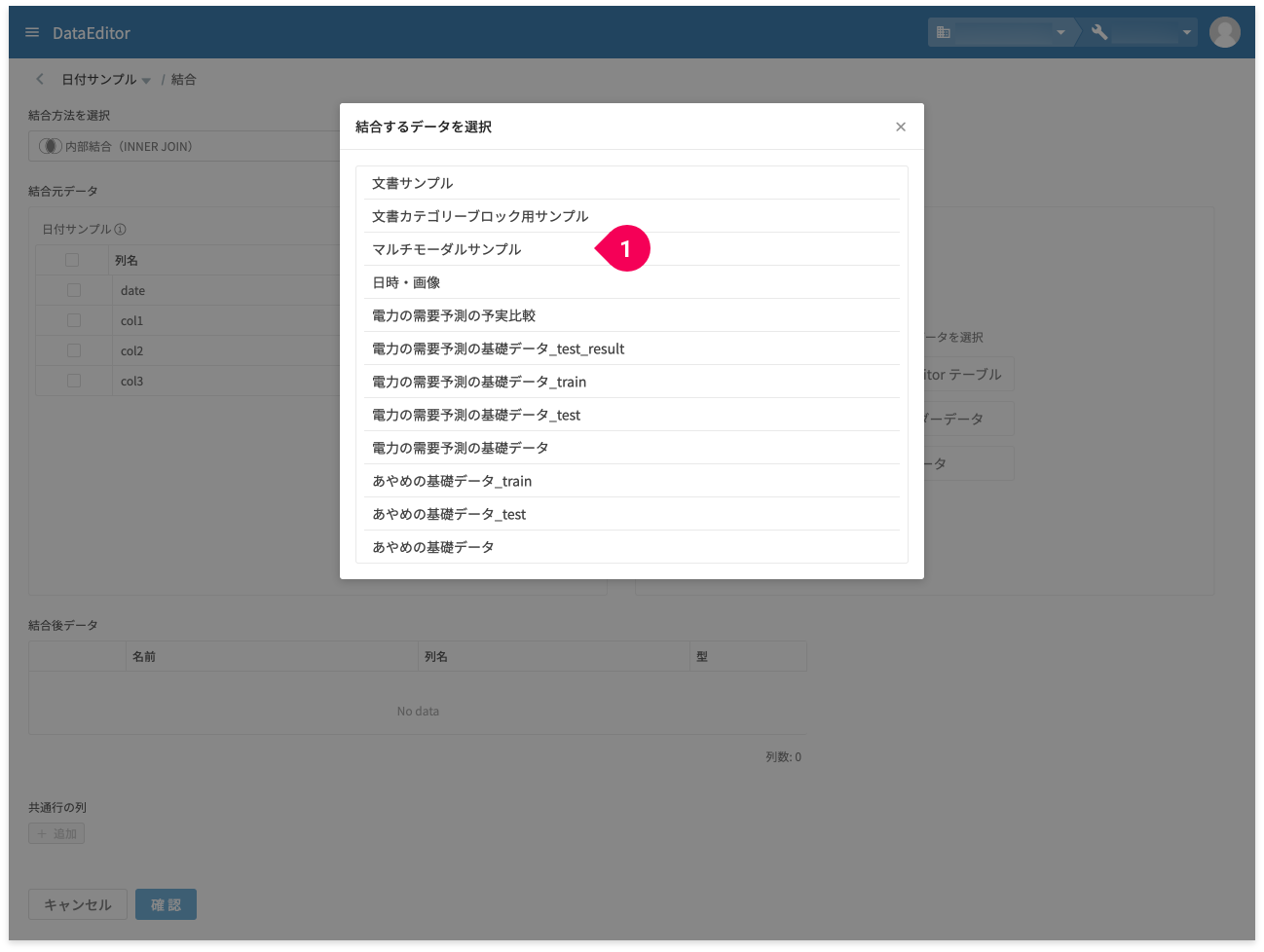
結合するデータ(❶)をクリックします。
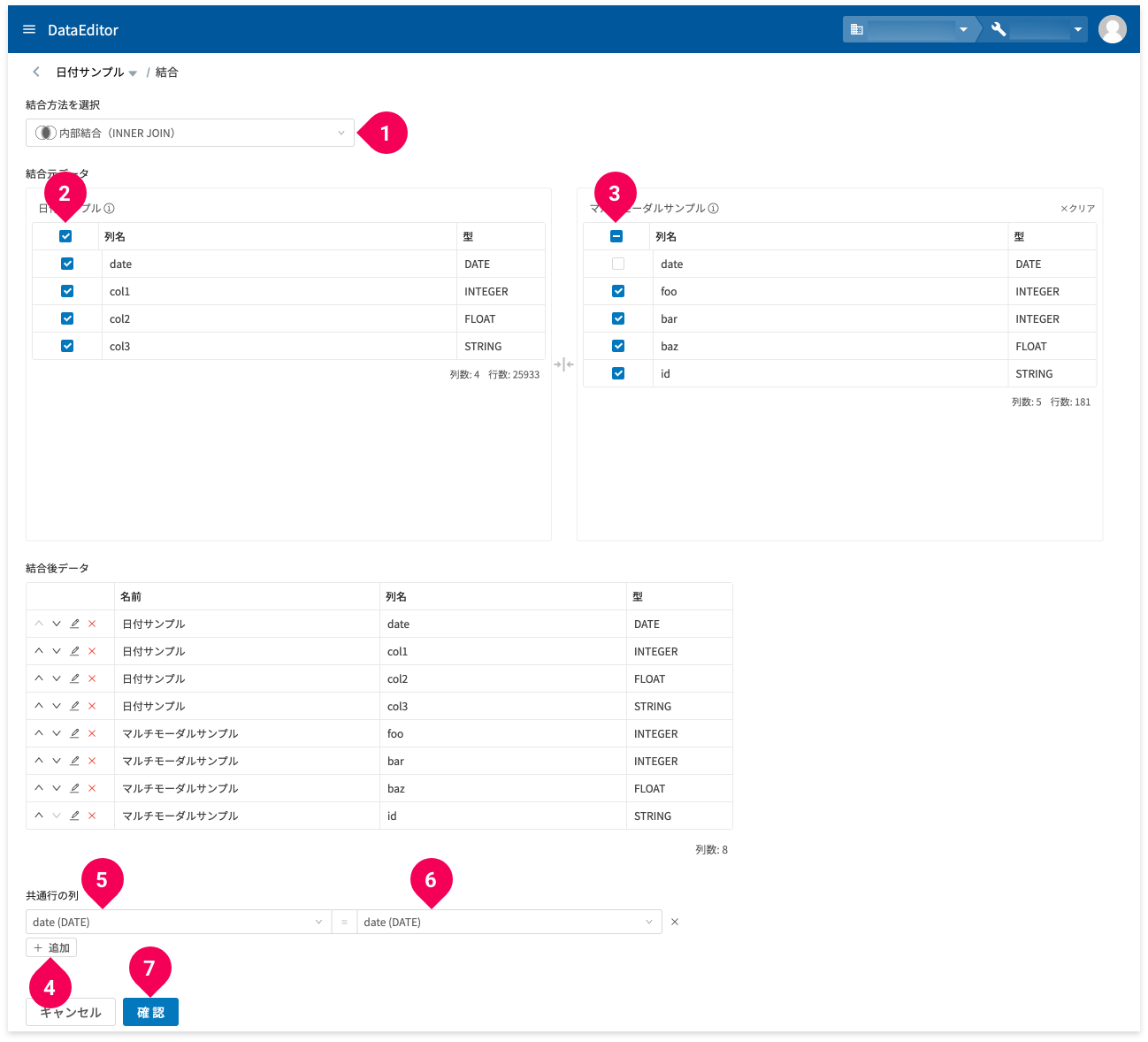
- 結合方法を以下から選択
- 内部結合(INNER JOIN)
- 左外部結合(LEFT OUTER JOIN)
- 右外部結合(RIGHT OUTER JOIN)
- 和結合(UNION ALL)
- 結合元データから結合する列をチェック
- もう一方のデータから結合する列をチェック
- [追加]ボタンをクリック
- 共通行の列をクリック
- 共通行の列をクリック
- [確認]ボタンをクリック

- 名前を入力
- データセットIDをクリック
- テーブルIDを入力
- [結合]ボタンをクリック
info_outline結合実行中に[キャンセル]ボタンをクリックすると、結合をキャンセルできます。

[戻る]ボタン(❶)をクリックします。しばらくすると、結合されたデータがテーブル一覧に表示されます。
気象データと結合
気象データとの結合では、全国154か所の観測所が持つ日ごともしくは時間ごとの気象データと結合できます。
- 結合元のデータに緯度経度の情報がある場合は、複数の観測所の気象データと結合が可能
どの観測所と結合するかは、結合元データの緯度経度に近い観測所が選択される - 結合元のデータに緯度経度の情報がない場合は、1つの観測所の気象データと結合が可能
どの観測所と結合するかは、観測所の一覧から利用者が選択する
気象データと結合するためは、結合元データに日時(DATE型・DATETIME型・TIMESTAMP型)の列が必要です。気象データは、この日時の列をキーにして結合します。
未来の日時を指定すると、予報データと結合できます。結合可能な予報データは、現在から7日先までです。
