はじめに
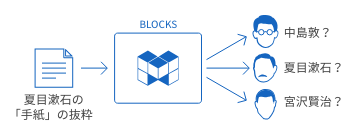
このチュートリアルでは、文学作品の抜粋文章からその作家が誰であるかを判定する例を使って、BLOCKS 機械学習のテキスト分類の使い方を解説します。
error この機能は、ベータ版です。正式版リリース後は、手順含め新たに作り直しとなる可能性があります。その点を踏まえた上で、ご利用願います。
また、ベータ版での提供となるため、一部の機能が正常に動作しない可能性があります。機能改善や不具合などのフィードバックは、お問い合わせで情報提供をお願いします。フィードバックの内容は MAGELLAN BLOCKS の品質向上のために利用いたします。
テキスト分類のおおまかな流れ
BLOCKS で機械学習を使ったテキスト分類を行うには、「モデルジェネレーター」と「フローデザイナー」を使用します。
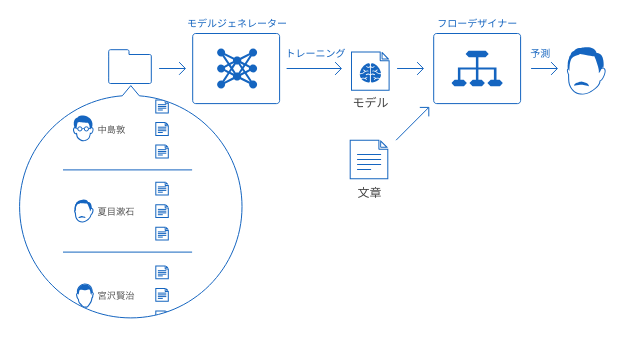
まず、モデルジェネレーターで学習(トレーニング)を行います。このトレーニングでは、作家ごとの文章データを与えて、作家ごとの文章の特徴を学ばせます。このトレーニングの成果は、モデルと呼ばれます。
次に、フローデザイナーでモデルと作家ごとの予測文章を与えて、どの作家の文章かの予測を行います。
info_outlineトレーニング用の文章データや予測用の文章データは、あらかじめ用意しておく必要があります。
テキスト分類を試してみよう
テキスト分類を始める前に
まず、BLOCKS 推奨のウェブブラウザー Google Chrome を準備してください。Firefox でも構いませんが、その場合は一部機能に制限があります(後述)。このチュートリアルでは、Google Chrome の使用を前提にしています。
次に、テキスト分類のトレーニングと予測に必要な文章データを準備します。先に述べたように、BLOCKS でテキスト分類を行うには、モデルジェネレーターを使ったトレーニングが必要です。このトレーニングには、トレーニング用の文章データが必要です。また、予測するための文章データも必要です。このチュートリアルでは、BLOCKS のテキスト分類がすぐ試せるように、必要なデータ一式を準備しました。
| データ | 説明 |
|---|---|
| cloud_download サンプルデータ |
機械学習のテキスト分類で使用する文書ファイル一式です。トレーニングと予測で使用する 2 種類の文章ファイルを含んでいます。 |
-
サンプルデータのダウンロード
上記表のデータ欄のリンクをクリックして、サンプルデータをダウンロードします。サンプルデータは、ZIP 形式で複数のフォルダーやファイルをひとつにまとめています。
-
ダウンロードしたファイルの解凍
ダウンロードした ZIP 形式のファイルを解凍します。下図のフォルダー構成でフォルダーやファイルが解凍されます。

トレーニング用の文章(テキスト)ファイルは、分類する作家ごとにフォルダー分けして配置します。フォルダー名が分類する種類の名前として扱われます。テキストファイルの拡張子は、.txt のみに対応しています(大文字・小文字の区別なし)。
今回の例では、宮沢賢治・中島敦・夏目漱石の 3 作家で分類するため、以下 3 種類のフォルダーに分けて作品ファイルを配置しました。
- miyazawa_kenji フォルダー
- nakajima_atsushi フォルダー
- natsume_souseki フォルダー
-
Google Cloud Storage(GCS)へアップロード
トレーニングでは、GCS からトレーニングデータを読み取ります。解凍した text_classification_example フォルダーを、GCS Explorer ツールを使って GCS へアップロードします。アップロードの手順は、以下のとおりです。
ウェブブラウザーで、BLOCKS にログインします。
- グローバルナビゲーション左端のメニューアイコン(menu)をクリック
- [GCS Explorer]をクリック

- 適切な GCP サービスアカウントを選択
既に適切な GCP サービスアカウントが選択されている場合はそのまま
info_outline 既に GCP サービスアカウント選択済みでこの画面を表示したい場合は、❷のアイコンをクリックします。