info_outline日時がDATE型の場合は、日ごとの気象データとのみ結合が可能です。
error気象データは有料です。DataEditorのライセンスとは別ライセンスです。利用にあたっては、DataEditorとは別に気象データのライセンスが必要です。気象データの利用にあたっては、設定画面からライセンスの見積もり依頼をしてください。
気象データを結合する手順は、以下のとおりです。
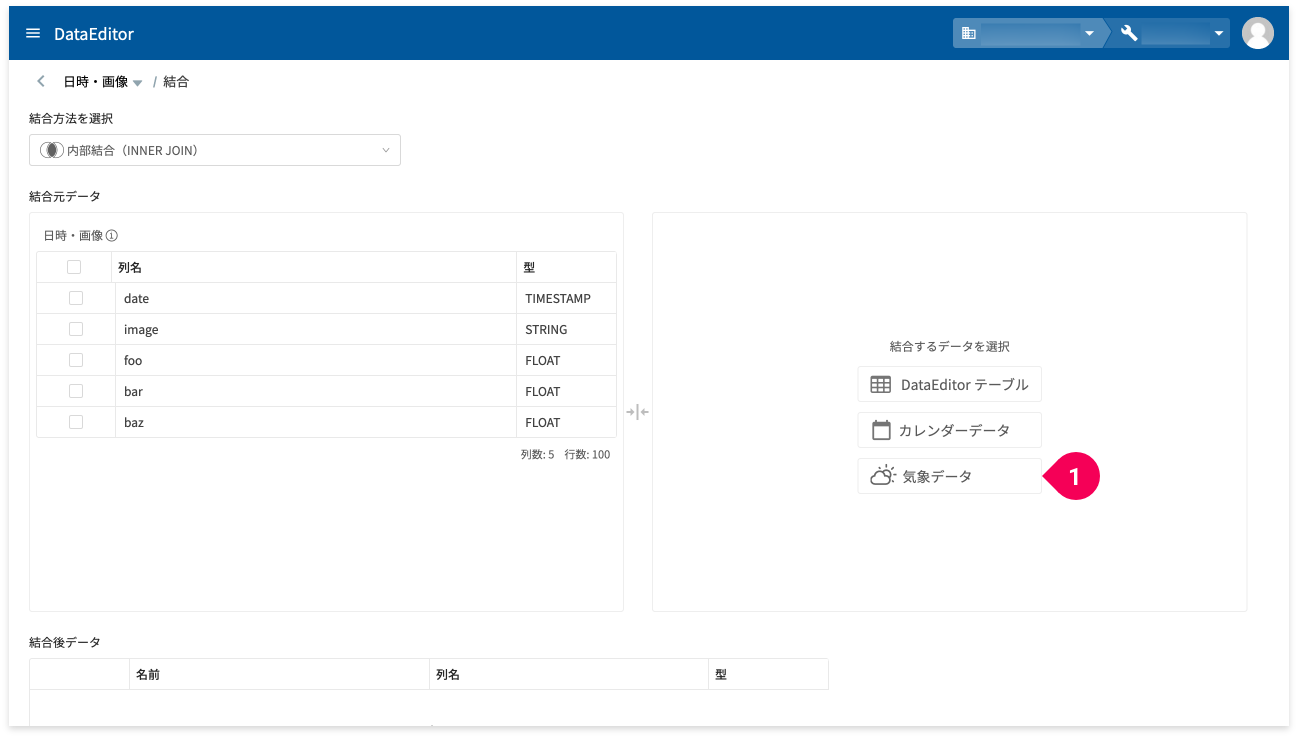
- [気象データ]ボタンをクリック
結合元データの緯度経度の情報を元に近い観測所の気象データと結合する場合は、以下のように操作します。
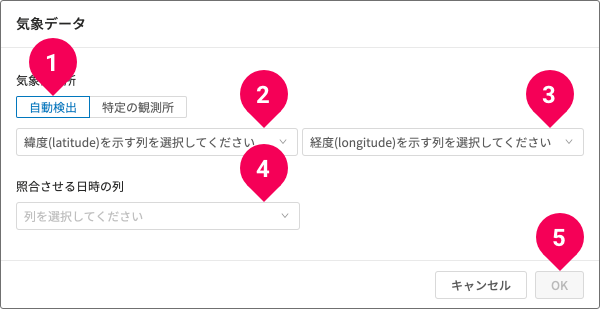
- [自動検出]をクリック
すでに選択済みの場合はそのまま - 統合元データの緯度の列をクリック
- 統合元データの経度の列をクリック
- 結合元の照合させる日時の列をクリック
- [OK]ボタンをクリック
指定した1つの観測所の気象データと結合する場合は、以下のように操作します。
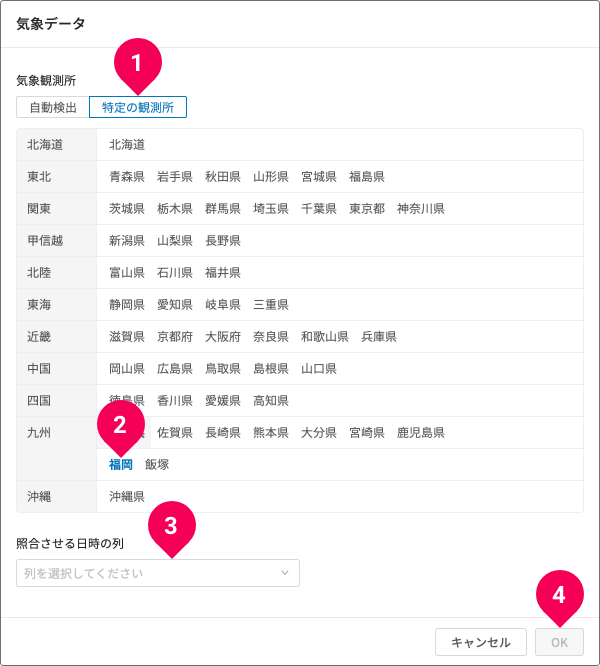
- [特定の観測所]をクリック
- 気象観測所を1つ選択
- 結合元の照合させる日時の列をクリック
- [OK]ボタンをクリック
[自動検出]の場合も[特定の観測所]の場合も以降の操作は同じです。以下の手順で操作を進めます。
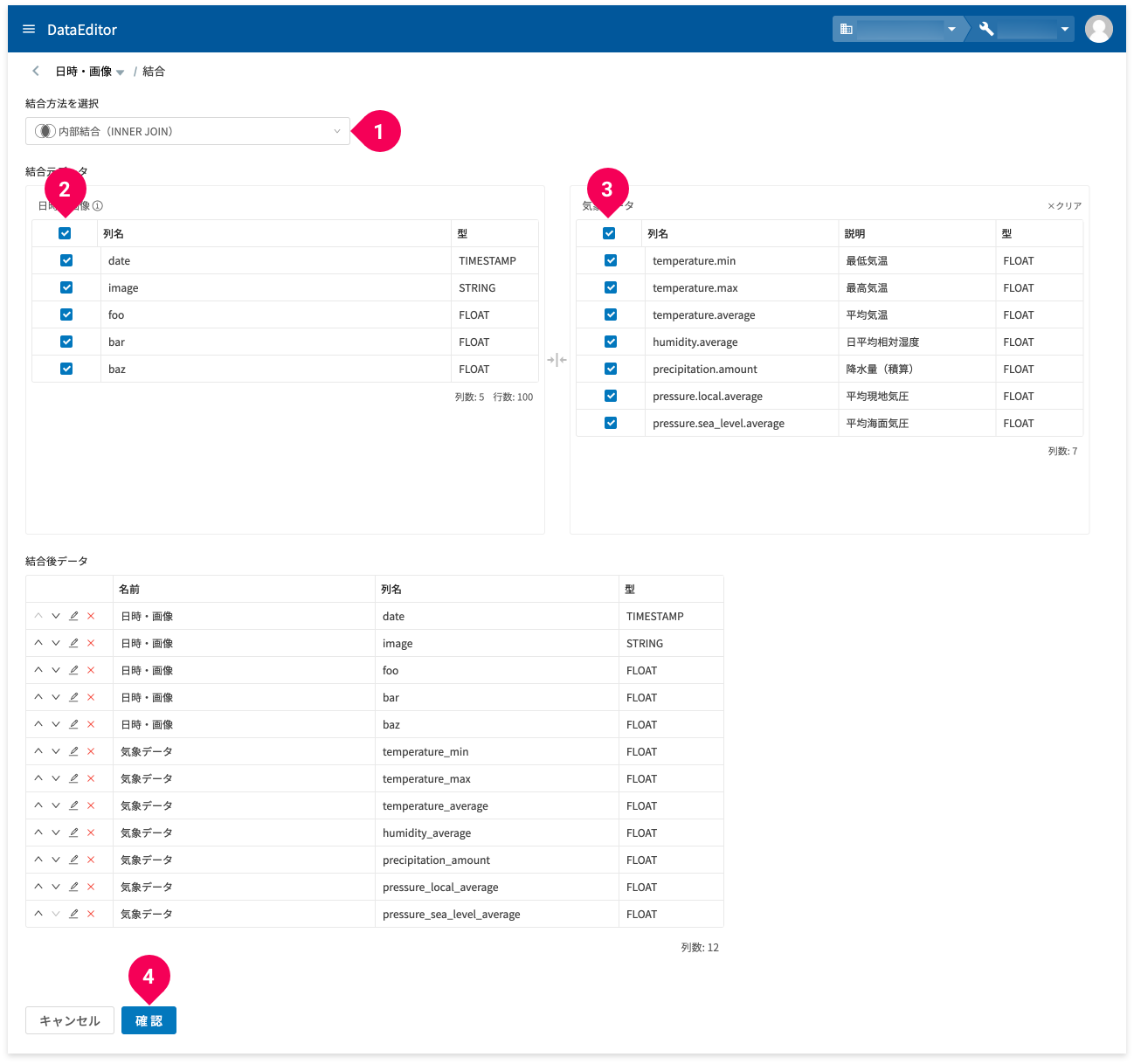
- 結合方法を以下から選択
- 内部結合(INNER JOIN)
- 左外部結合(LEFT OUTER JOIN)
- 右外部結合(RIGHT OUTER JOIN)