- 末尾が -us-central1-data のバケット名をクリック
既に適切なバケットが選択されている場合はそのまま
info_outline 既に他のバケットもしくはフォルダーを選択している場合で、この画面を表示したい場合は、❷の[バケット一覧]をクリックします。
info_outline セルフサービスプラン(無料トライアル含む)の場合は、プロジェクト作成時にオプションを選択してバケットが同時に作成されていることを前提としています。
バケットがひとつもない場合は、プロジェクト設定の GCP サービスアカウントの項で、バケットの作成ができます。
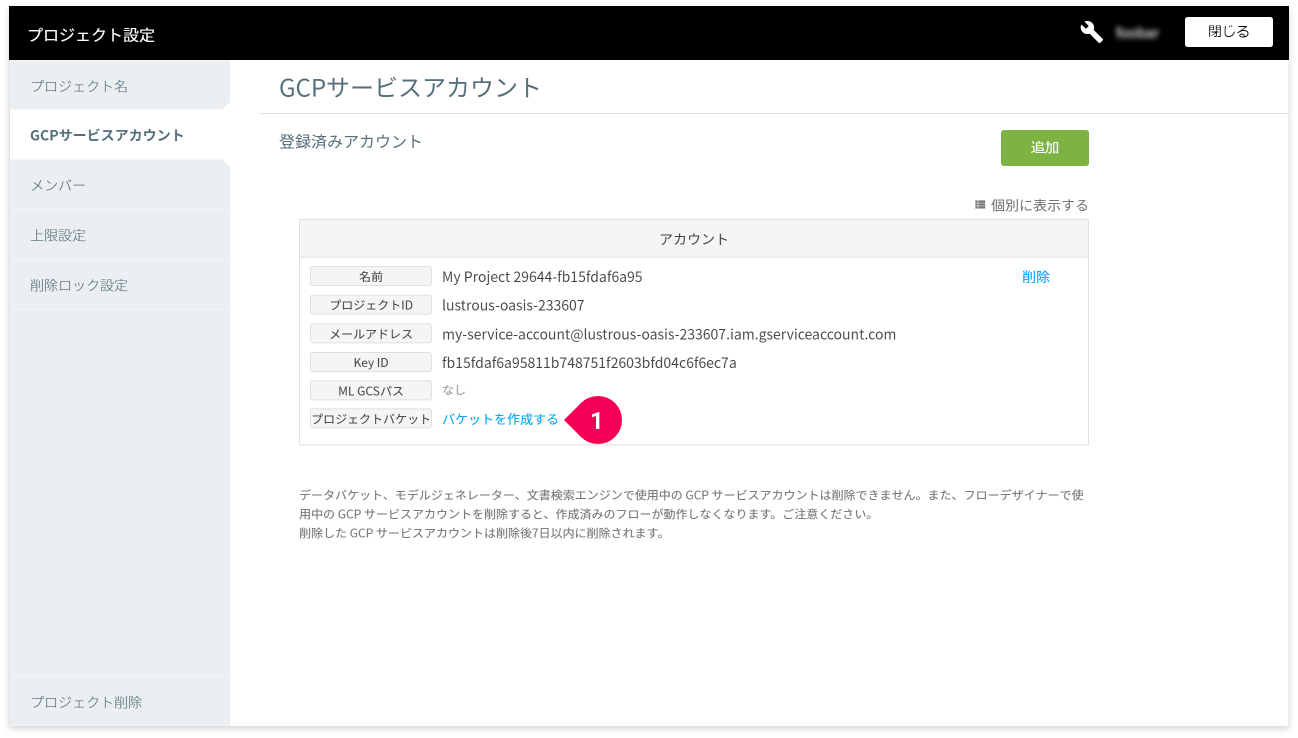
既に異なるバケットが作成済みの場合は、そのバケットを選択しても構いません。ただし、そのバケットのストレージクラスとロケーションは、Regional かつ us-central1 である必要があります。
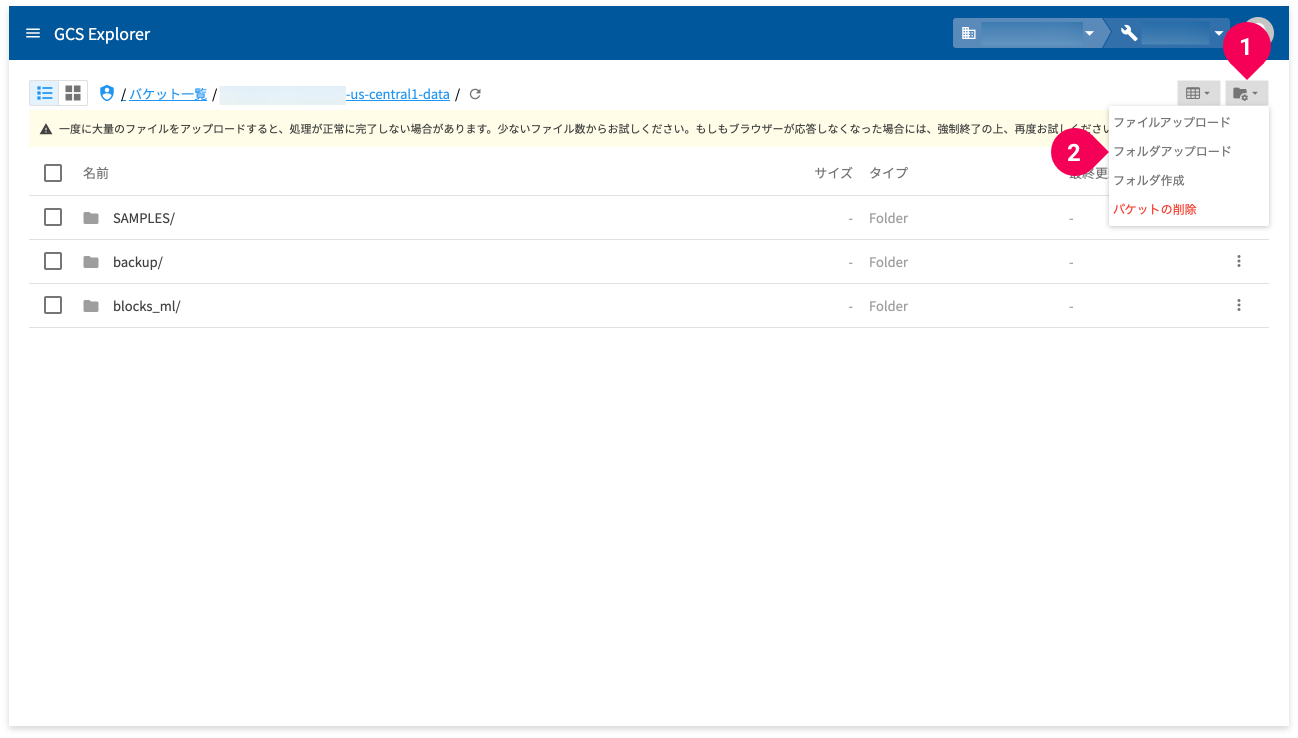
- フォルダーに歯車の絵柄のボタンをクリック
- [フォルダアップロード]をクリック
info_outline Firefox では、GCS Explorer のフォルダーのアップロード機能は利用できません(前述の一部機能の制限)。その場合は、まず GCS Explorer のフォルダー作成機能を使って、解凍してできたフォルダー構成を GCS 上に再現します。次に、ファイルアップロード機能を使って所定のフォルダー内に各ファイルをアップロードします。ファイルのアップロード方法については、「GCS へファイルをアップロードする方法」を参考にしてください。
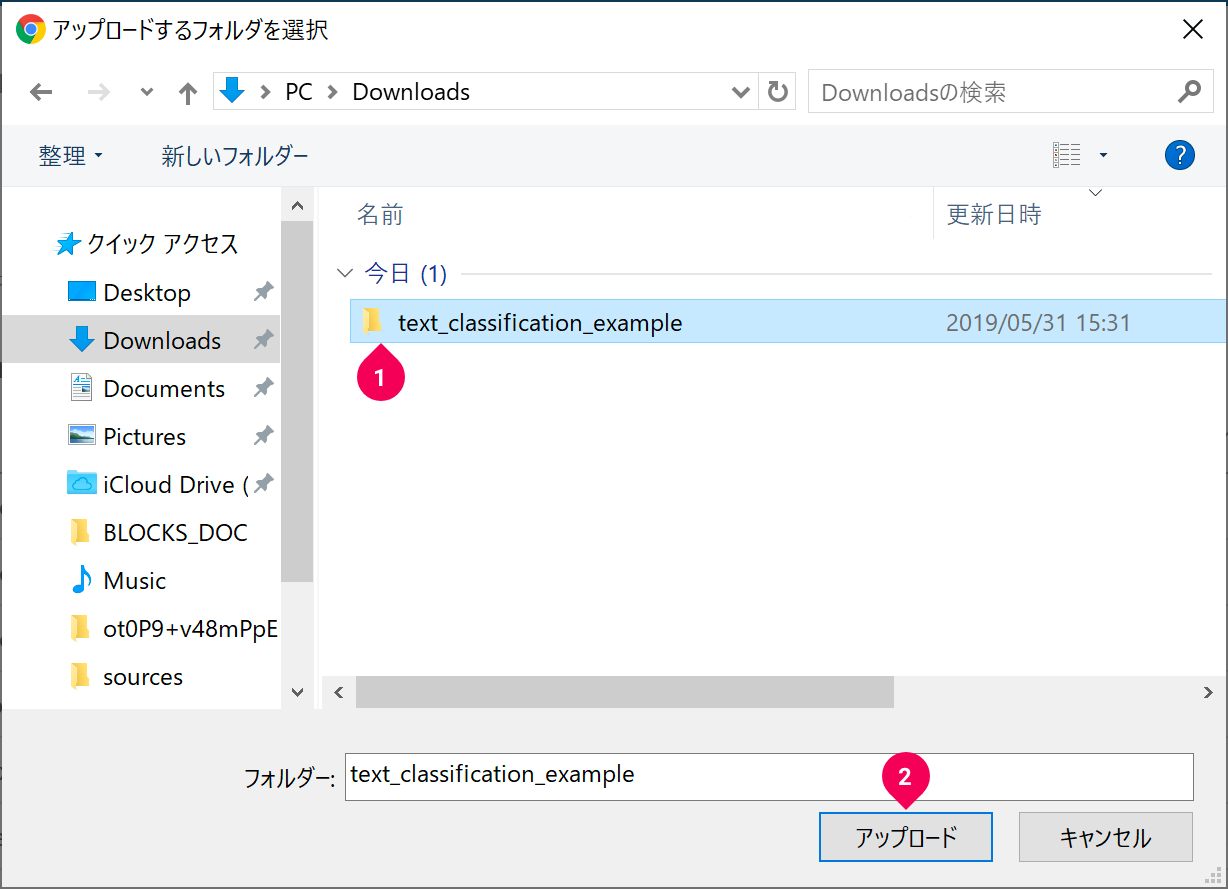
- 先に解凍しておいた text_classification_example フォルダーをクリック
- [アップロード]ボタンをクリック
- [アップロード]ボタンをクリック
しばらくすると、text_classification_example フォルダーがアップロードされます。