- 和結合(UNION ALL)
- 結合元データから結合する列をチェック
- 気象データから結合する列をチェック
- [確認]ボタンをクリック

- 名前を入力
- データセットIDをクリック
- テーブルIDを入力
- [結合]ボタンをクリック
info_outline結合実行中に[キャンセル]ボタンをクリックすると、結合をキャンセルできます。

- [戻る]ボタンをクリック
しばらくすると、結合されたデータがテーブル一覧に表示されます。
カレンダーデータと結合
カレンダーデータとの結合では、DataEditorの既存テーブルと日付・曜日・国民の祝日・銀行の休日などのカレンダーデータと結合ができます。
カレンダーデータと結合するには、結合元データにDATE型の日付の列が必要です。カレンダーデータは、この日付の列をキーにして結合します。
カレンダーデータを結合する手順は、以下のとおりです。
![[カレンダーデータ]ボタンをクリックする様子](https://www.magellanic-clouds.com/blocks/docs/wp-content/uploads/2020/09/data_editor_dataedtor_67_ja.png)
- [カレンダーデータ]ボタンをクリック
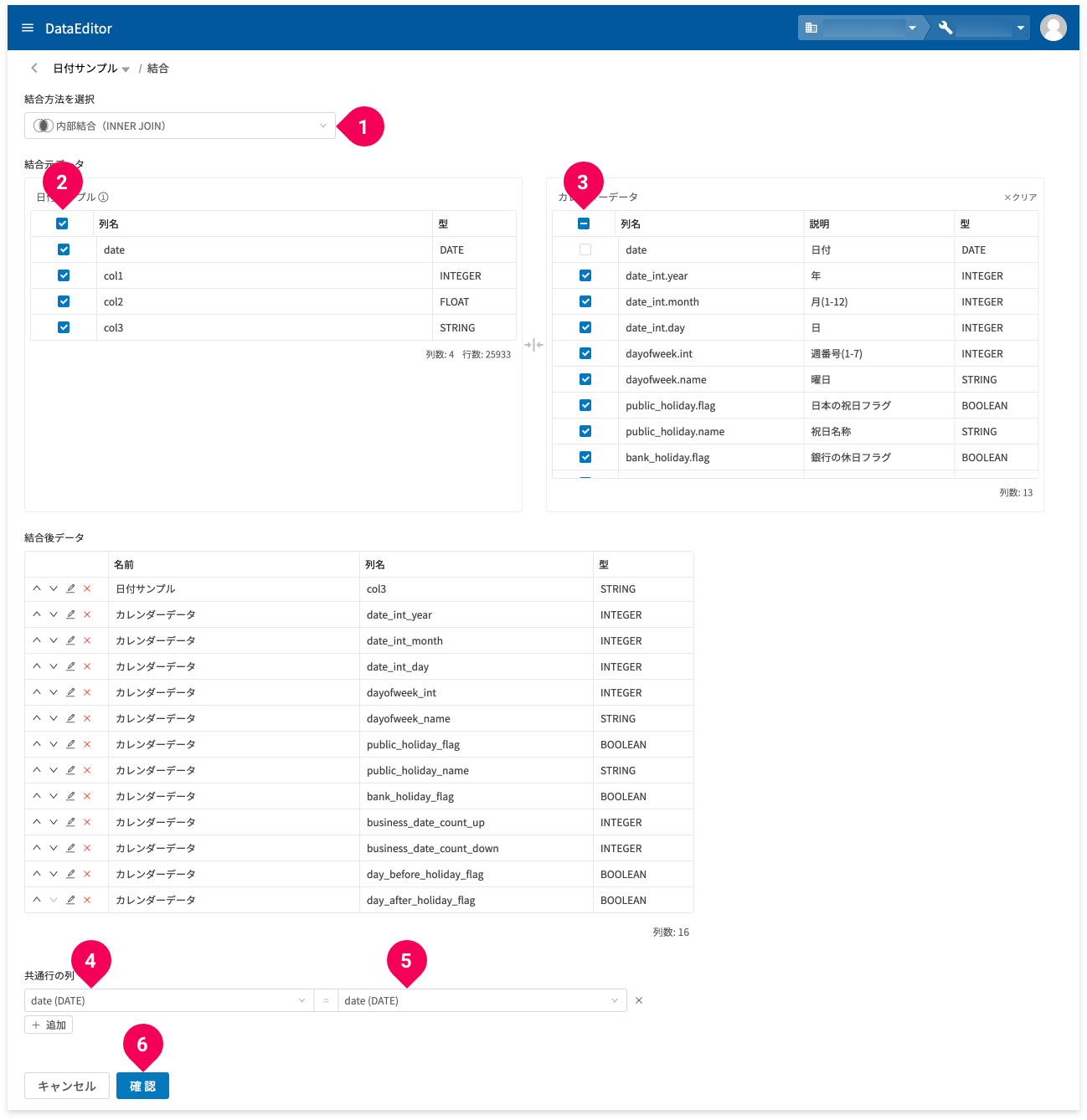
- 結合方法を以下から選択
- 内部結合(INNER JOIN)
- 左外部結合(LEFT OUTER JOIN)
- 右外部結合(RIGHT OUTER JOIN)
- 和結合(UNION ALL)
- 結合元データからカレンダーデータと共通する列をチェック
- カレンダーデータから結合元データと共通する列をチェック
- 結合元データから共通行の列をクリック
- カレンダーデータから共通行の列をクリック
- [確認]ボタンをクリック

- 結合結果に付ける名前を指定
- 結合結果の保存先となるデータセットIDを指定
- 結合結果の保存先となるテーブルIDを指定
- [結合]ボタンをクリック
info_outline結合実行中に[キャンセル]ボタンをクリックすると、結合をキャンセルできます。

[戻る]ボタンをクリックすると完了です。結合されたデータがテーブル一覧に表示されます。
テーブル分割
テーブル分割では、データを2つに分割できます。分割は、指定した比率で分割する方法(データの内容はランダムに振り分けられる)と、データ内各列の値の範囲条件で分割する方法があります。
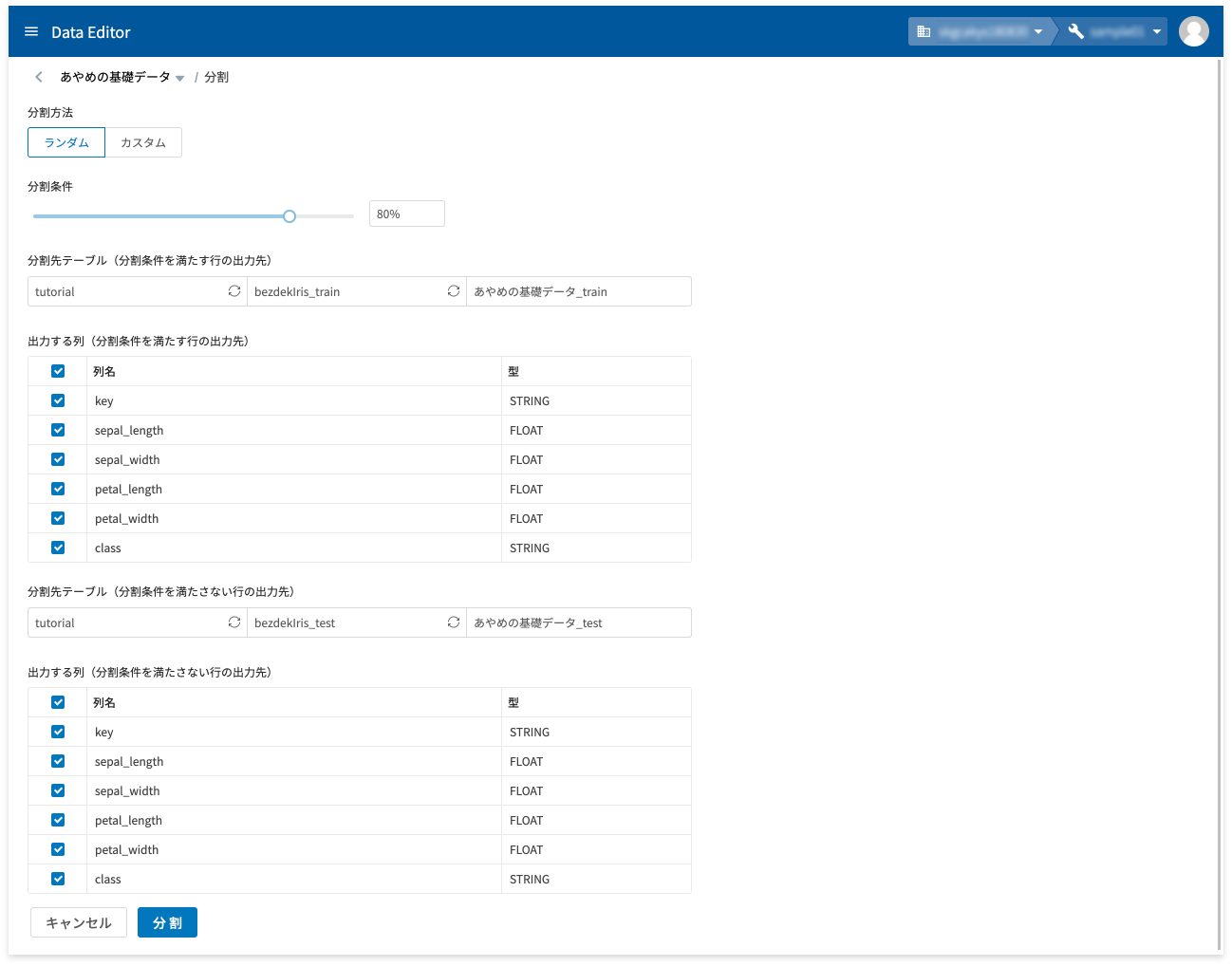
テーブル分割は、ホーム画面からとデータ編集画面のテーブルタブから実行できます。
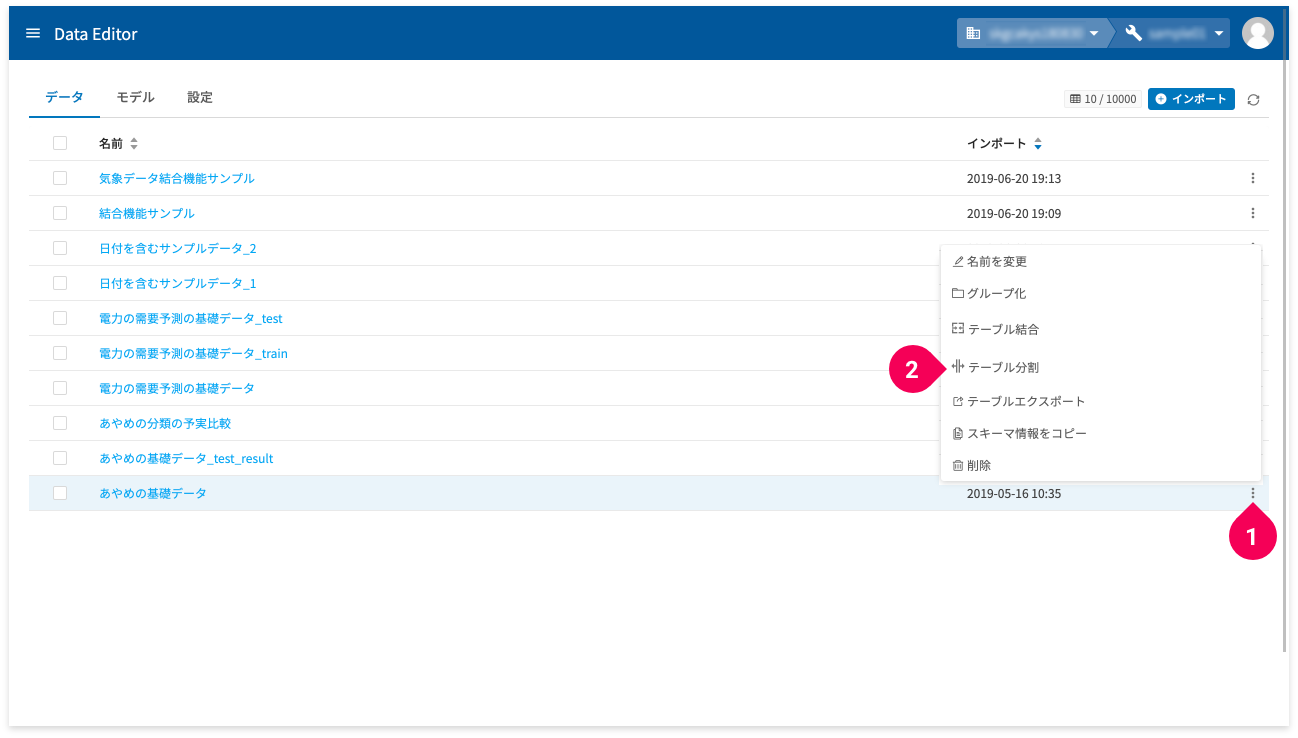
ひとつは、ホーム画面のmore_vert(❶)をクリックして表示されるメニューから[テーブル分割](❷)をクリックして実行します。
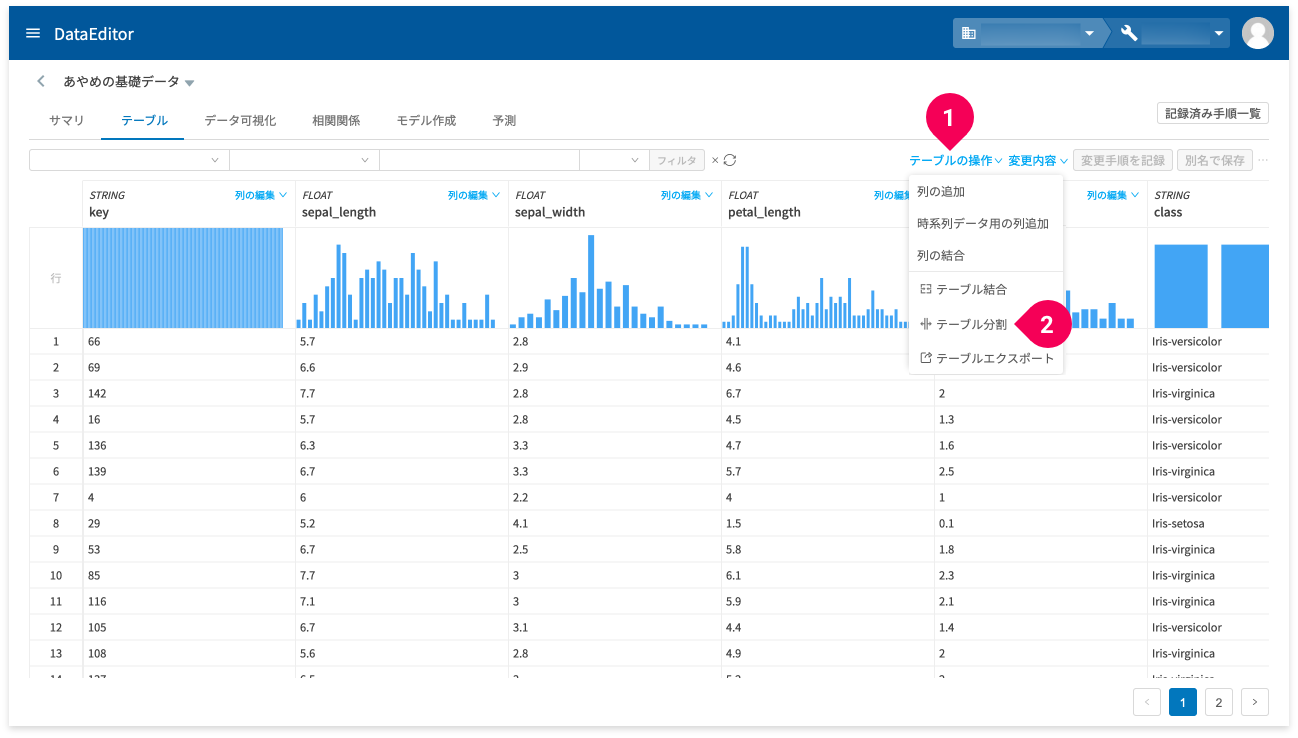
もうひとつは、データ編集画面のテーブルタブ内の[テーブルの操作](❶)をクリックして表示されるメニューから[テーブル分割](❷)をクリックすることでも実行できます。
info_outline分割実行中に、画面中央に表示される[キャンセル]をクリックすると、分割をキャンセルできます。
テーブルエクスポート
テーブルエクスポートでは、データの内容をGCS上にCSV形式もしくはJSON形式のテキストファイルとして書き出すか、BigQueryのテーブルとして書き出すことができます。