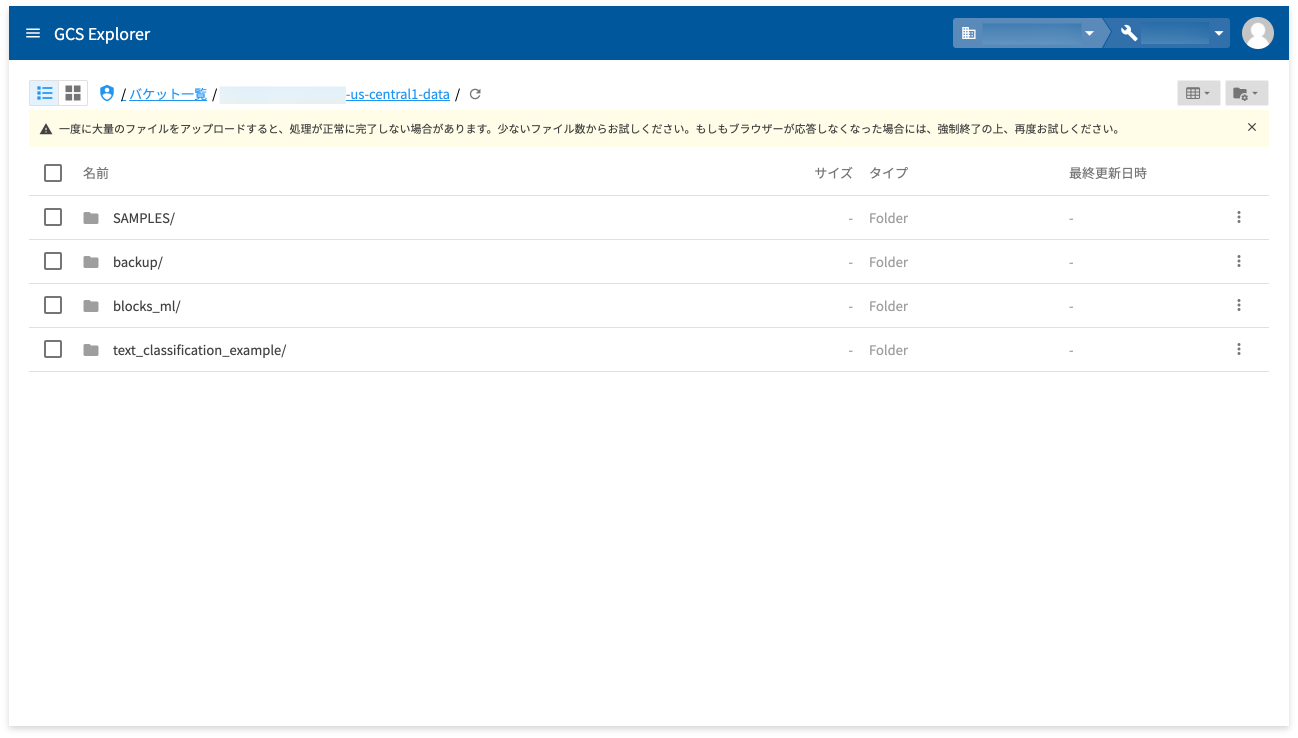
これで、テキスト分類のトレーニングと予測に必要なデータの準備ができました。
モデルジェネレーターを作成しよう
モデルジェネレーターでトレーニングするには、準備したトレーニング用のデータに対応した専用のモデルジェネレーターが必要です。
このモデルジェネレーターは、以下の手順で作成できます。
- グローバルナビゲーション左端のメニューアイコン(menu)をクリック
- [モデルジェネレーター]をクリック
モデルジェネレーターがひとつもない場合は、「モデルジェネレーターとは」の画面が表示されます。
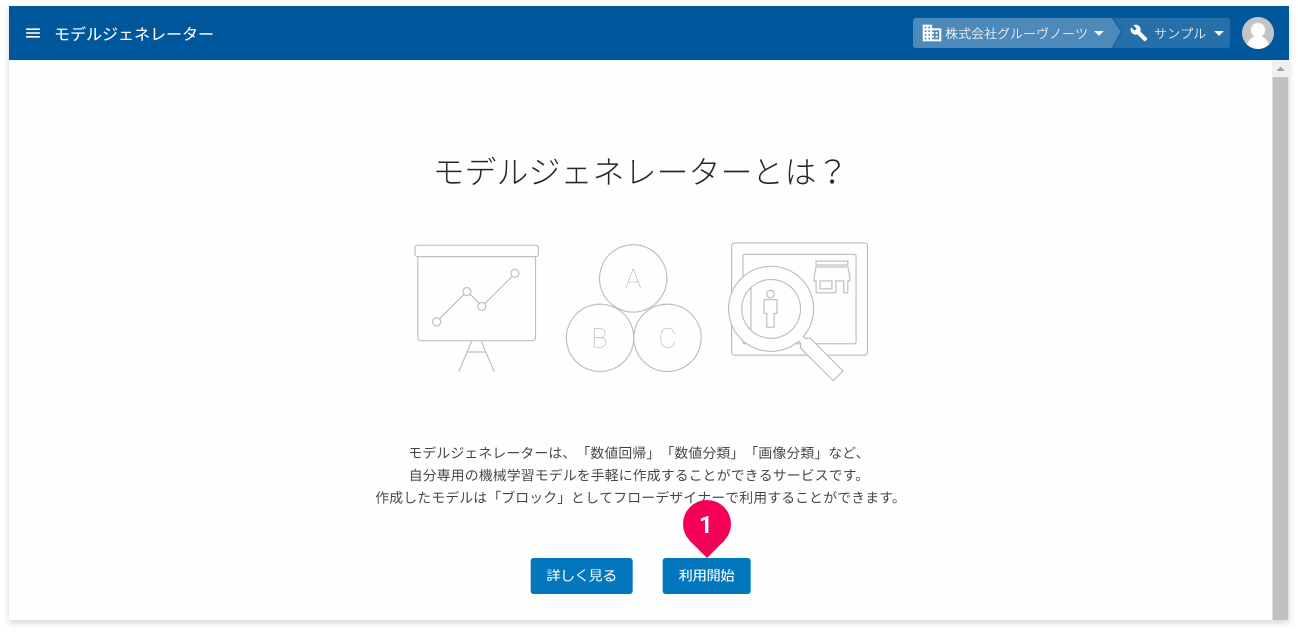
- [利用開始]ボタンをクリック
info_outline ライセンス不足の場合は、その旨のメッセージが表示されます(管理者の場合は、ライセンス購入画面を表示)。メッセージが表示された場合は、組織の管理者に問い合わせてください(管理者の場合は、ラインセンスを購入してください)。
モデルジェネレーターがひとつ以上ある場合は、作成済みのモデルジェネレーターの一覧が表示されます。
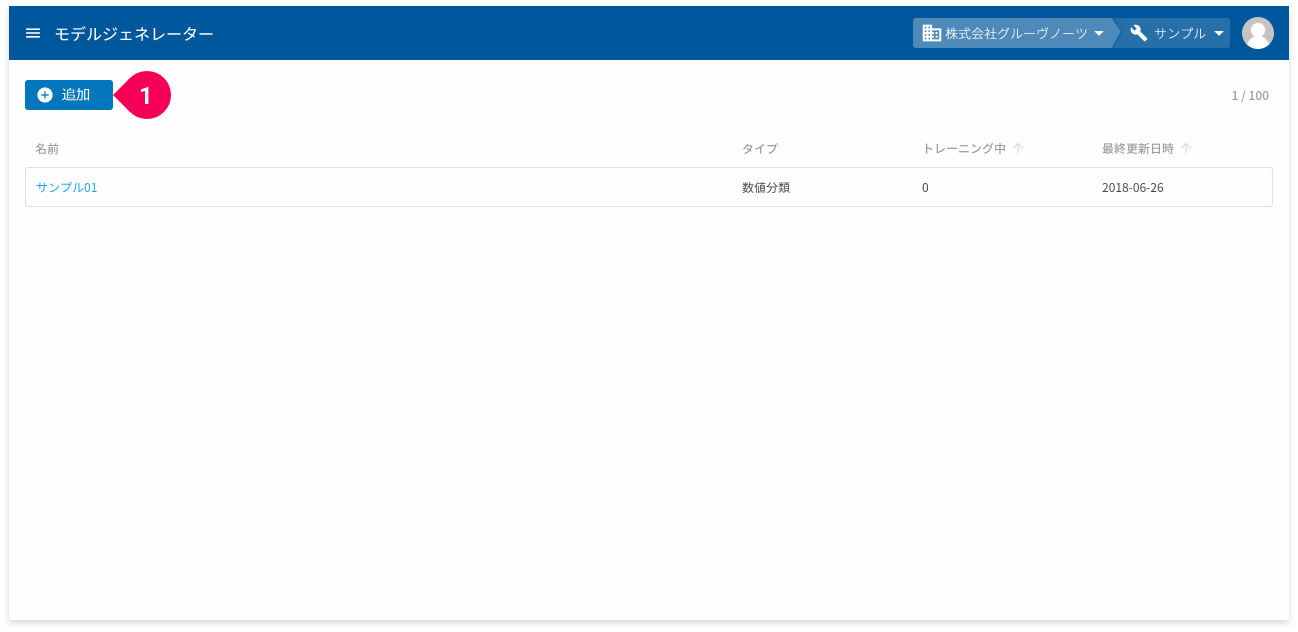
- 画面左上の[追加]ボタンをクリック
info_outline ライセンス不足の場合は、その旨のメッセージが表示されます(管理者の場合は、ライセンス購入画面を表示)。メッセージが表示された場合は、組織の管理者に問い合わせてください(管理者の場合は、ラインセンスを購入してください)。
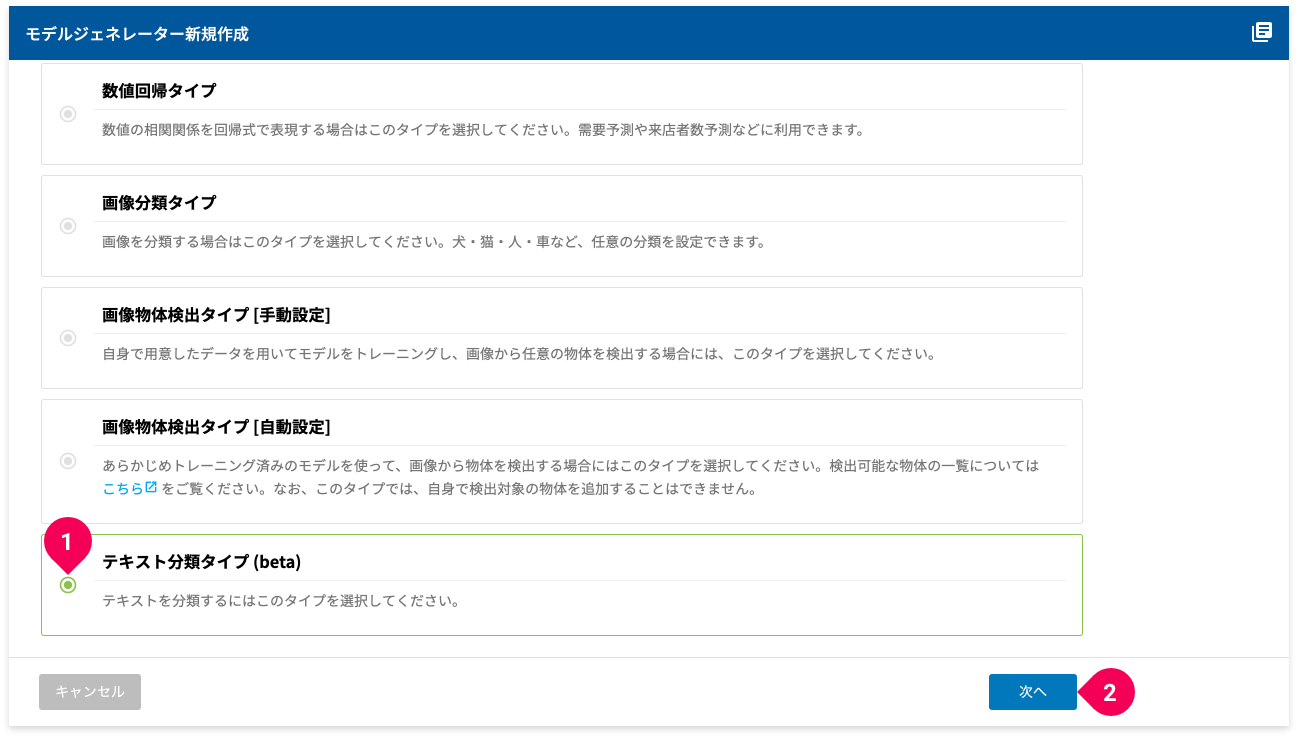
- [テキスト分類タイプ (beta)]をクリック
- [次へ]ボタンをクリック
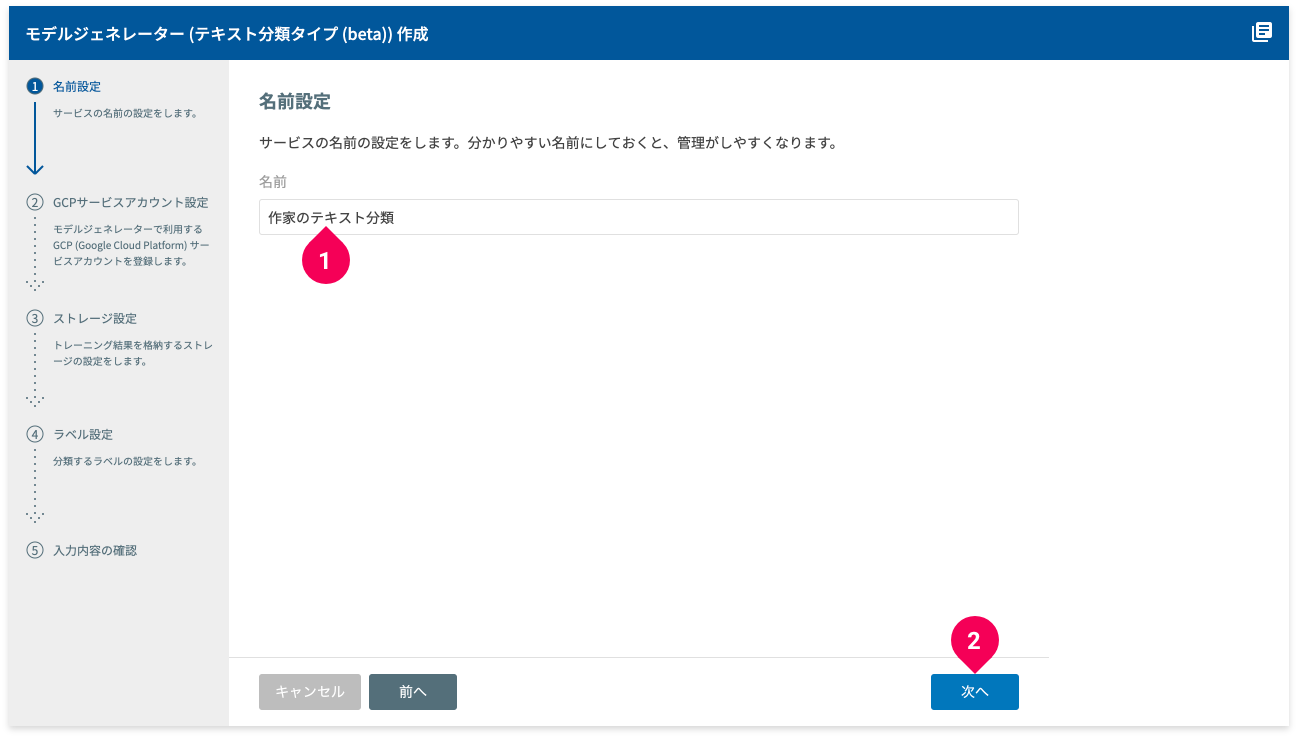
- 名前を入力(例:
作家のテキスト分類) - [次へ]ボタンをクリック
info_outline 無料トライアルおよびセルフサービスプランの場合は、画面の案内に沿って以下のステップを進めてください。
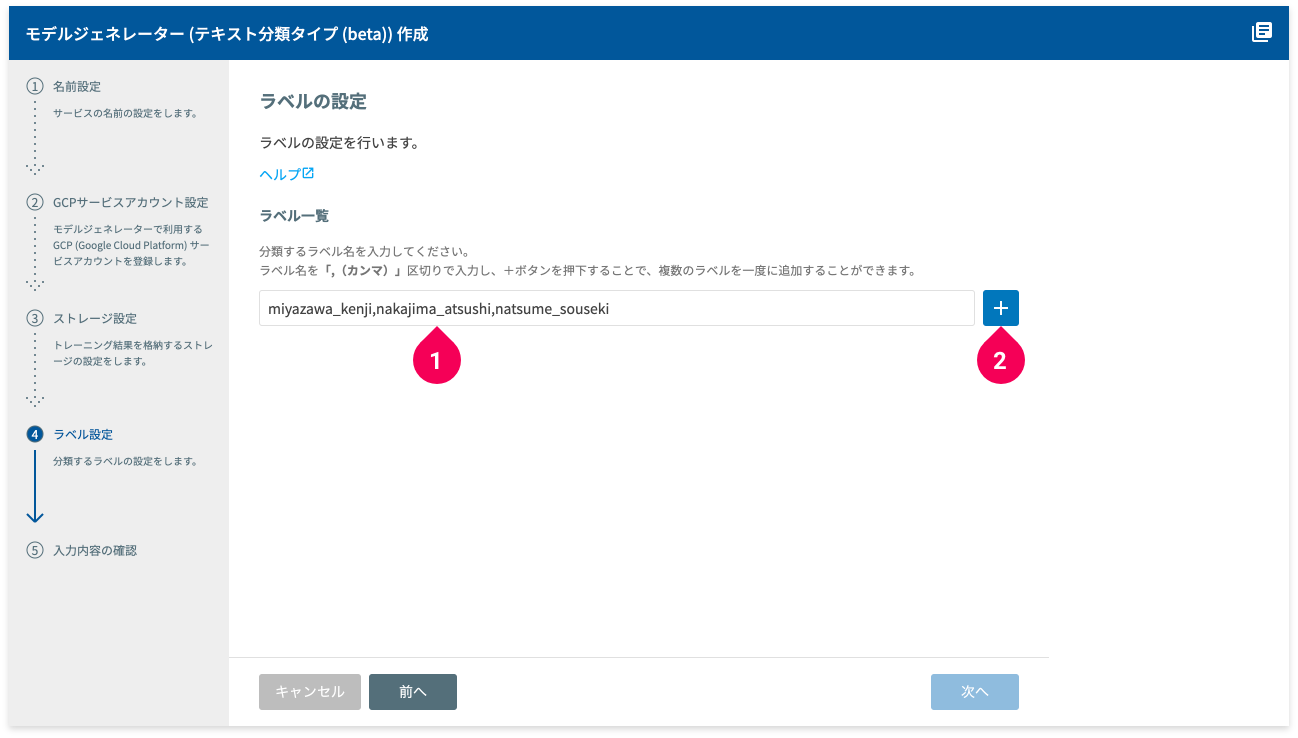