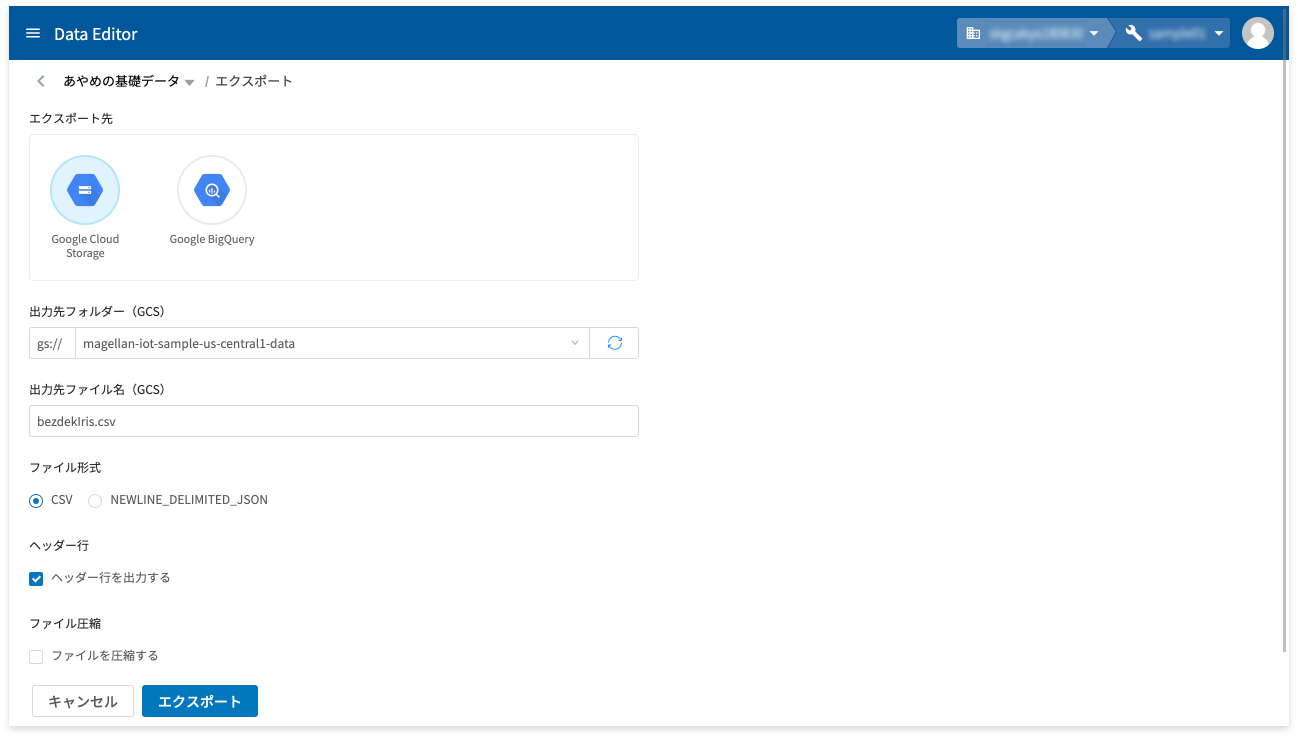
エクスポート先がGCSの場合は、エクスポートの完了画面に、ファイルのダウンロードリンクが表示されます。

このリンク(❶)をマウスの右ボタンでクリックし、表示されるメニューから[名前を付けてリンク先を保存]をクリックすると、PCにファイルがダウンロードできます。
テーブルエクスポートは、ホーム画面からとデータ編集画面のテーブルタブから実行できます。
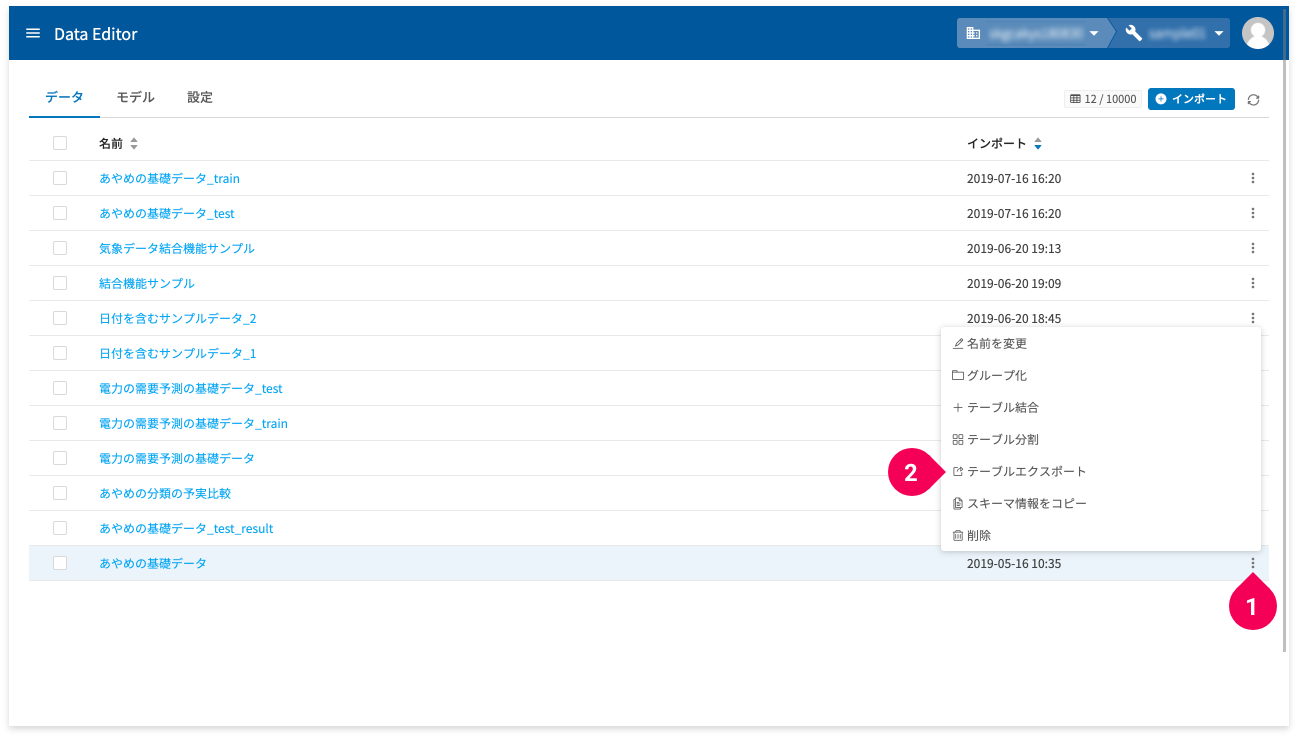
ひとつは、ホーム画面のmore_vert(❶)をクリックして表示されるメニューから[テーブルエクスポート](❷)をクリックして実行します。
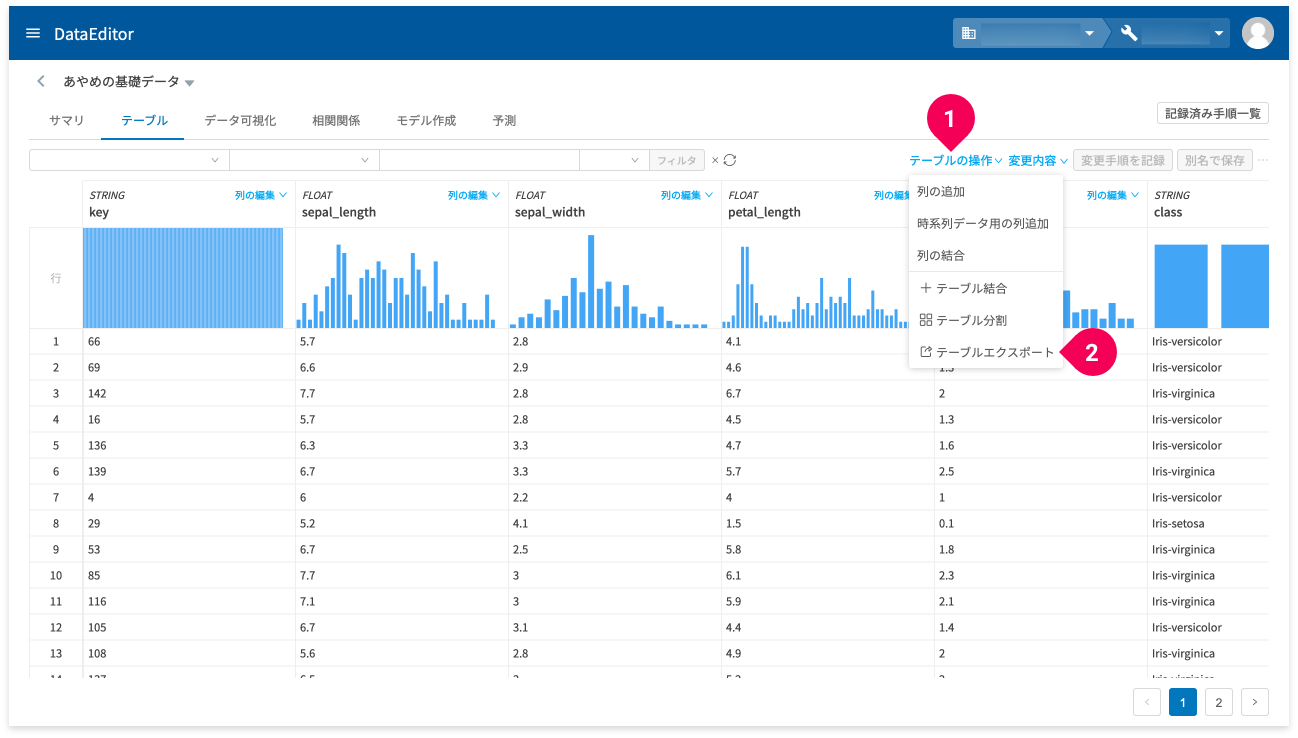
もうひとつは、データ編集画面のテーブルタブ内の[テーブルの操作](❶)をクリックして表示されるメニューから[テーブルエクスポート](❷)をクリックすることでも実行できます。
スキーマ情報のコピー
DataEditorホーム画面の[データ]タブの画面から、データのBigQuery用のスキーマ情報(JSON形式)をクリップボードにコピーできます。このデータは、フローデザイナーの BigQueryカテゴリーブロックの[スキーマ設定]プロパティで利用できます。
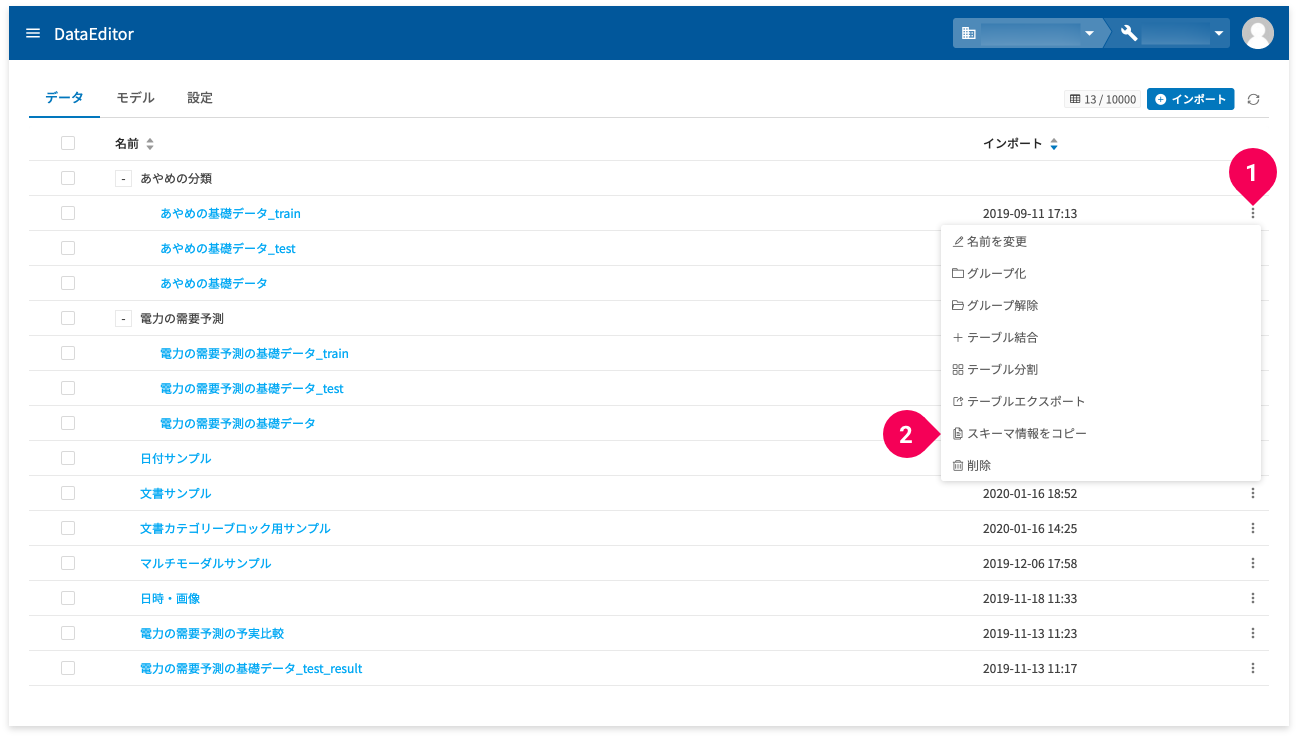
データ一覧のmore_vert(❶)をクリックして表示されるメニューから、[スキーマ情報をコピー](❷)をクリックすると、当該データのスキーマ情報のコピーができます。
削除
DataEditorホーム画面の[データ]タブの画面から、データの削除ができます。
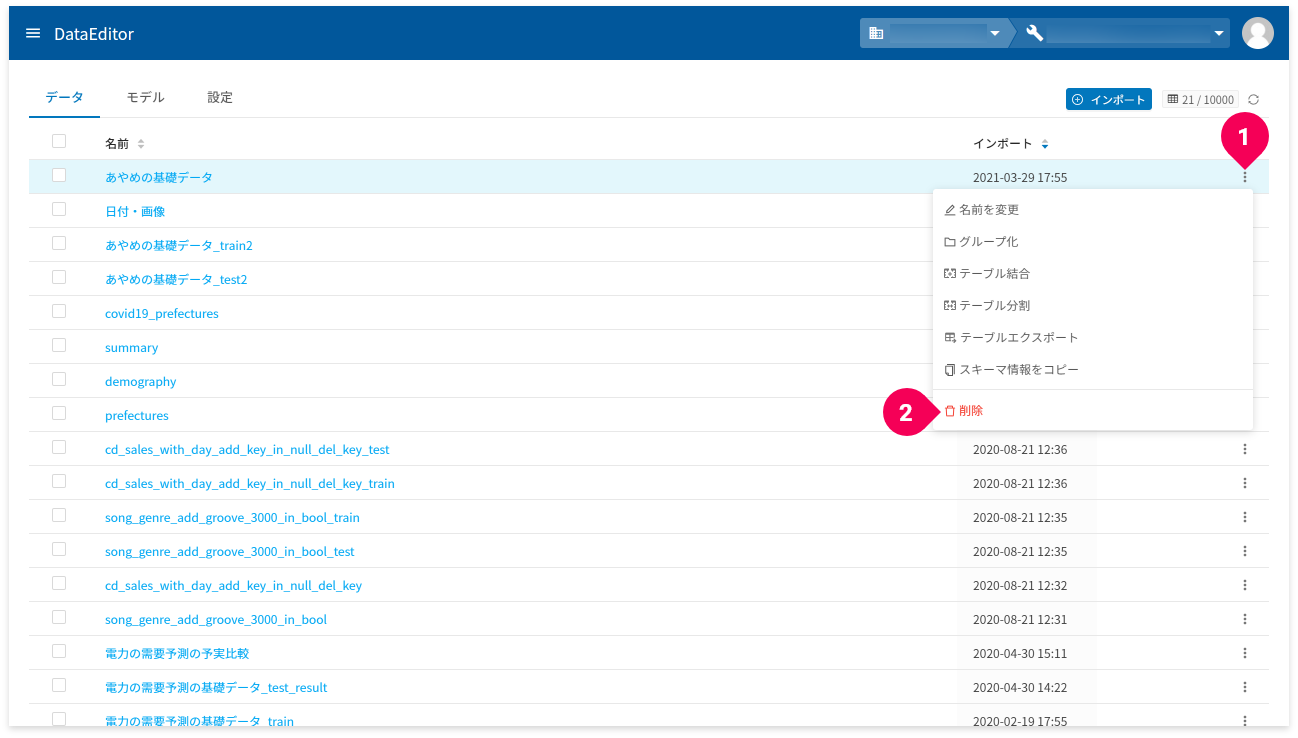
データ一覧のmore_vert(❶)をクリックして表示されるメニューから、[削除](❷)をクリックすると、当該データの削除ができます。
複数のデータをまとめて削除したい場合は、以下の方法でできます。
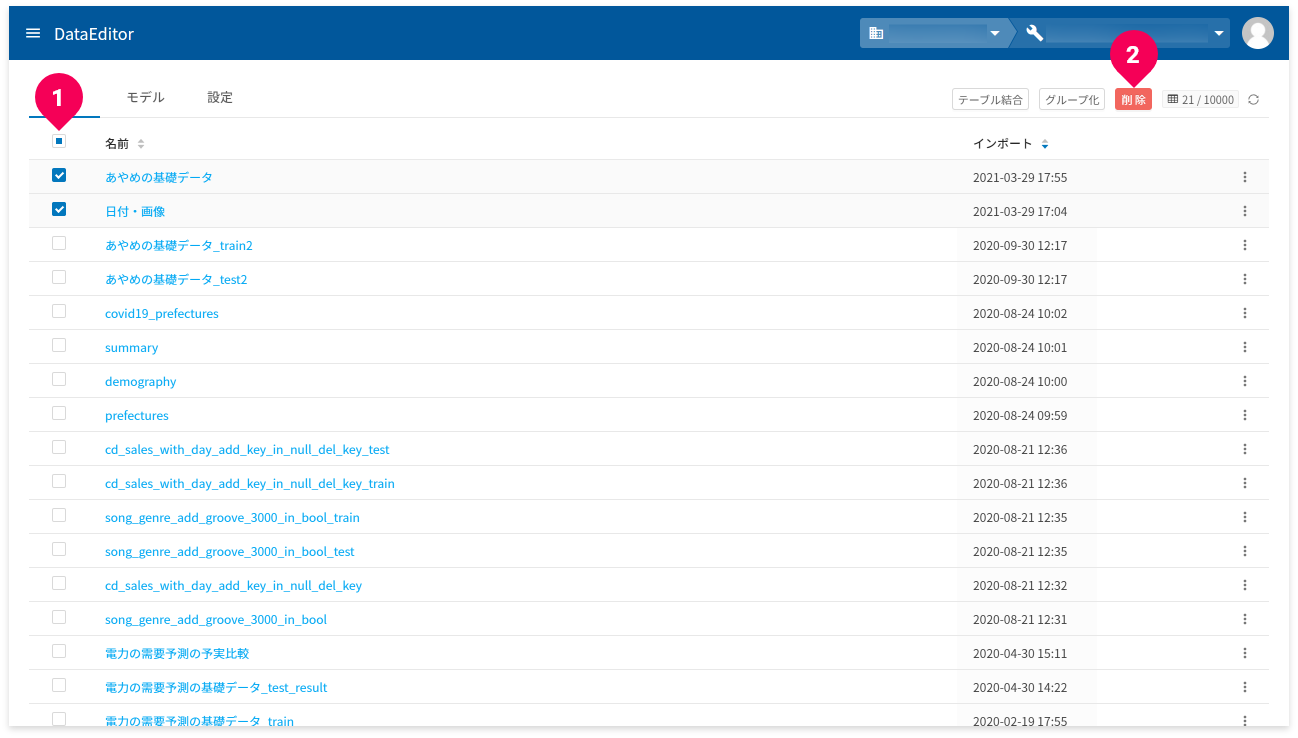
データ一覧から削除したいデータのチェックボックスにチェックを付け(❶)、[削除]ボタン(❷)をクリックすると、当該データの削除ができます。
モデル一覧
DataEditorホーム画面の[モデル]タブの画面では、DataEditorで作成したモデルの一覧が確認できます。この画面では、以下のことができます。
info_outlineモデルの削除では、トレーニング中・適用中・中断中のものは削除できません。
warning本モデル一覧の画面は、2022年01月28日リリース時点のものです。2022年03月03日以降のリリースでは、「保持期限」の列が追加されています(「誤差/正確率」と「作成日時」の間)。
モデル内容の詳細確認
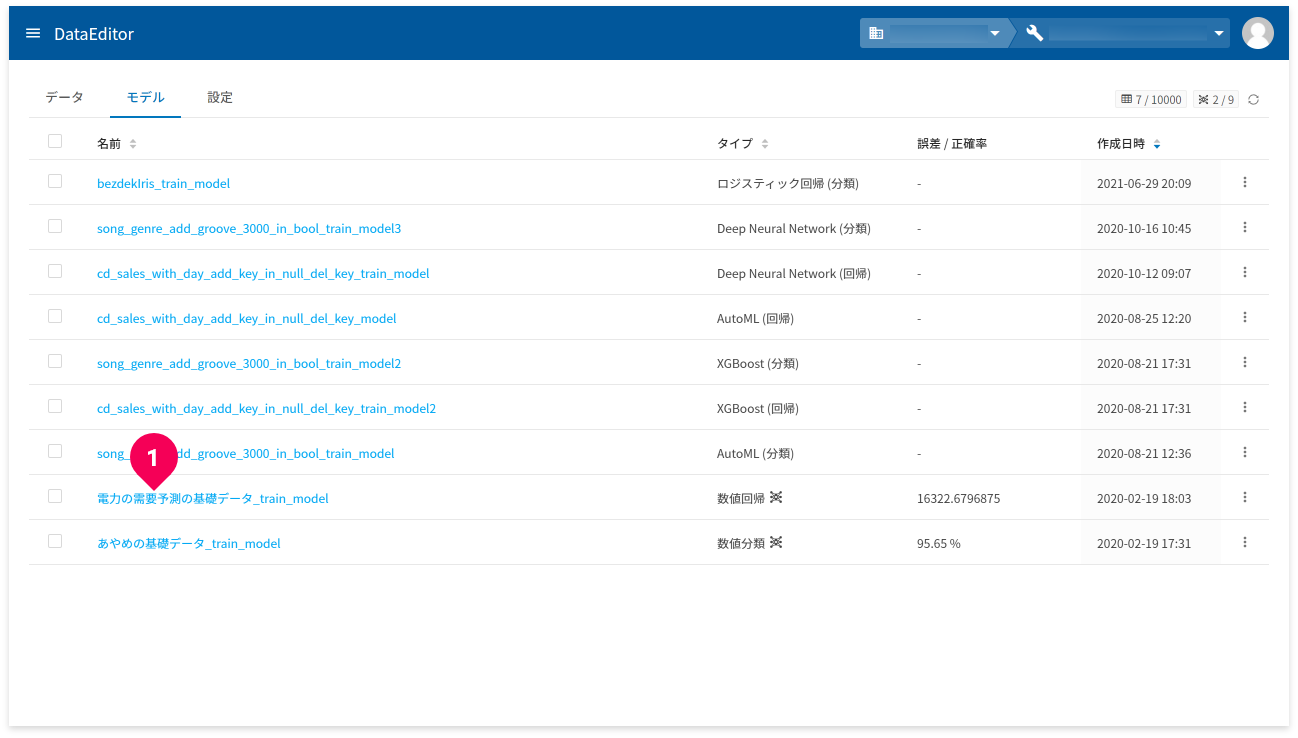
モデル名(❶)をクリックすると、当該モデルの詳細が確認できます。
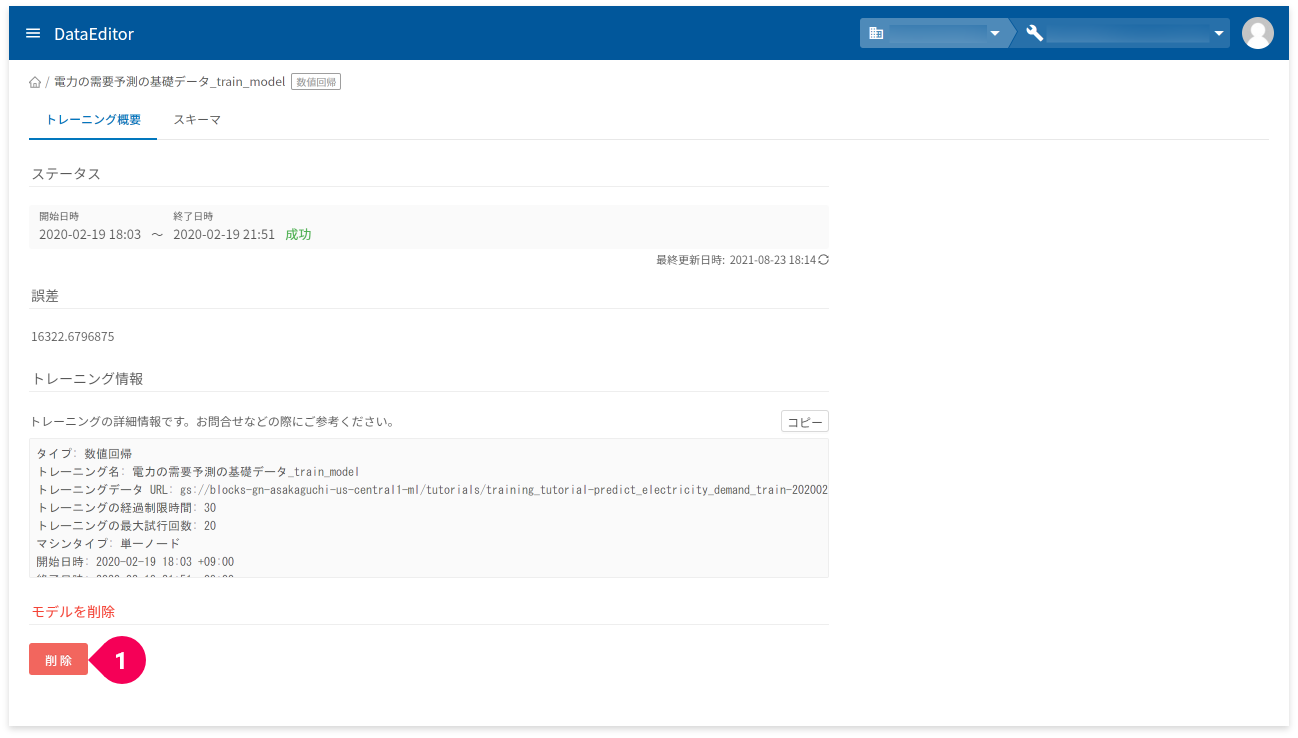
[削除]ボタン(❶)をクリックすると、当該モデルの削除ができます。
モデル名の変更
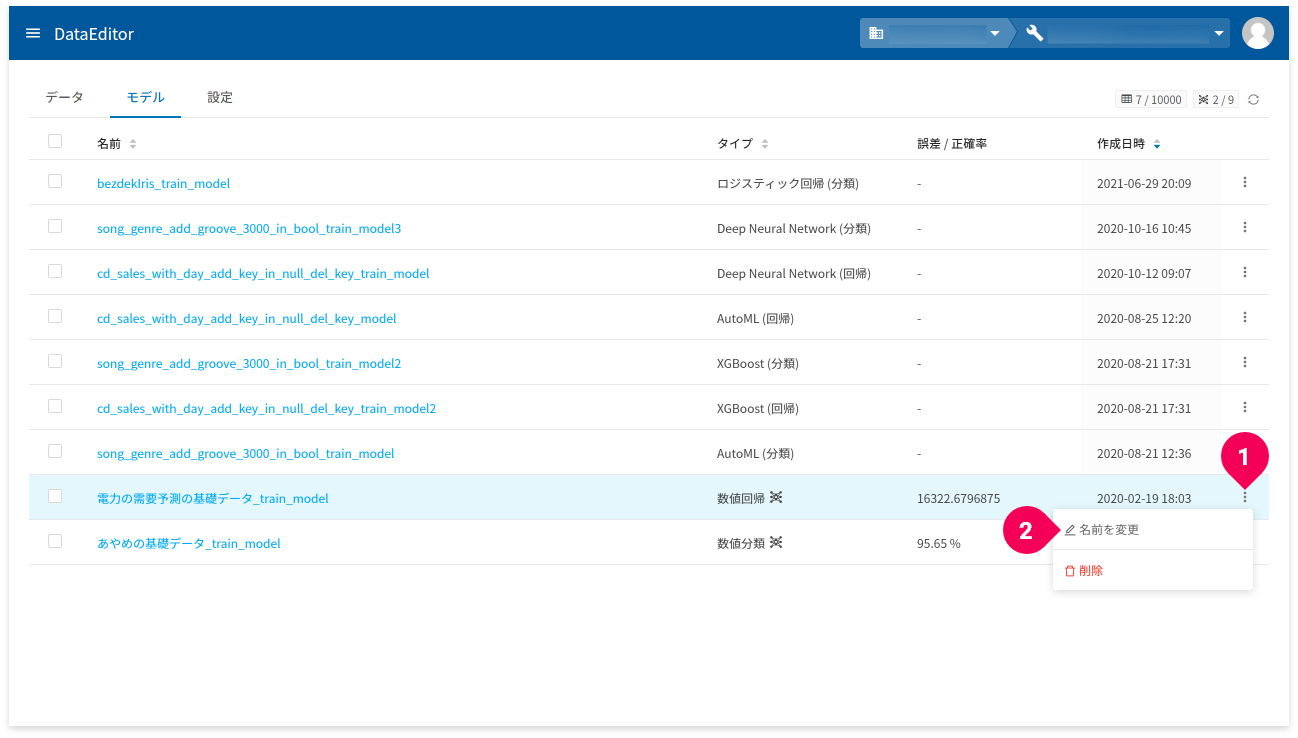
モデル一覧のmore_vert(❶)をクリックして表示されるメニューから、[名前を変更](❷)をクリックすると、当該モデルの名前の変更ができます。
タグの設定