- ラベルをまとめて入力(例:
miyazawa_kenji,nakajima_atsushi,natsume_souseki) - add_box ボタンをクリック
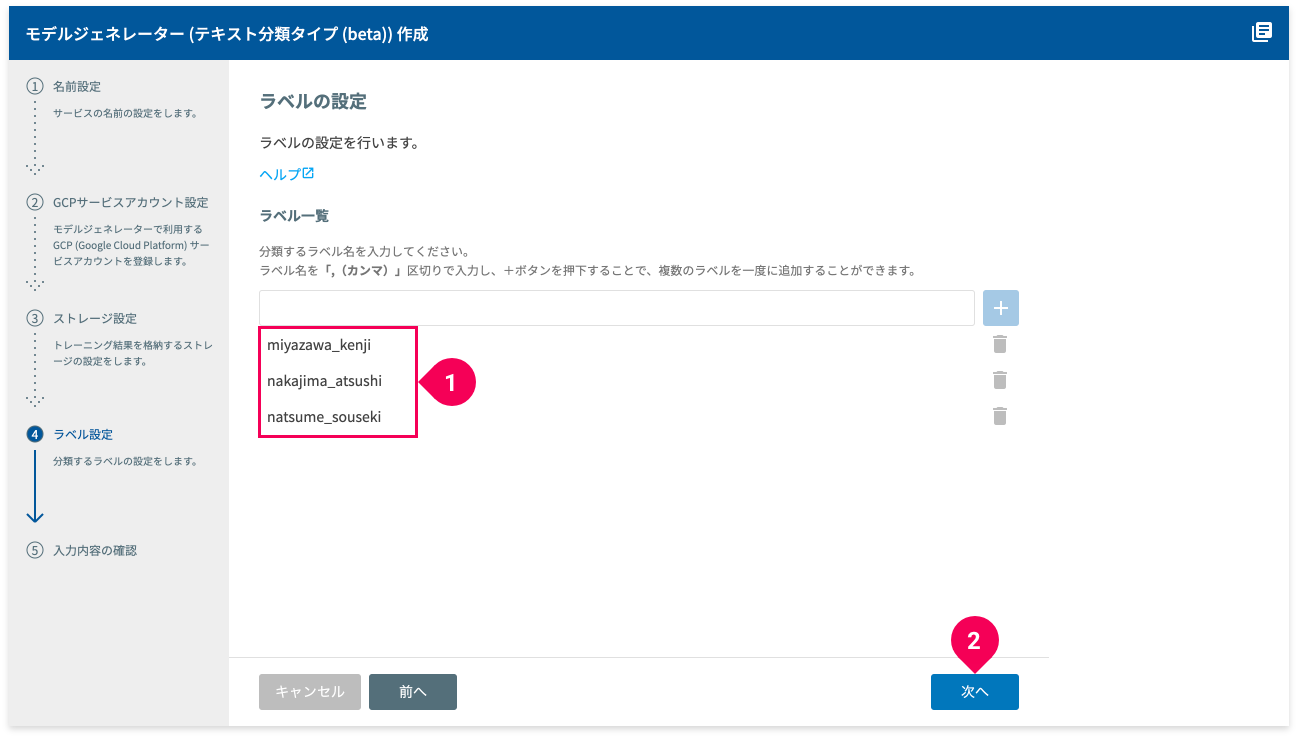
- ラベルが追加されたことを確認
- [次へ]ボタンをクリック
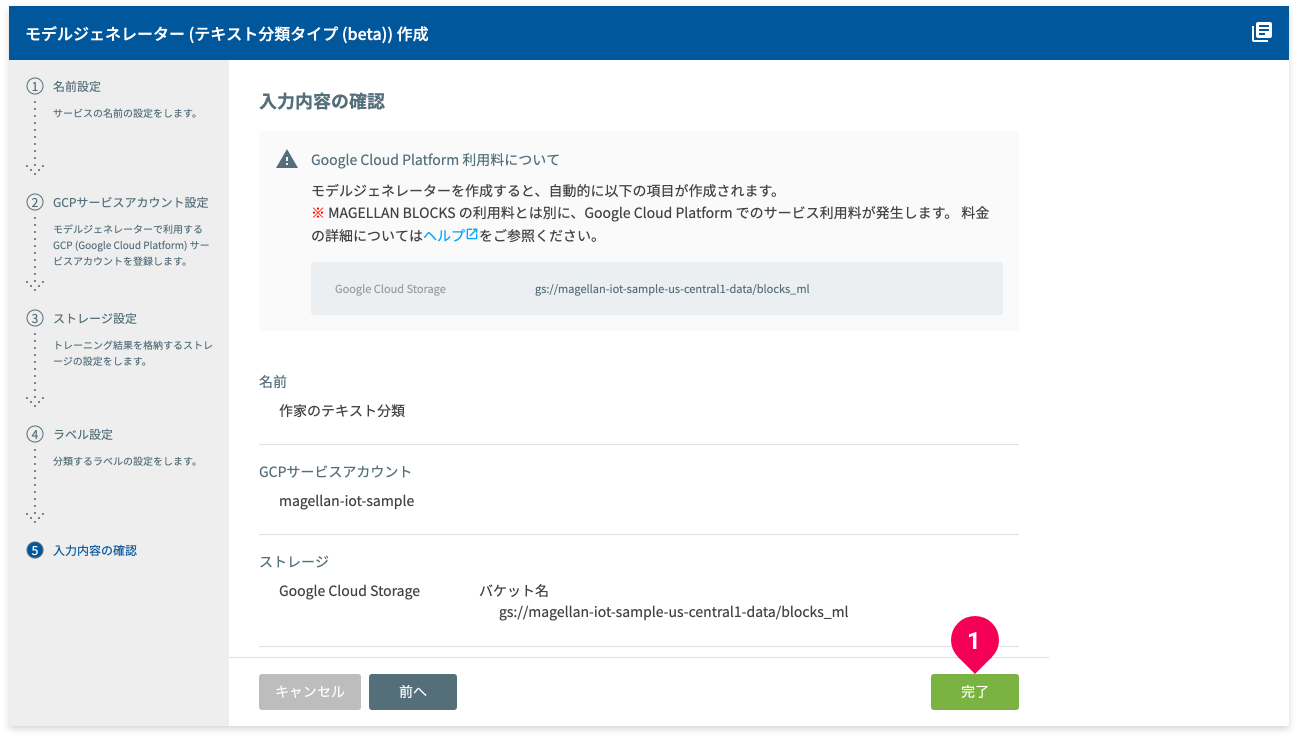
- 設定内容を確認し、[完了]ボタンをクリック
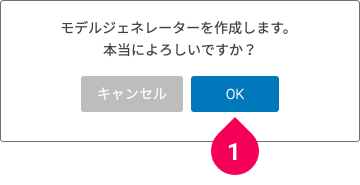
- [OK]ボタンをクリック
これで、準備したトレーニング用データに対応したモデルジェネレーターが作成できました。
モデルジェネレーターでトレーニングしよう
モデルジェネレーターが作成できたので、準備したトレーニング用のデータでトレーニングを行います。
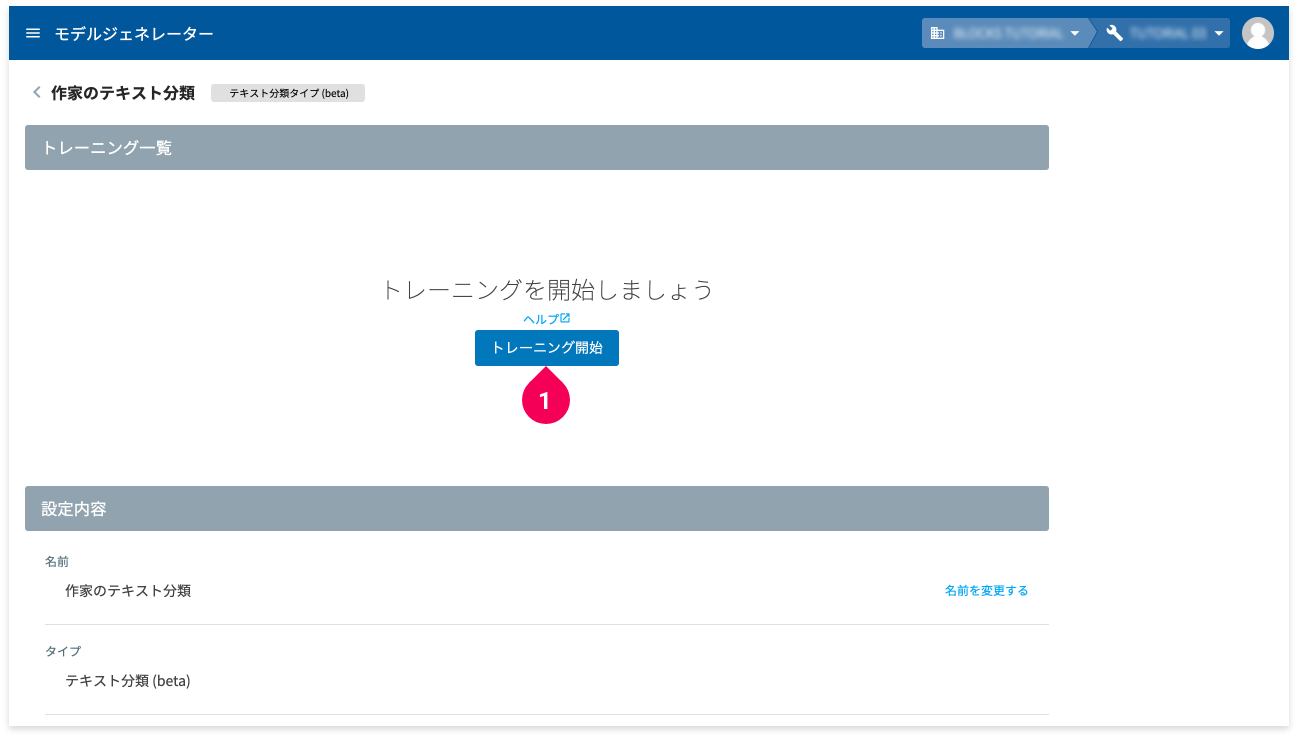
- [トレーニング開始]ボタンをクリック
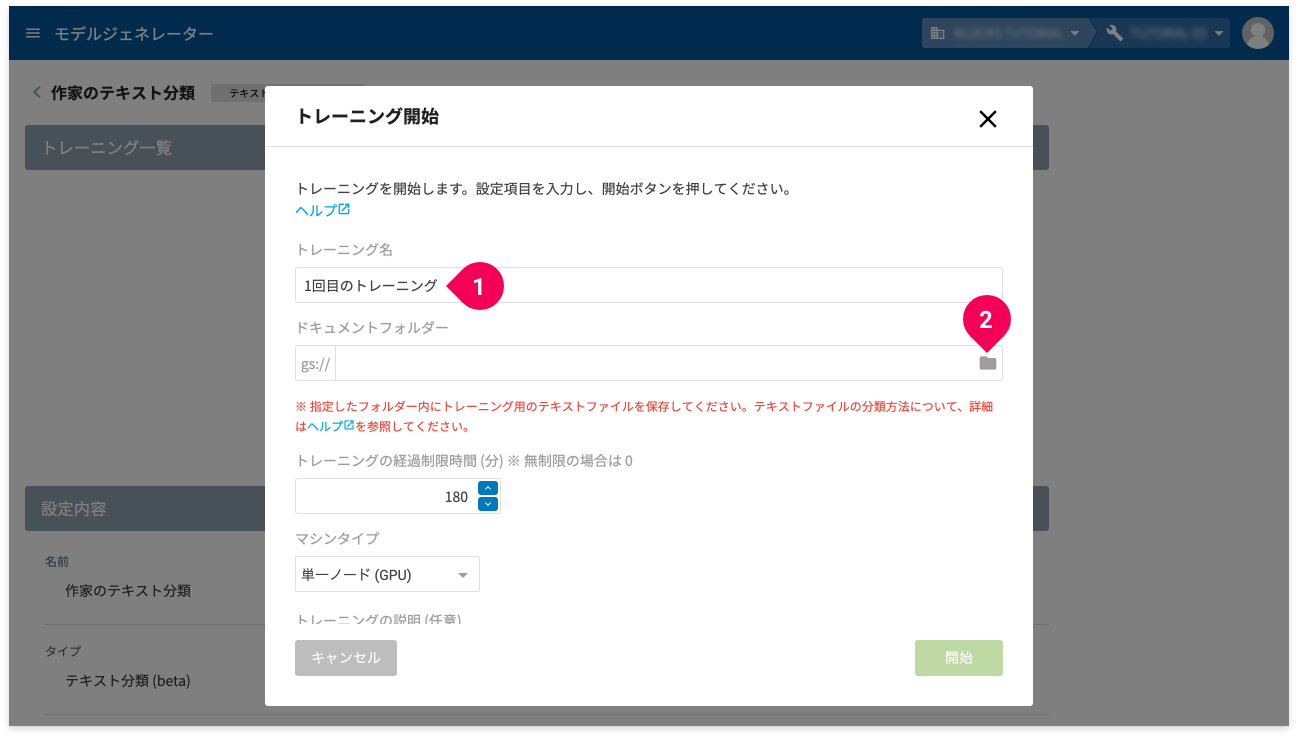
- トレーニング名を入力(例:
1回目のトレーニング) - folder アイコンをクリック
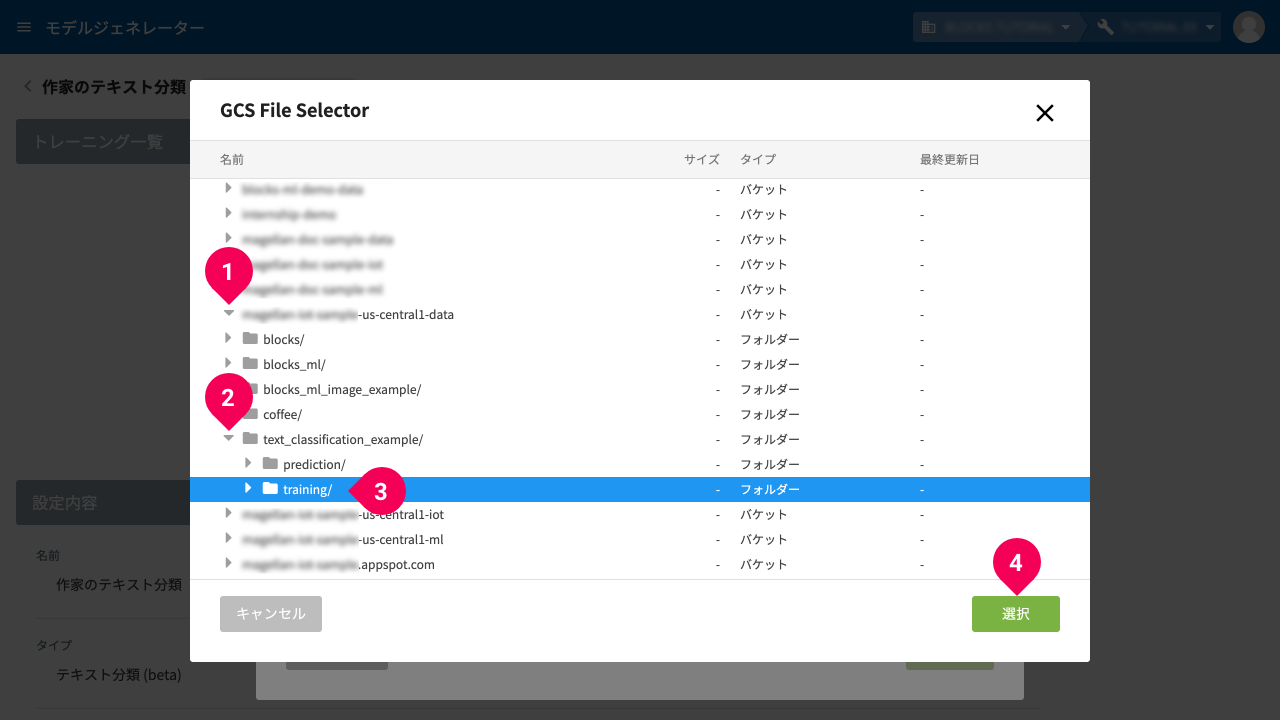
- -data で終わるバケット名の arrow_right アイコンをクリック
- folder text_classification_example の arrow_right アイコンをクリック
- folder training/ をクリック
- [選択]ボタンをクリック
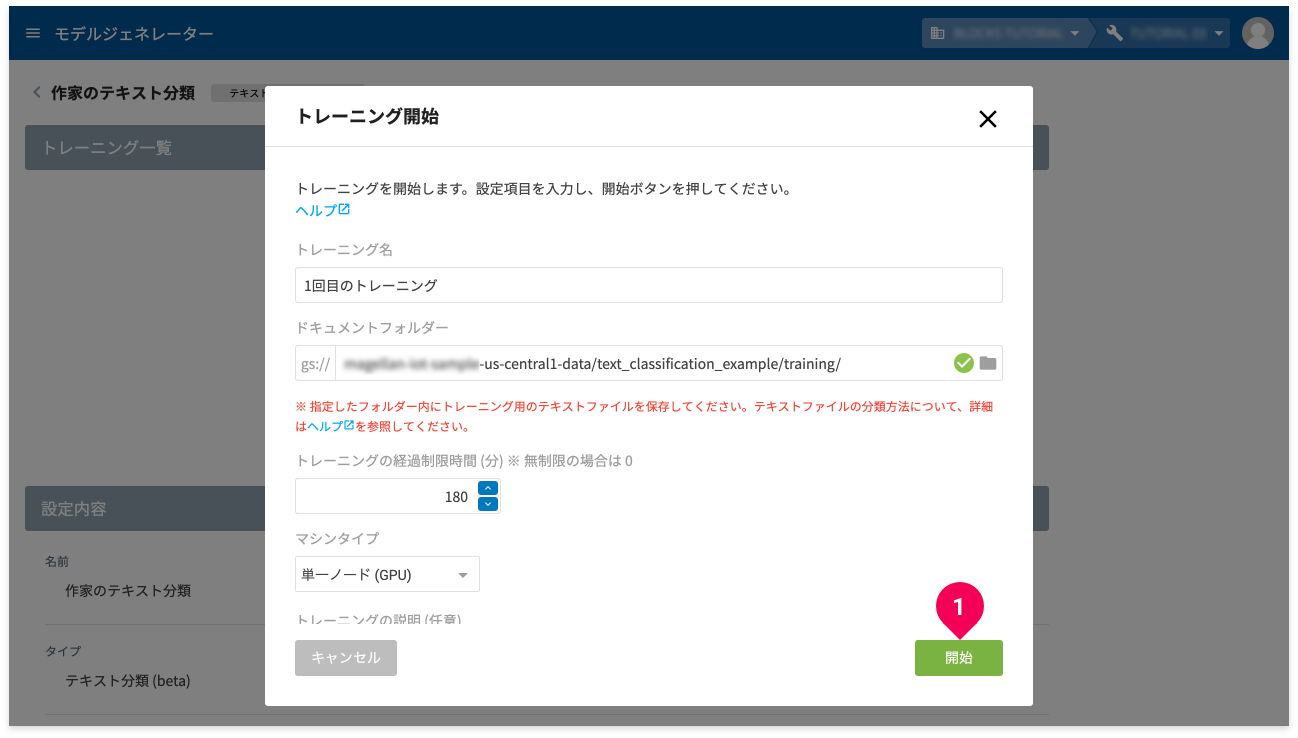
- [開始]ボタンをクリック
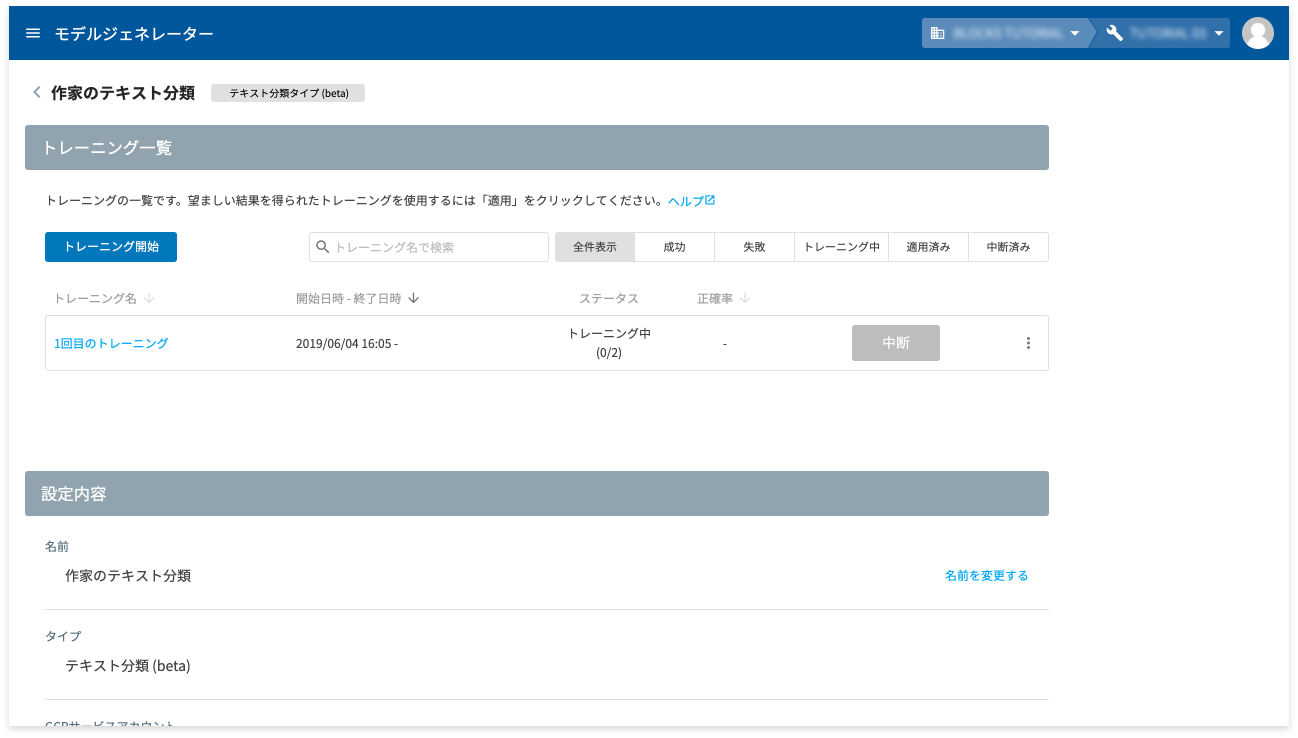
トレーニングが始まり、トレーニングの状況が画面内で確認できます。
トレーニングの所要時間は、4 時間ほどです(時間はサーバー側の状況により前後)。しばらくお待ちください。