タグとは、機械学習モデルを別名で管理できる機能です。例えば、フローの推論/予測ブロックで利用するモデル名の替わりにタグを使用することで、フローを変更することなくモデルの変更が可能です。
- タグは、ひとつのモデルに対して、複数設定できます。
- 同一プロジェクト内で同名のタグは作成できません。
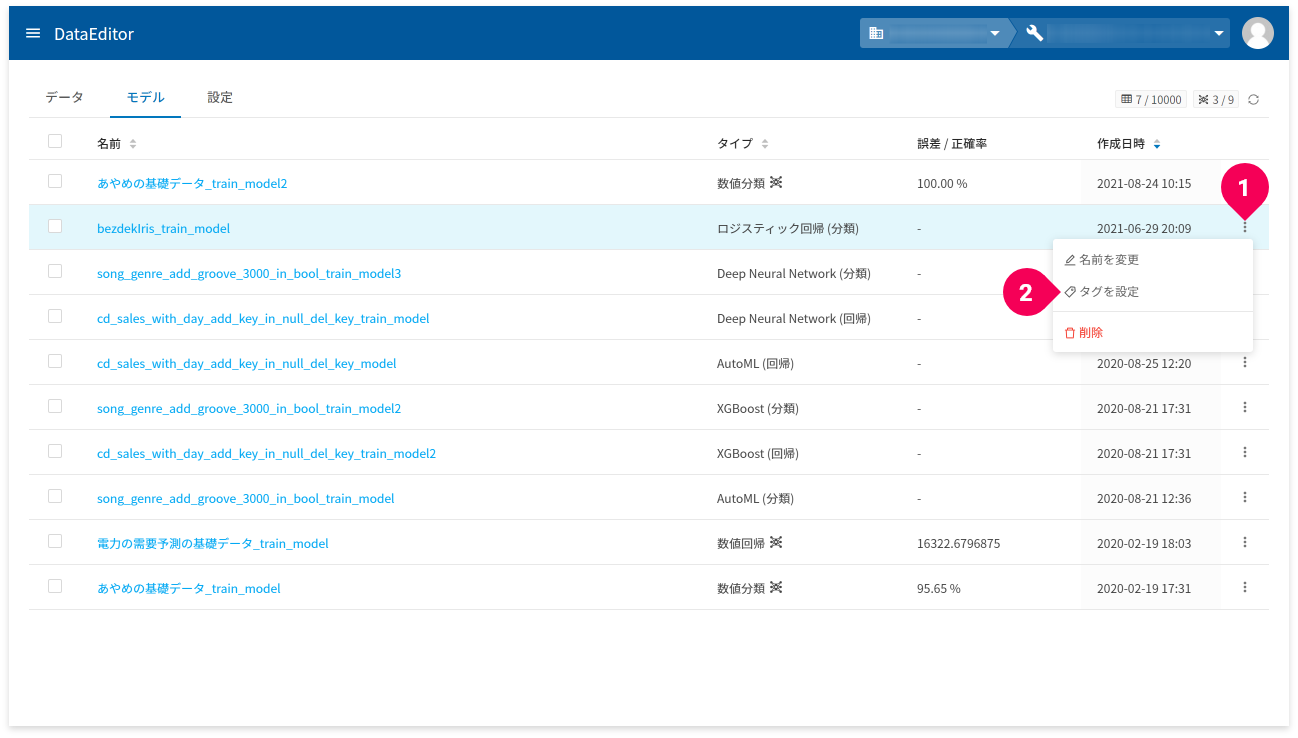
- タグを付けるモデルのmore_vertをクリック
- [タグを設定]をクリック
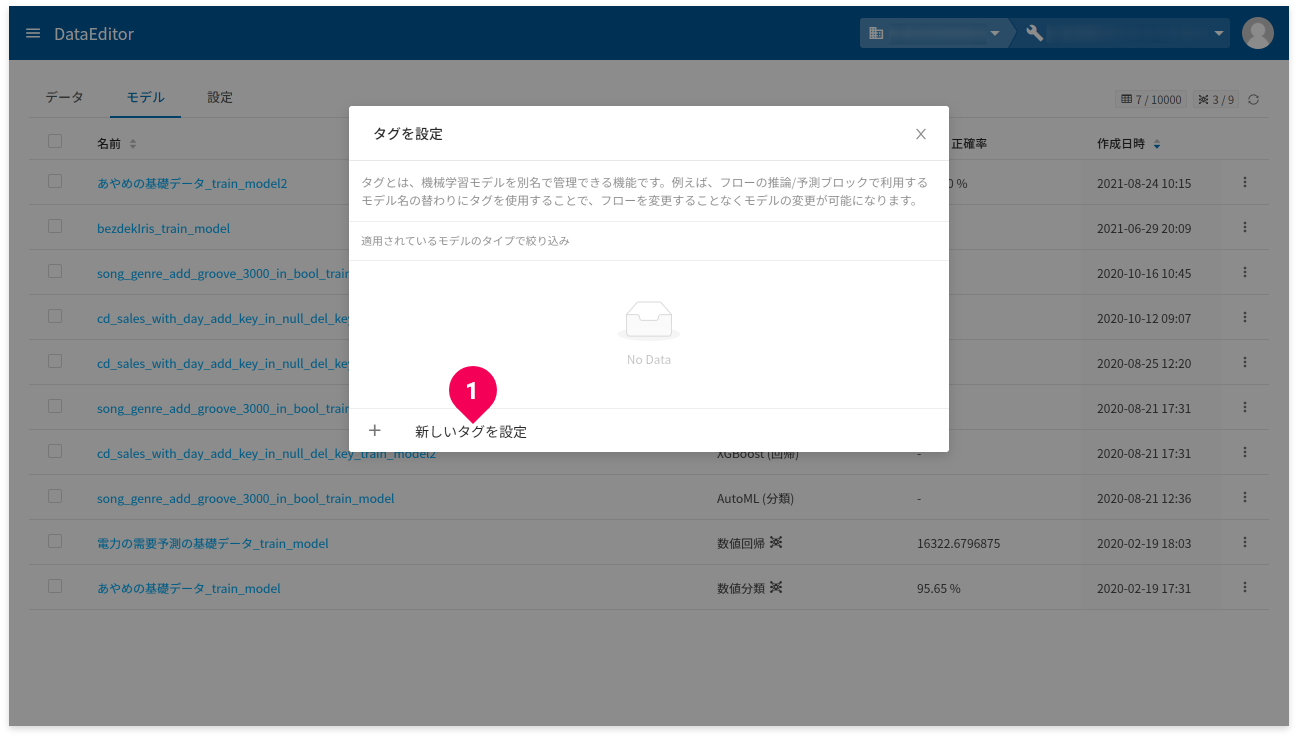
- [新しいタグを設定]をクリック
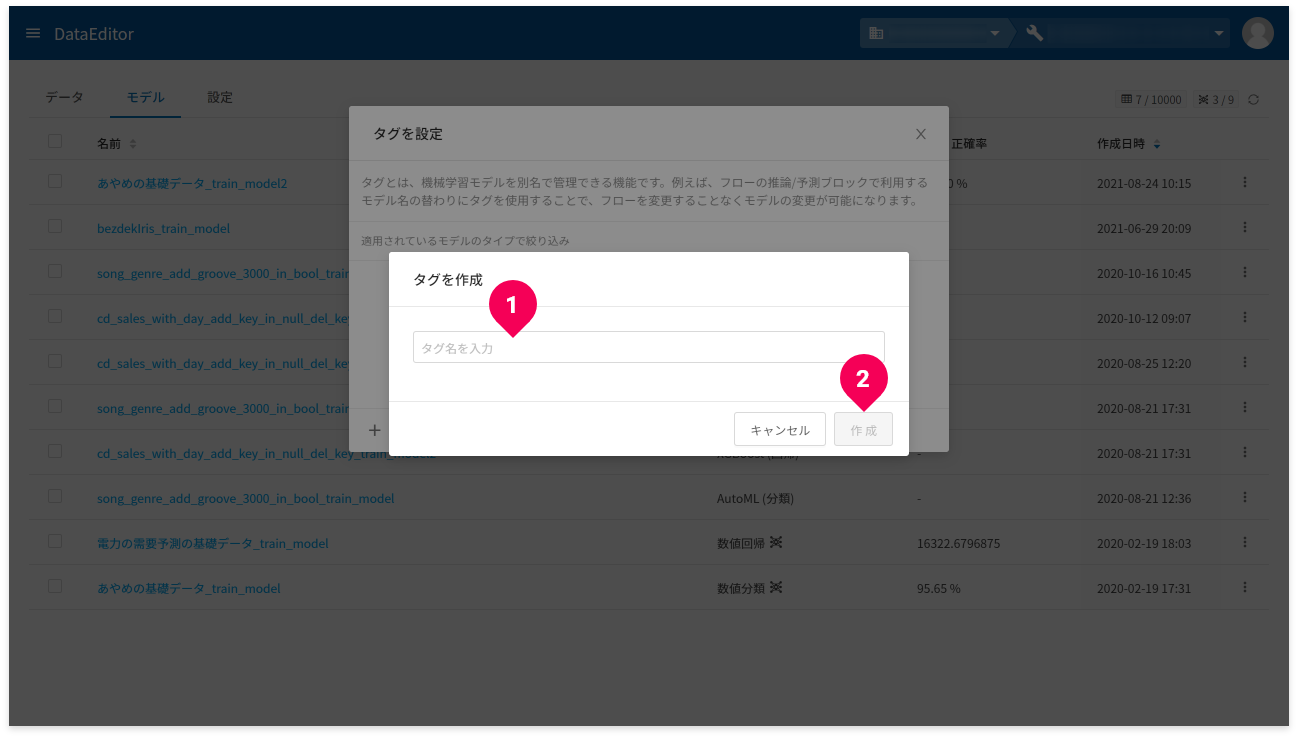
- タグ名を入力
- [作成]ボタンをクリック
タグ付け後、タグの付け替え、名前の変更や削除が可能です。
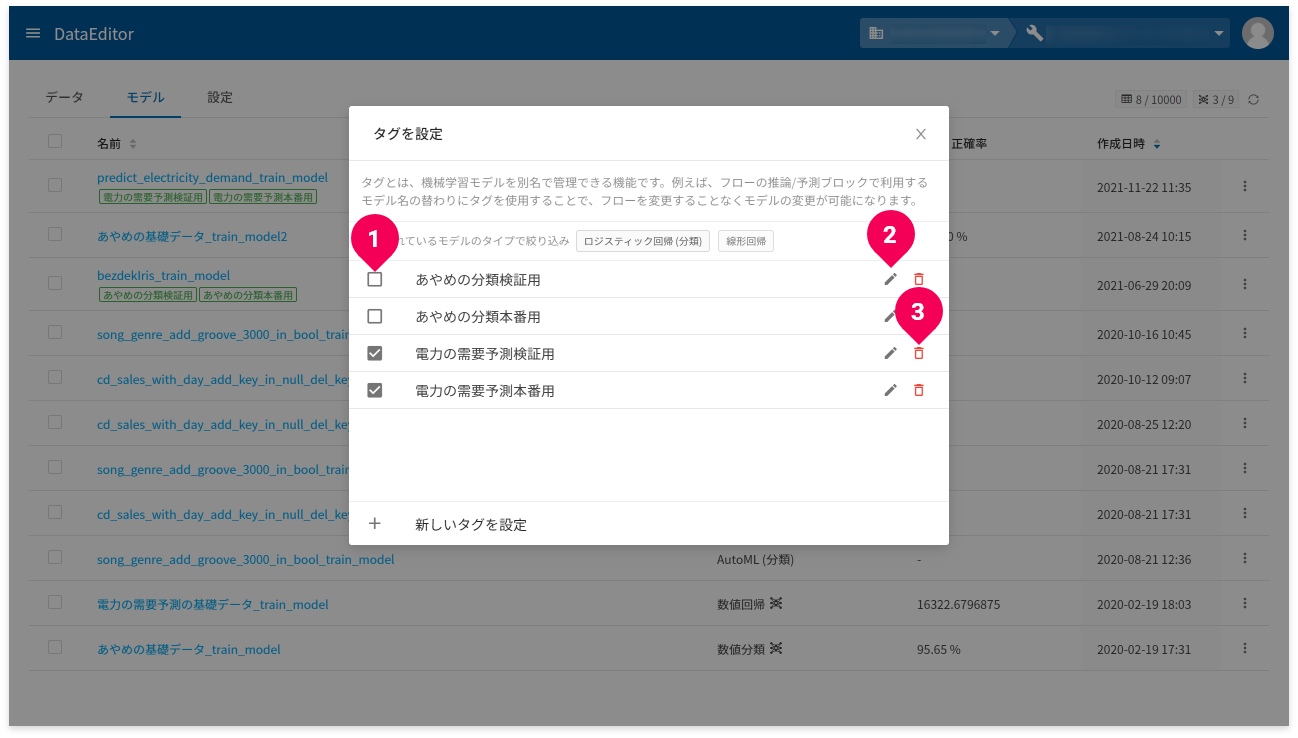
- タグの付け替え:付け替えるタグのチェックボックスをチェック(付け替え元のモデルからタグは外れる)
- タグの名前を変更:変更するタグのeditをクリック
- タグを削除:削除するタグのdelete_outlineをクリック
モデルの削除
モデルの削除は、詳細画面以外にも以下の方法で削除できます。
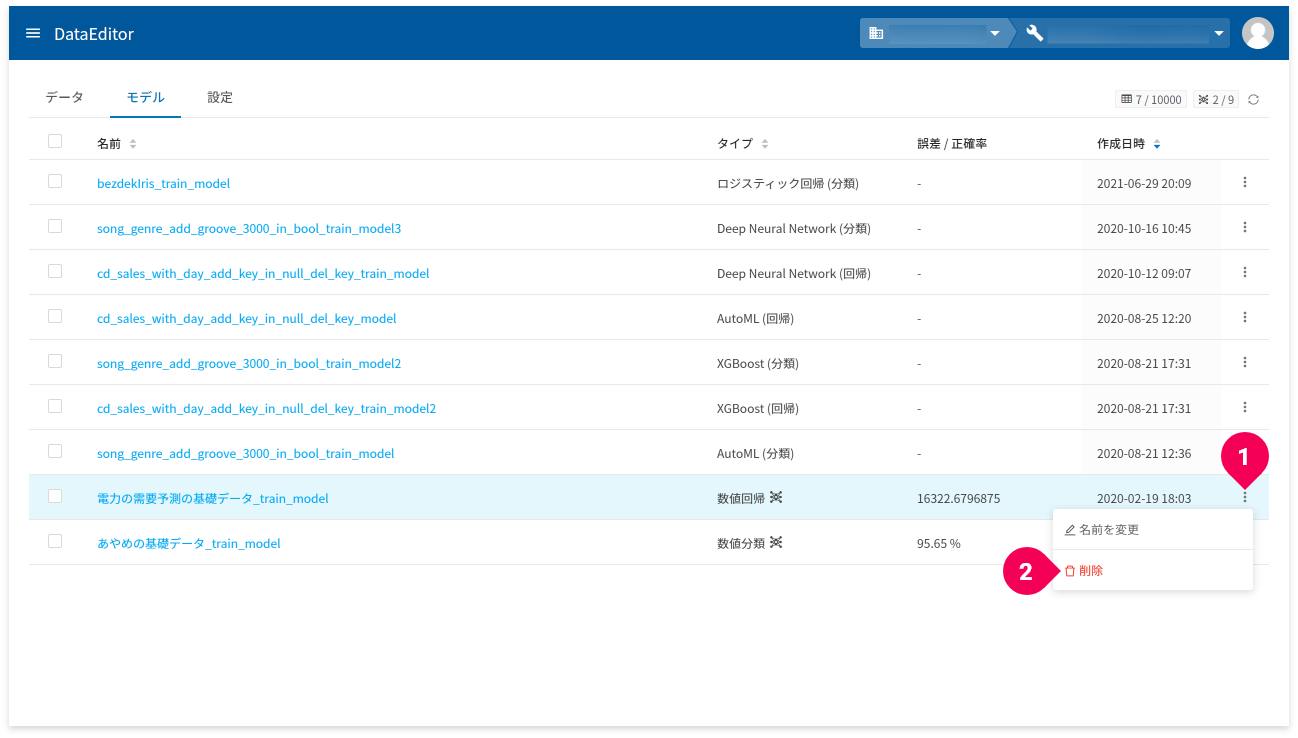
モデル一覧のmore_vert(❶)をクリックして表示されるメニューから、[削除](❷)をクリックすると、当該モデルの削除ができます。
複数のモデルをまとめて削除したい場合は、以下の方法でできます。
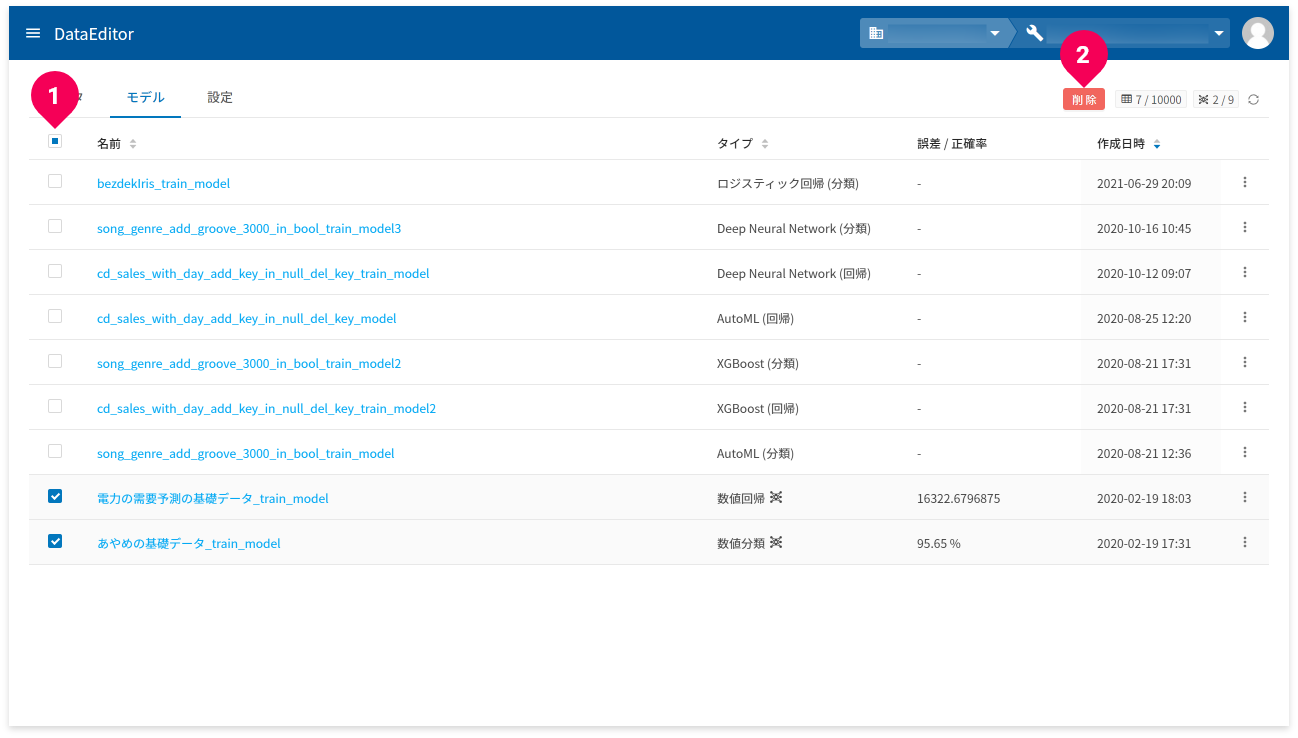
モデル一覧から削除したいモデルのチェックボックスにチェックを付け(❶)、[削除]ボタン(❷)をクリックすると、当該モデルの削除ができます。