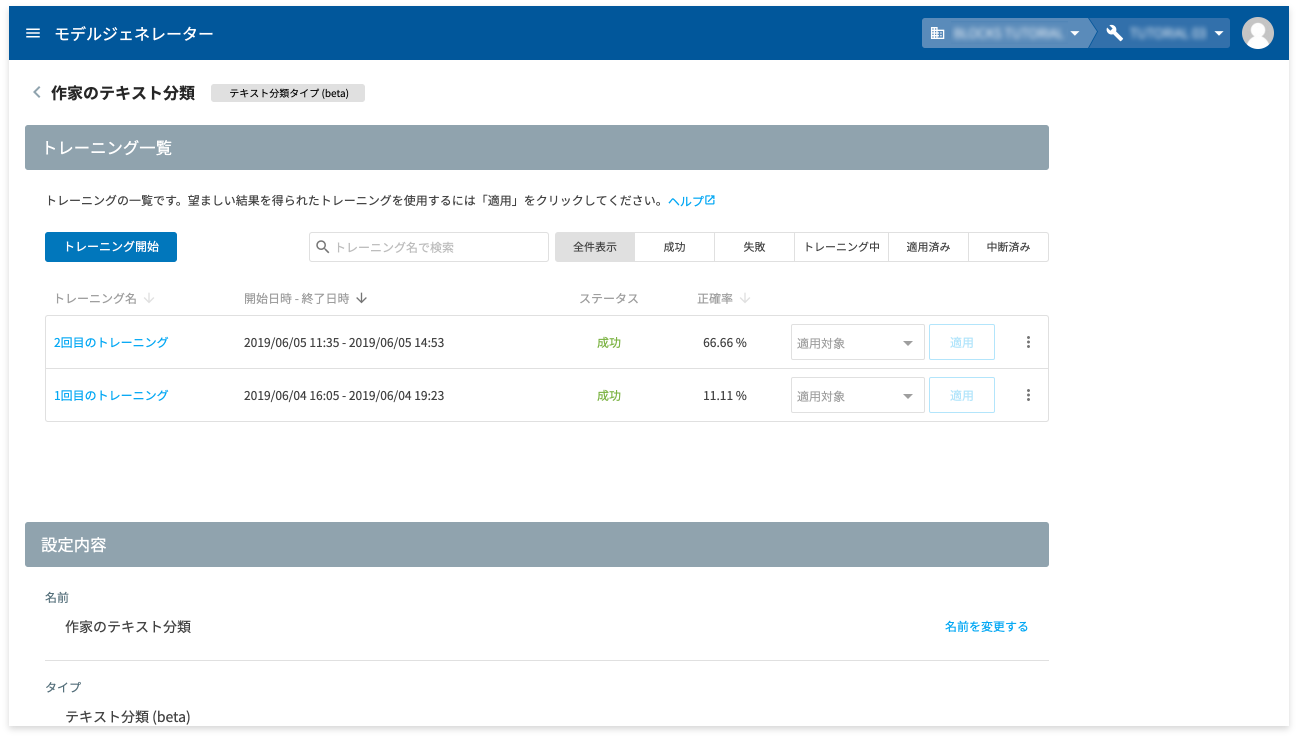
トレーニングが成功で終わると、トレーニング一覧の当該トレーニングのステータスが成功に変わります(上図例では、1 回目のトレーニングの正確率が悪かったため、2 回トレーニングを実施)。
このトレーニングのモデルを予測で使用するためには、このトレーニングのモデルを予測で使用することを明示する必要があります。モデルジェネレーターでは、この行為を適用と呼びます。
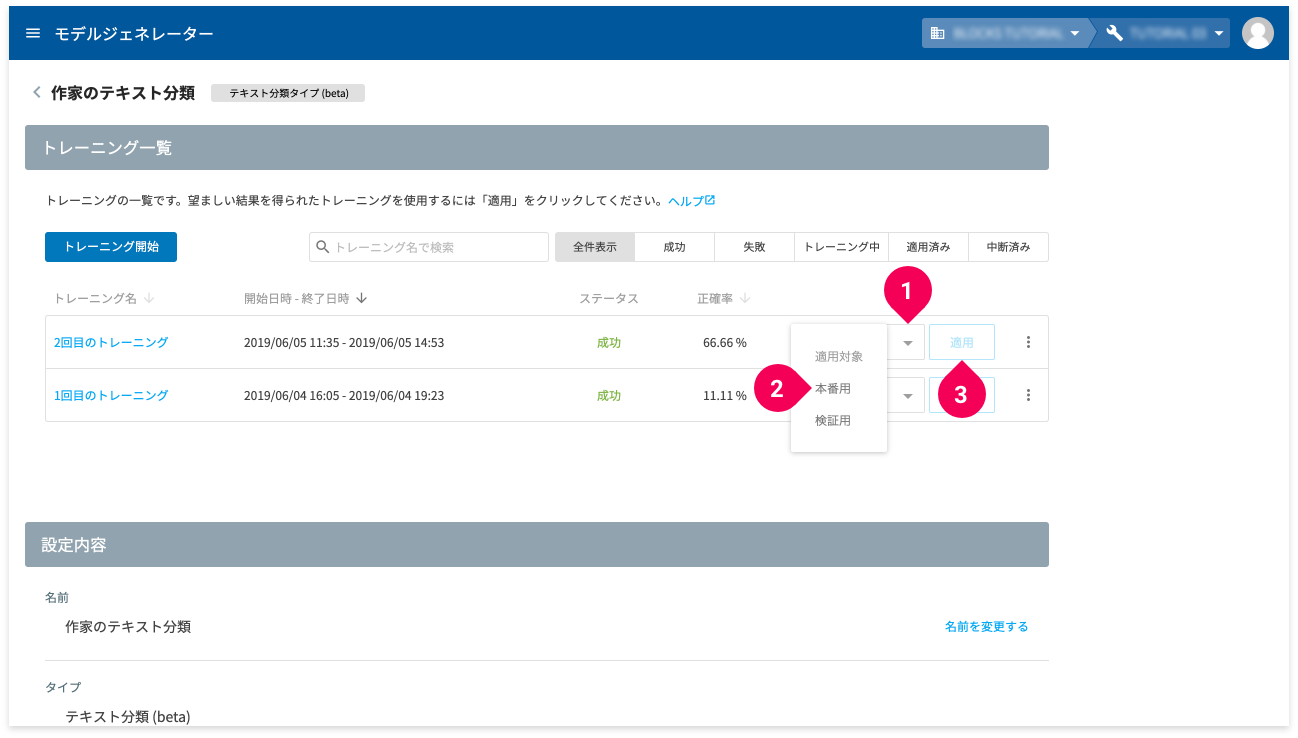
- arrow_drop_down アイコンをクリック
- 適用対象から[本番用]をクリック
- [適用]ボタンをクリック
info_outline 適用対象について詳しくは、モデルジェネレーターヘルプの「トレーニングを一覧する」のアクションの項を参照してください。
もし、トレーニングが失敗する場合は、再度トレーニングを実行してみてください。トレーニング失敗の理由の確認方法については、「操作中にエラーとなったら」を参考にしてください。
フローデザイナーを作成しよう
予測は、フローデザイナーで行います。フローデザイナーのフローテンプレート作成機能を活用すると、簡単に画像分類を予測するためのフローが作成できます。このチュートリアルでは、このフローテンプレートを使った方法を解説します。
- グローバルナビゲーション左端のメニューアイコン(menu)をクリック
- [フローデザイナー]をクリック
- [利用開始]ボタンをクリック
info_outline 既にフローデザイナーを作成している場合は、「フローデザイナーとは」の画面は表示されません。後で述べるフローデザイナーの一覧画面が表示されます。その場合は、既存のフローデザイナーの名前をクリックして、以降の作業を進めてください。もし無料トライアル以外をお使いで、新たにフローデザイナーを作成できるライセンス枠がある場合は、フローデザイナー一覧画面の左上にある[追加]ボタンをクリックしてください。
- 名前を入力(例:
チュートリアル) - [作成]ボタンをクリック
これで、フローデザイナーが作成できました。
フローテンプレートでフローを生成しよう