モデルの保持期限の設定
この機能では、モデルの保持期限の設定・変更・削除ができます。保持期限は、年月日で指定します。
保持期限を設定すると、指定された年月日を経過するとそのモデルが自動削除されます。
保持期限の設定手順は、以下のとおりです。
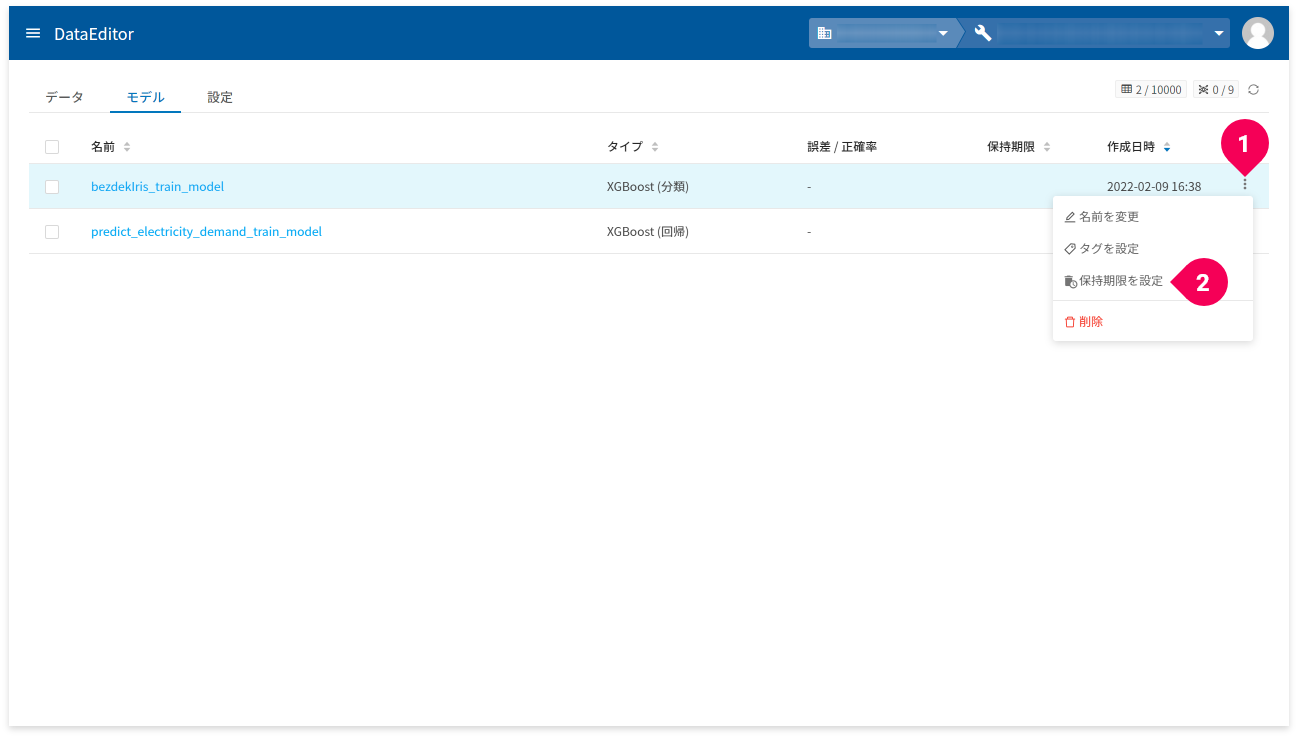
- 保持期限を設定したいモデルのmore_vertをクリック
- 「保持期限を設定」をクリック
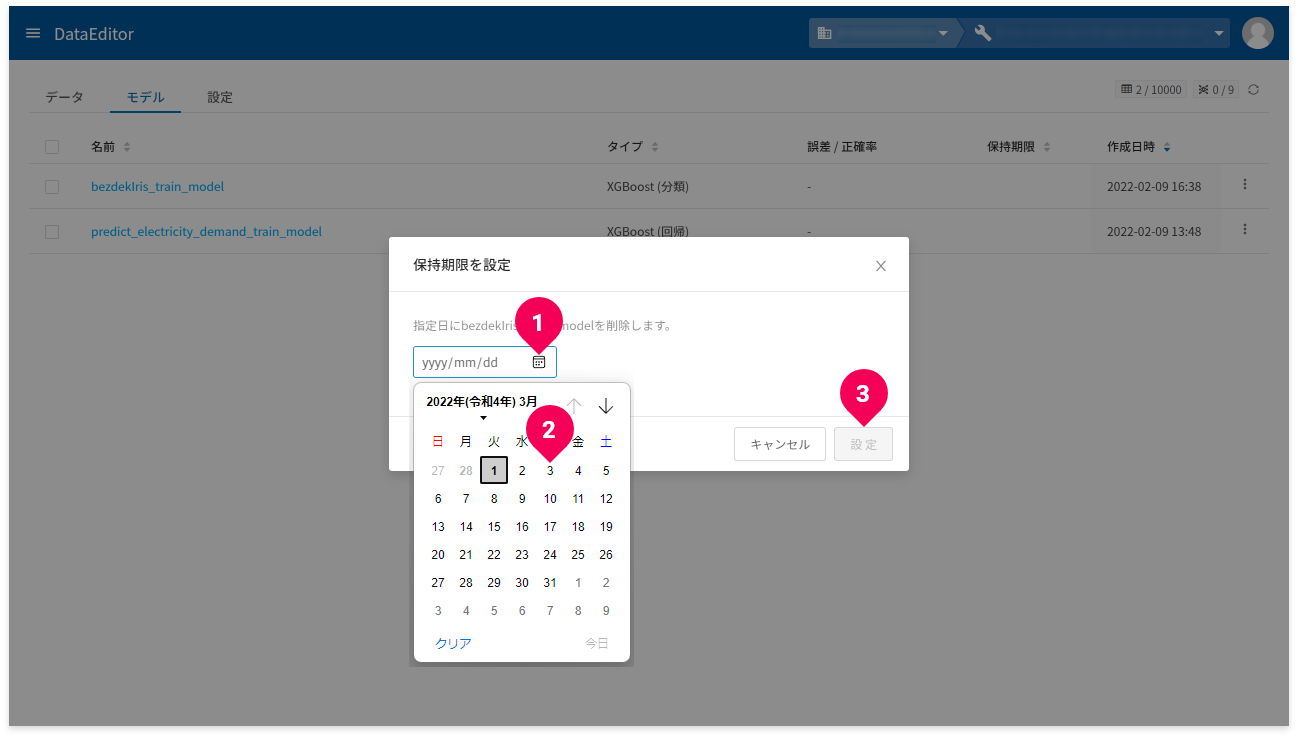
- カレンダーアイコンをクリック
- カレンダーを操作して、保持日時をクリック
- [設定]ボタンをクリック
保持期限の変更手順は、以下のとおりです。
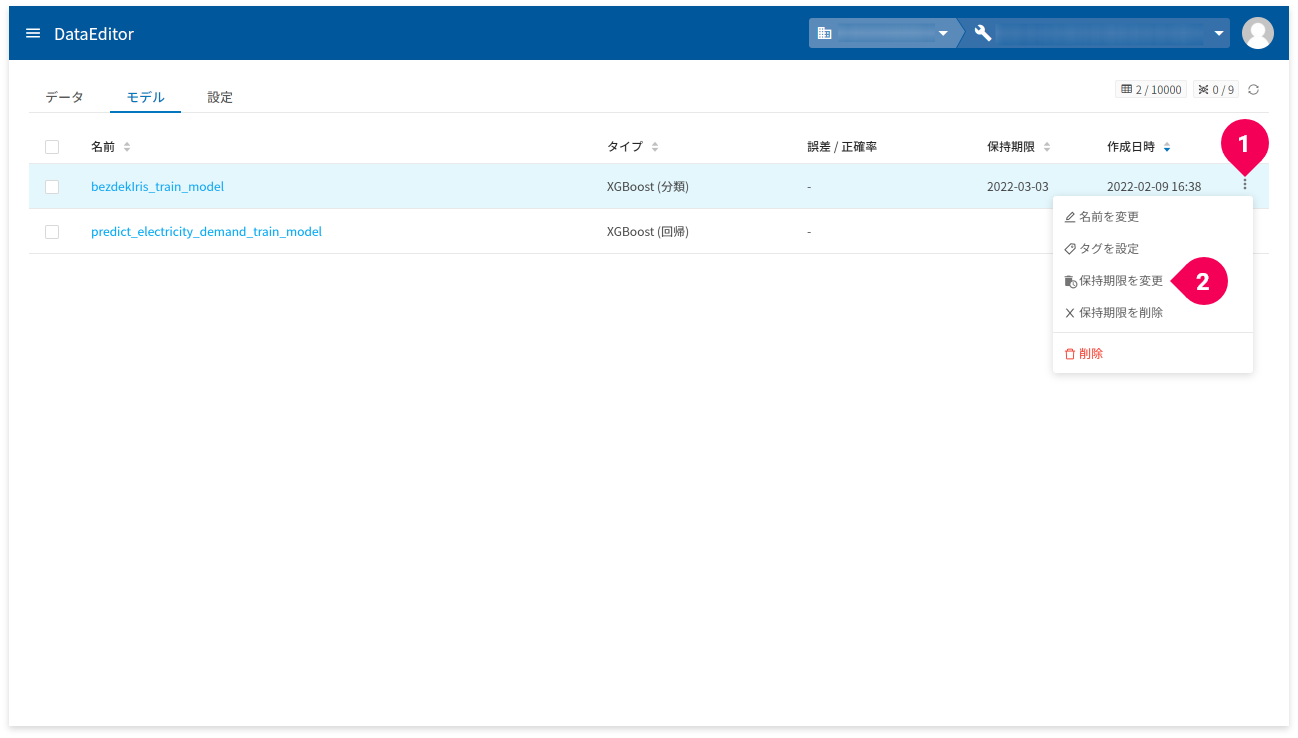
- 保持期限を変更したいモデルのmore_vertをクリック
- 「保持期限を変更」をクリック
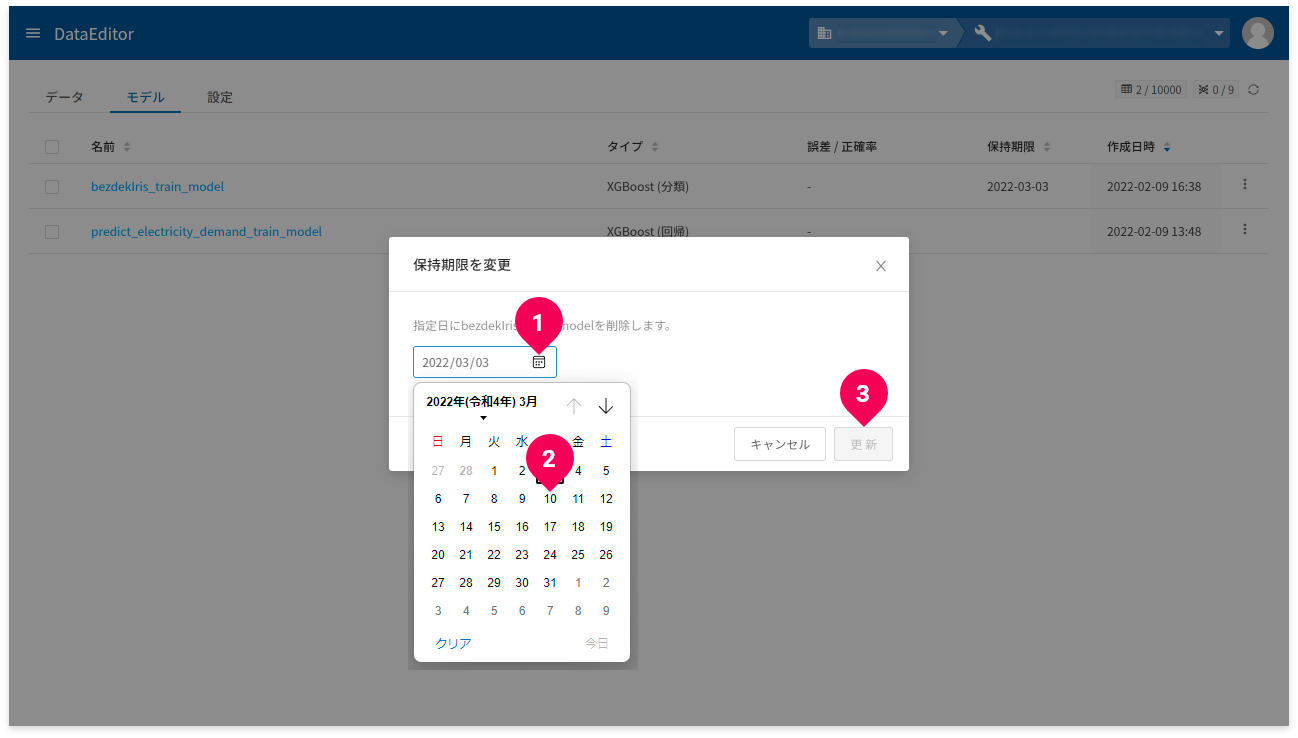
- カレンダーアイコンをクリック
- カレンダーを操作して、保持日時をクリック
- [更新]ボタンをクリック
保持期限の削除手順は、以下のとおりです。
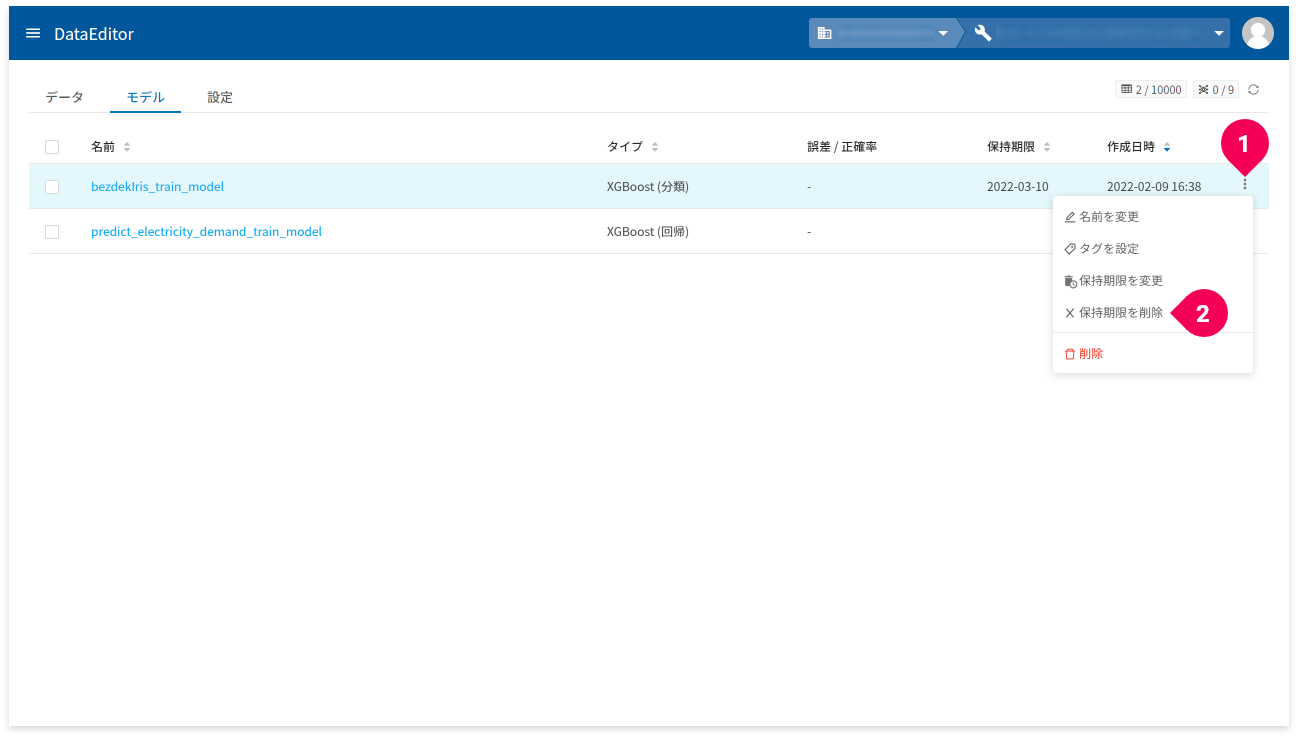
- 保持期限を削除したいモデルのmore_vertをクリック
- 「保持期限を削除」をクリック
設定
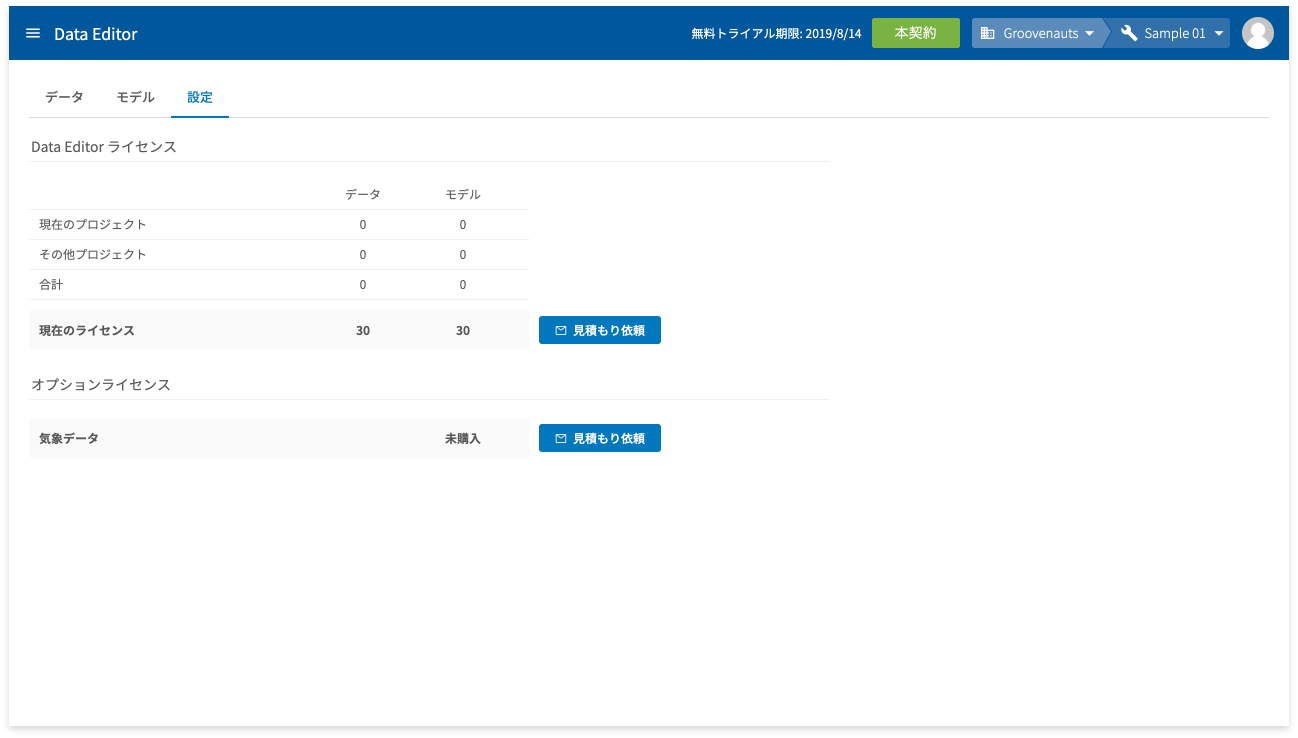
DataEditorホーム画面の[設定]タブの画面から、DataEditorのライセンス内容が確認できます。また、DataEditorの追加ライセンスや、オプションライセンスの見積もり依頼ができます。