作成したフローデザイナーのフローテンプレート作成機能を使って、予測を行うフローを作成します。
- [チュートリアルopen_in_new]をクリック
ウェブブラウザーの新しいタブにフローデザイナーが開きます。
- [フローテンプレート作成]ボタンをクリック
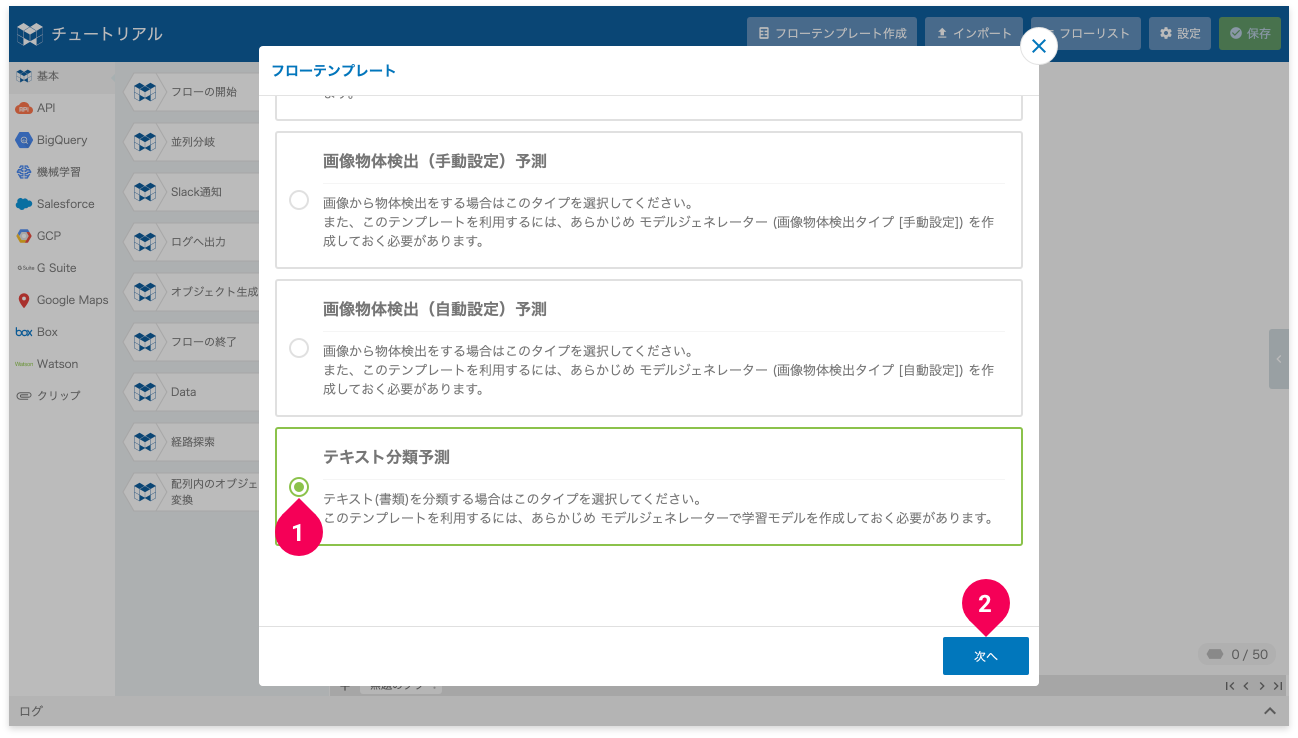
- [テキスト分類予測]をクリック
- [次へ]ボタンをクリック
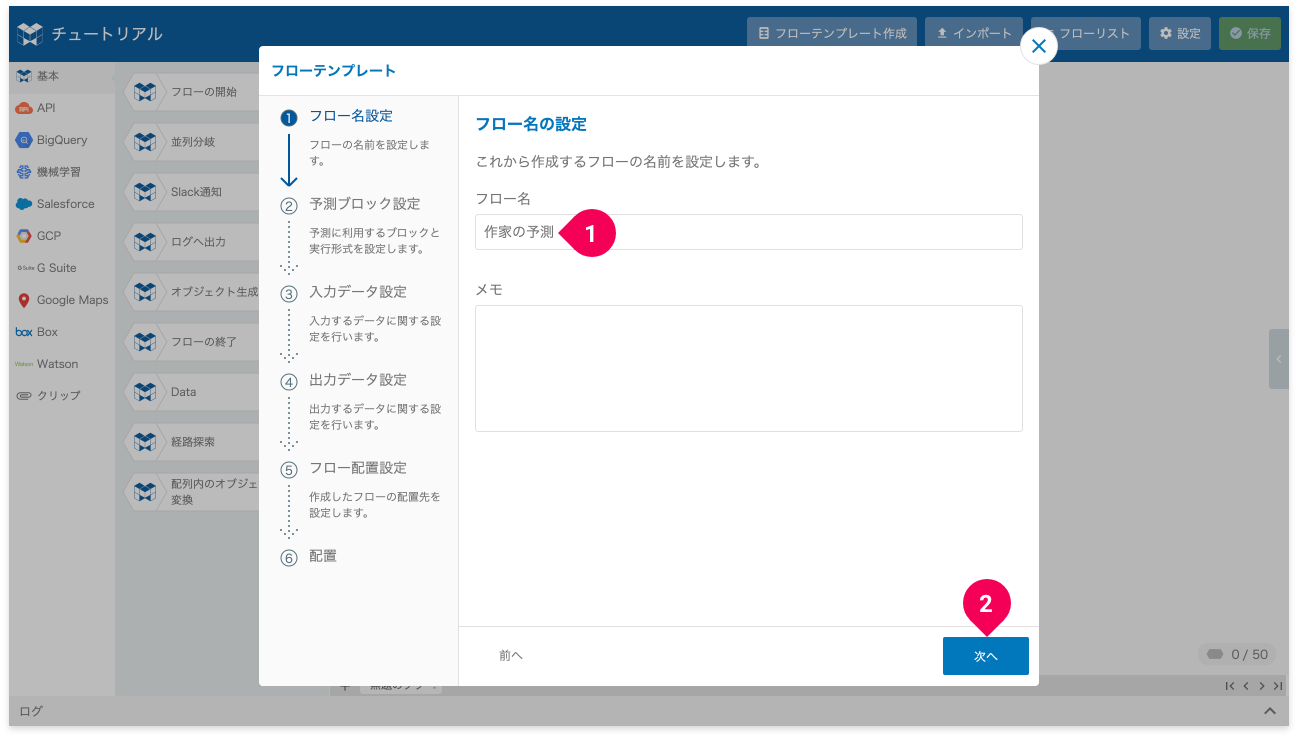
- フロー名を入力(例:
作家の予測) - [次へ]ボタンをクリック
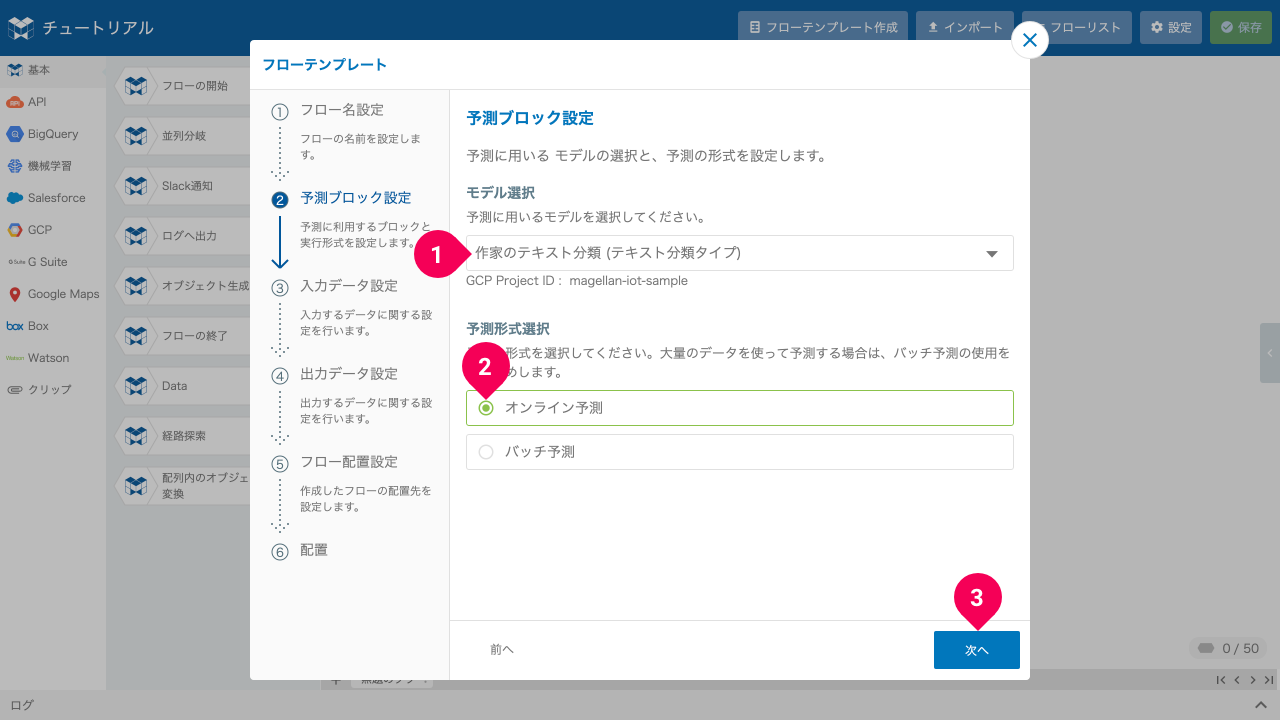
- [作家のテキスト分類 (テキスト分類タイプ)]をクリック
- [オンライン予測]をクリック
- [次へ]ボタンをクリック
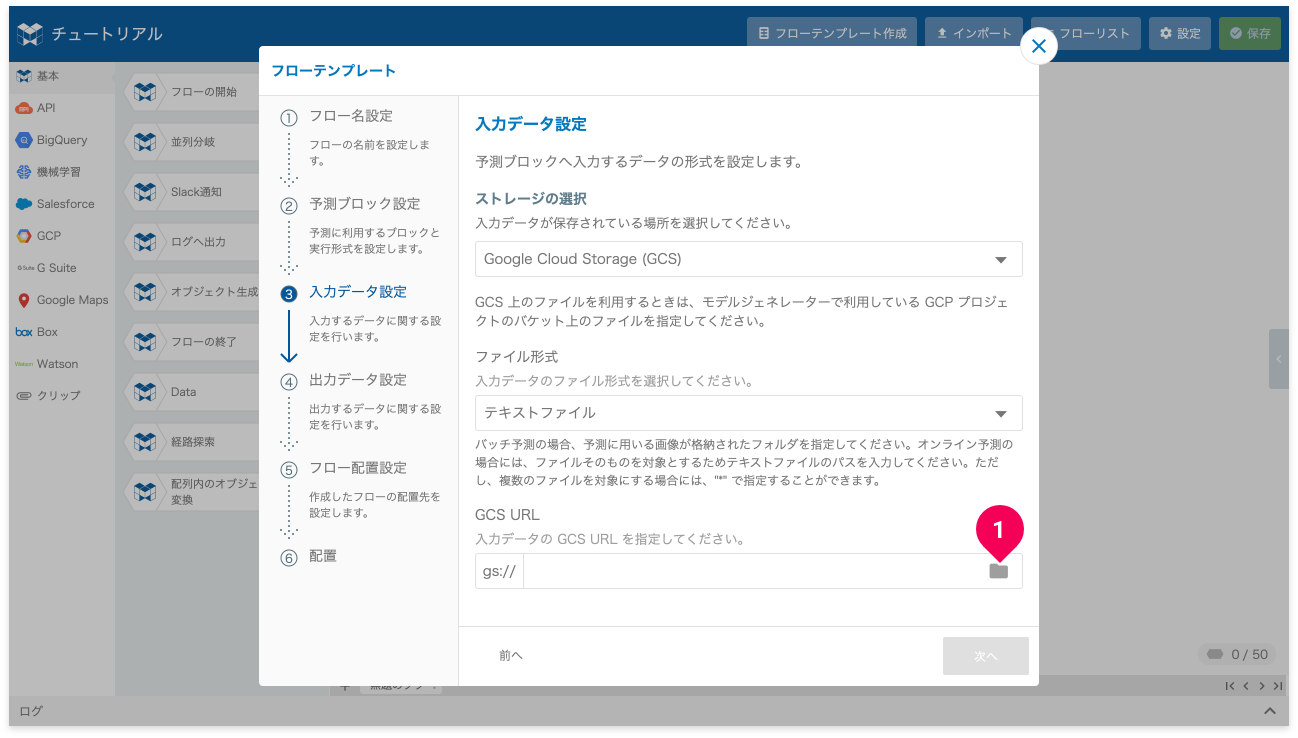
- GCS URL の folder アイコンをクリック
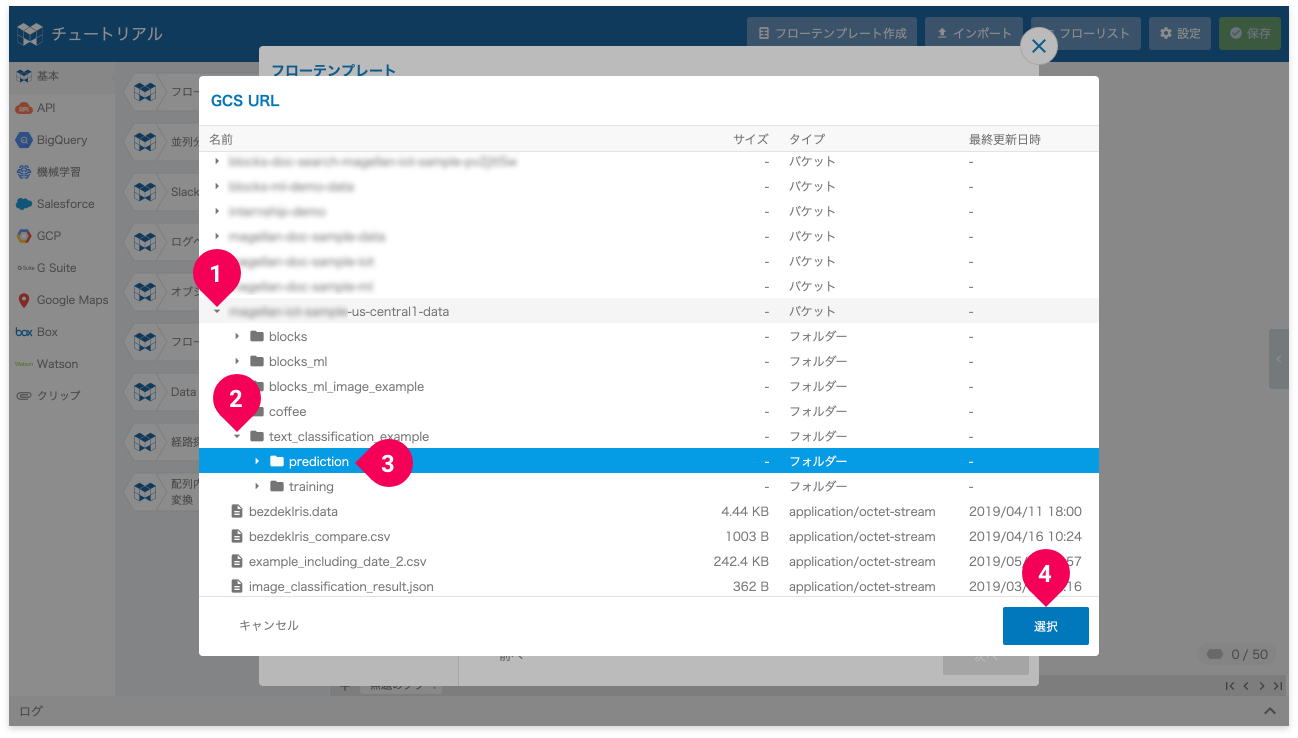
- -data で終わるバケット名の arrow_right をクリック
- folder text_classification_example の arrow_right をクリック
- folder prediction をクリック
- [選択]ボタンをクリック
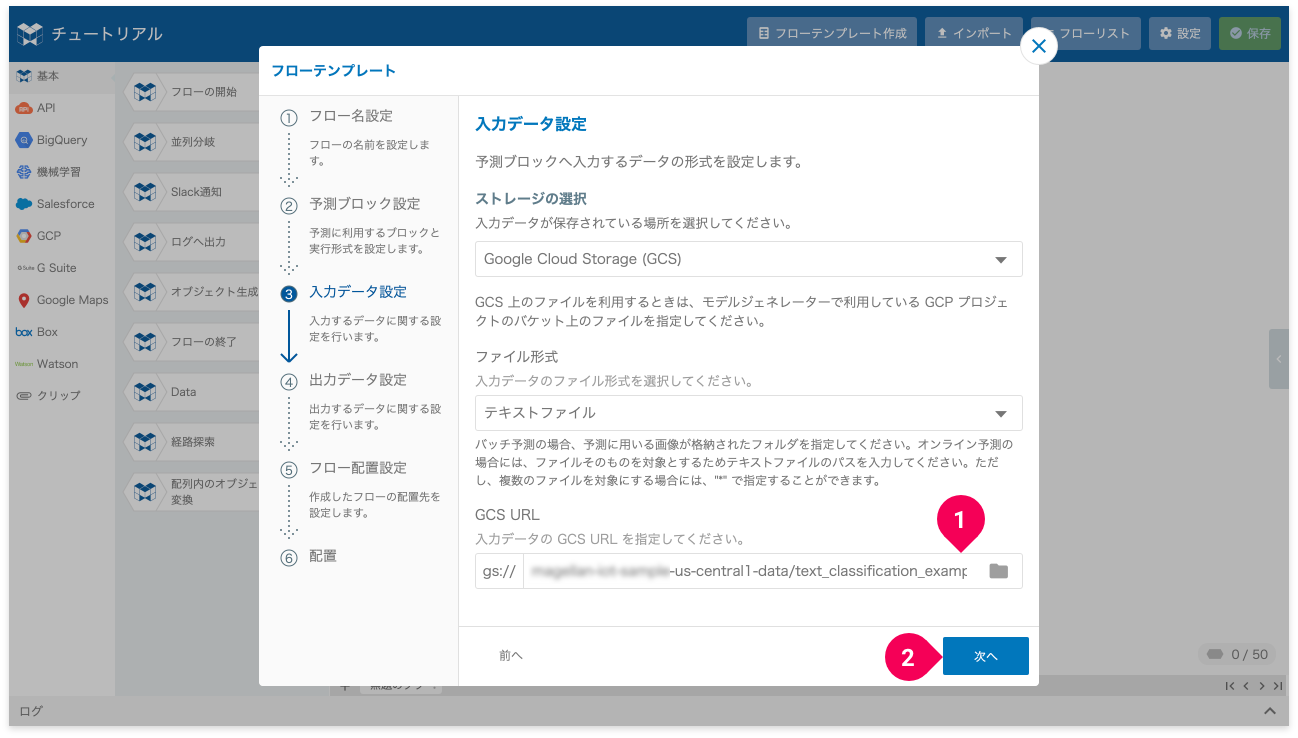
- GCS URL の末尾に
*を入力(例:.../text_classification_example/prediction/*) - [次へ]ボタンをクリック
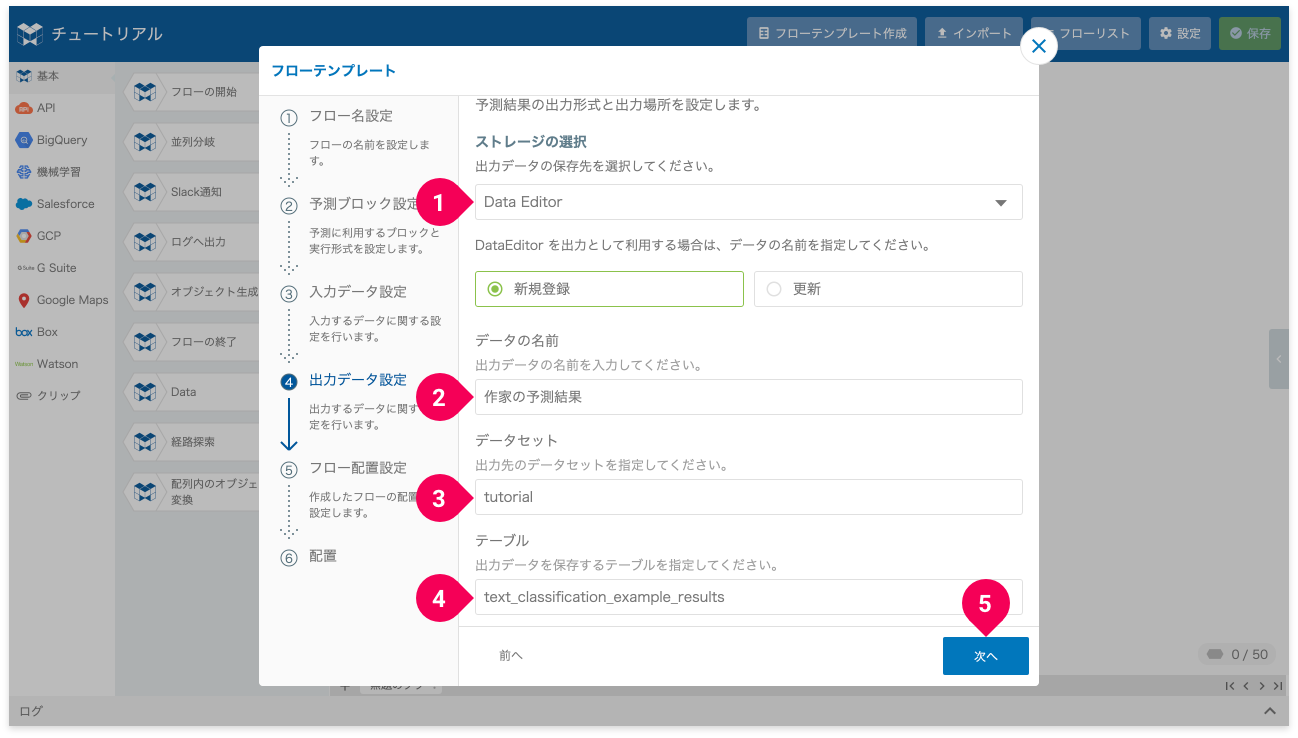
- ストレージの選択で[DataEditor]をクリック
- データの名前を入力(例:
作家の予測結果) - データセットを入力(例:
tutorial) - テーブルを入力(例:
text_classification_example_results) - [次へ]ボタンをクリック
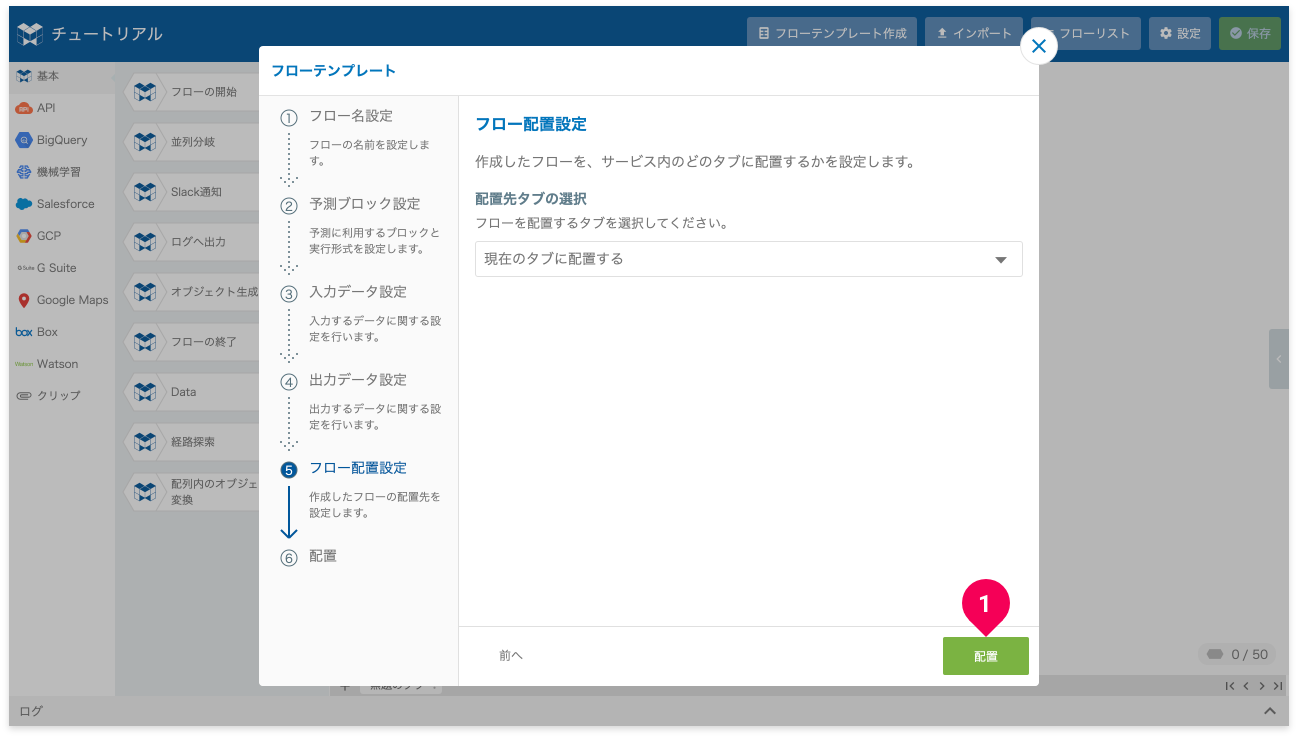
- [配置]ボタンをクリック
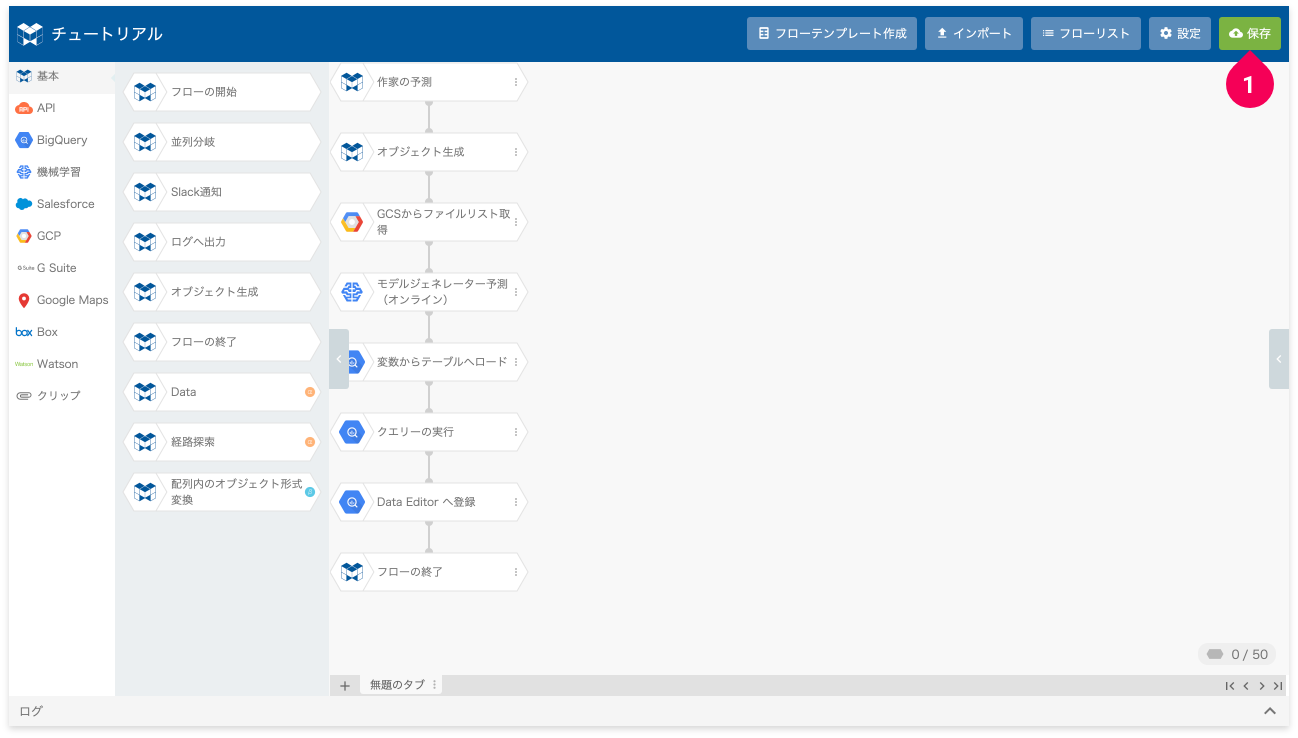
- [保存]ボタンをクリック
これで、予測フローの作成は完了です。
info_outline 作成したフローは、必ず保存しましょう。保存しないと、フローは実行できません。また保存せずにフローデザイナーのタブを閉じたり、ウェブブラウザーを閉じると、作成したフローは無くなります。
生成したフローで予測をしよう
早速、作成した予測フローで、予測を実行してみます。
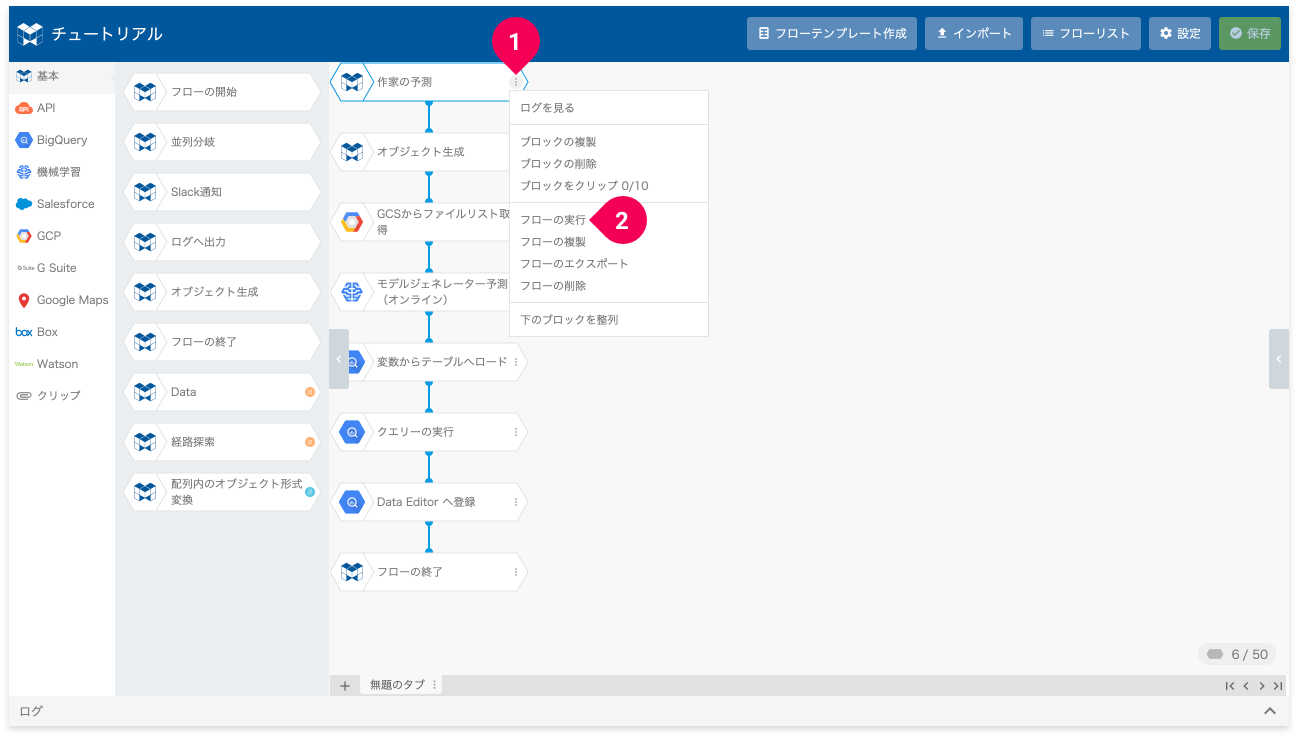
- フロー先頭の[作家の予測]ブロック右端の more_vert をクリック
- [フローの実行]をクリック
フローの実行状況を確認するには、フローの実行ログを参照します。
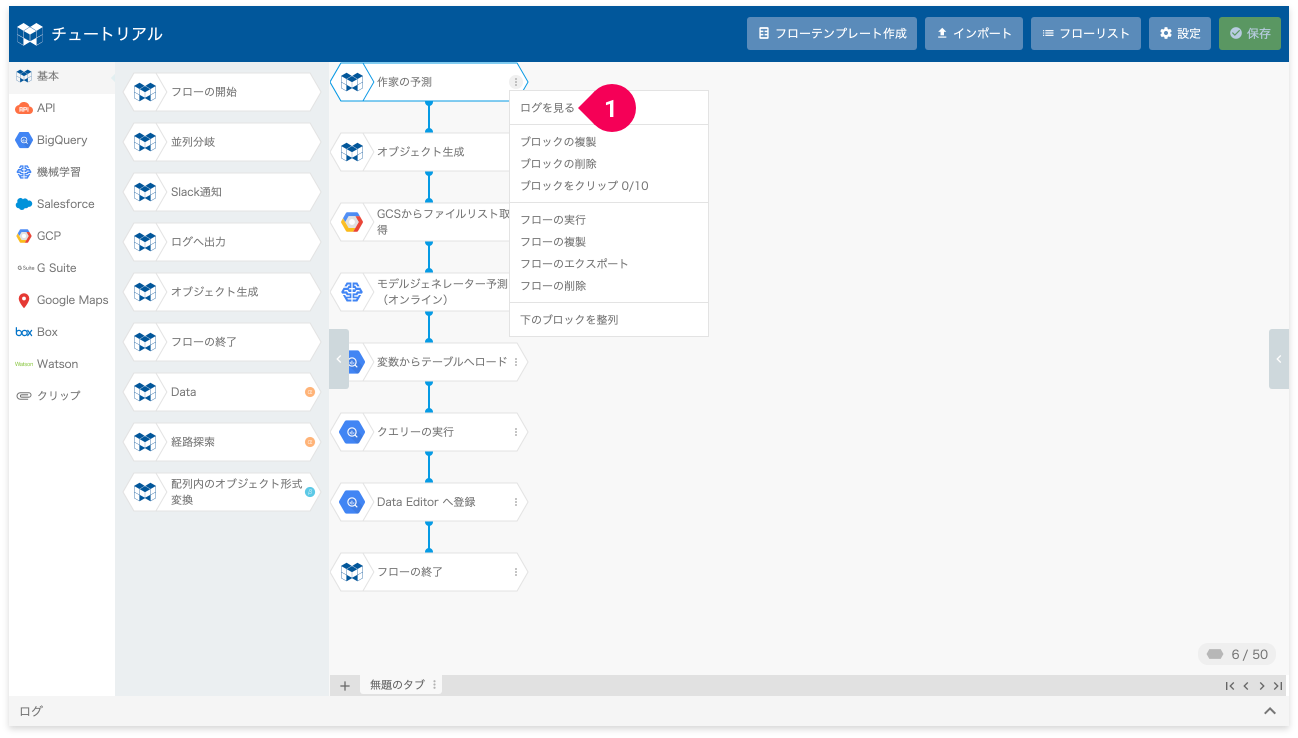
- [ログを見る]をクリック
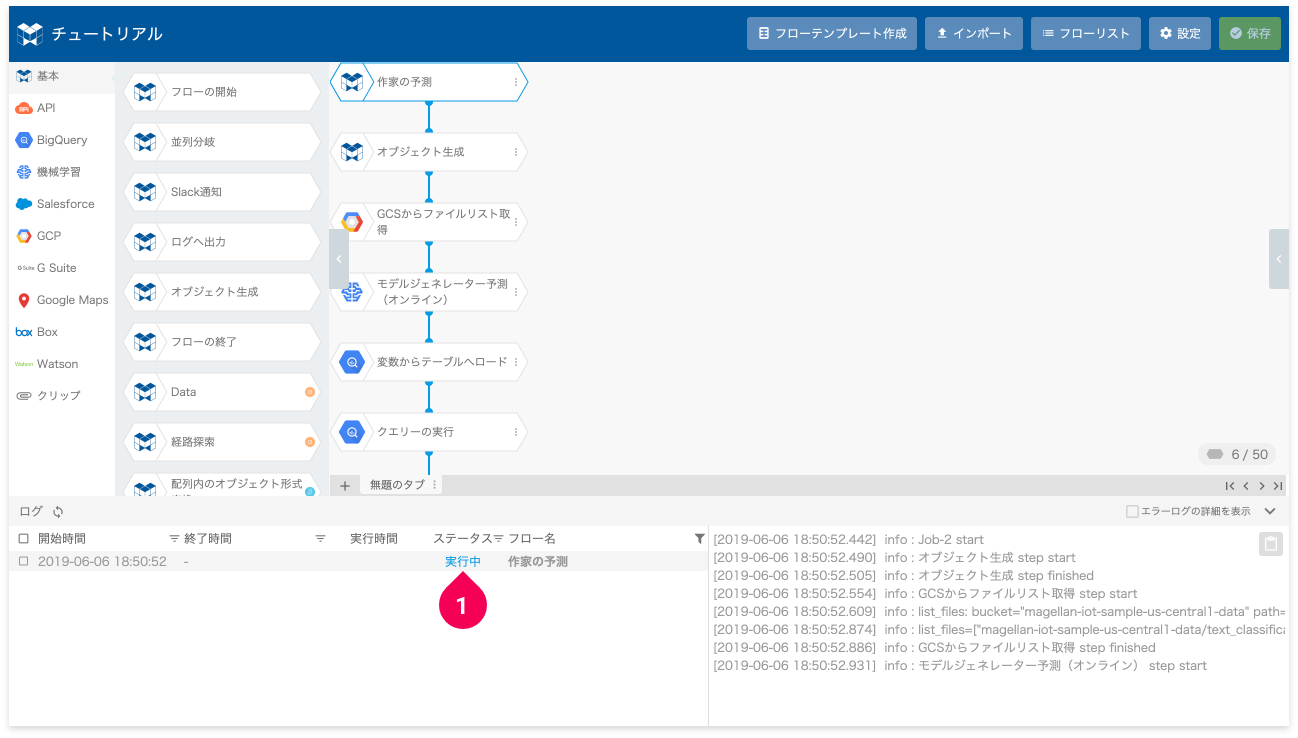
- ステータスが[実行中]となっていることを確認
フローの実行が終わるまで、しばらく待ちます。
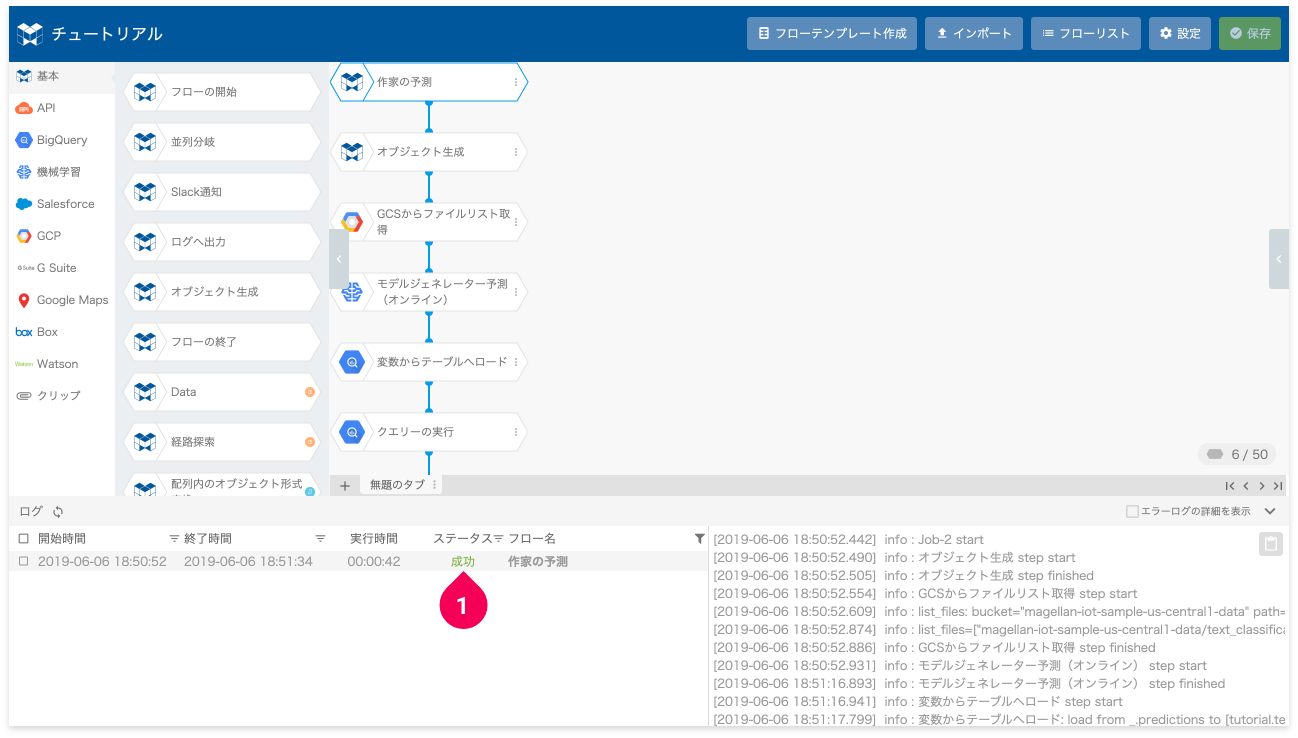
- ステータスが[成功]となることを待つ
これで予測の完了です。
もし、予測に失敗する場合は、再度フローを実行してみてください。フローの実行に失敗する理由の確認方法については、「操作中にエラーとなったら」を参考にしてください。
予測結果を確認しよう
予測結果は、DataEditor のデータとして出力しているので、DataEditor で確認します。別タブにある BLOCKS の画面(フローデザイナーの一覧画面)に切り替えます。

- グローバルナビゲーション左端のメニューアイコン(menu)をクリック
- [DataEditor]をクリック
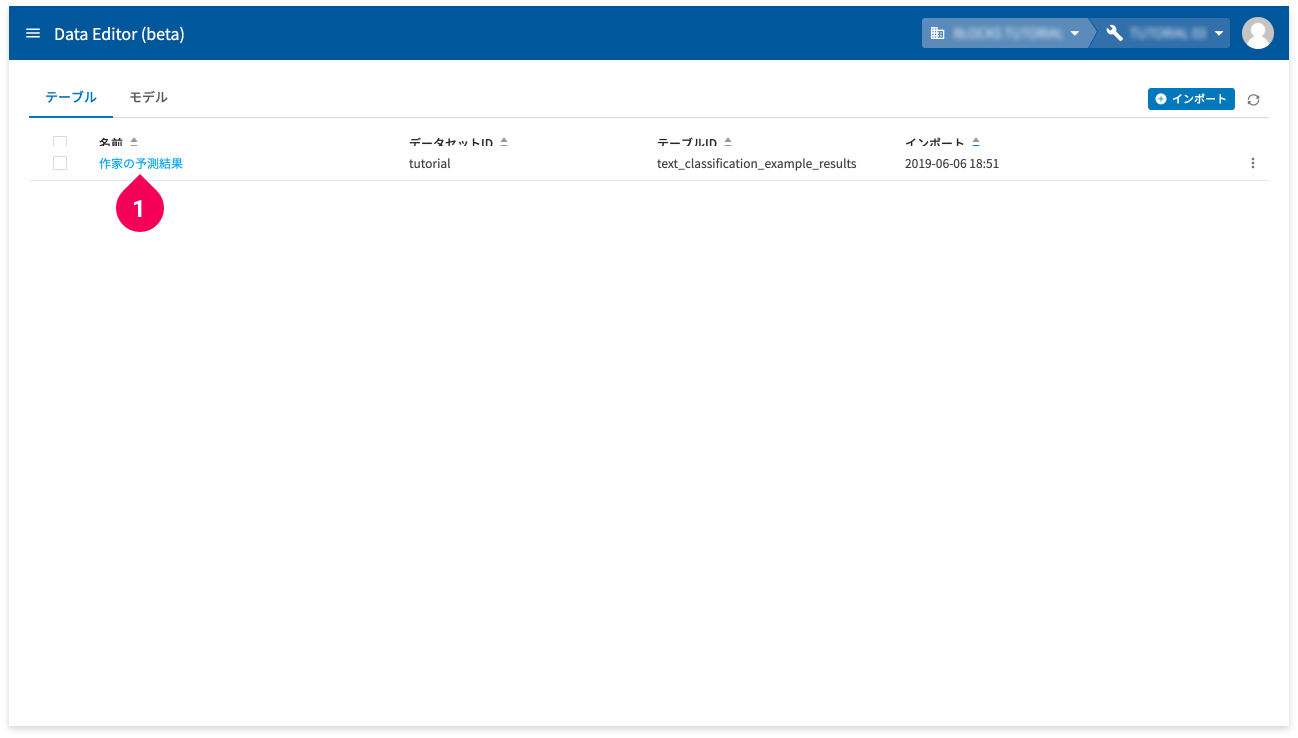
- [作家の予測結果]をクリック
- [データを表示]をクリック
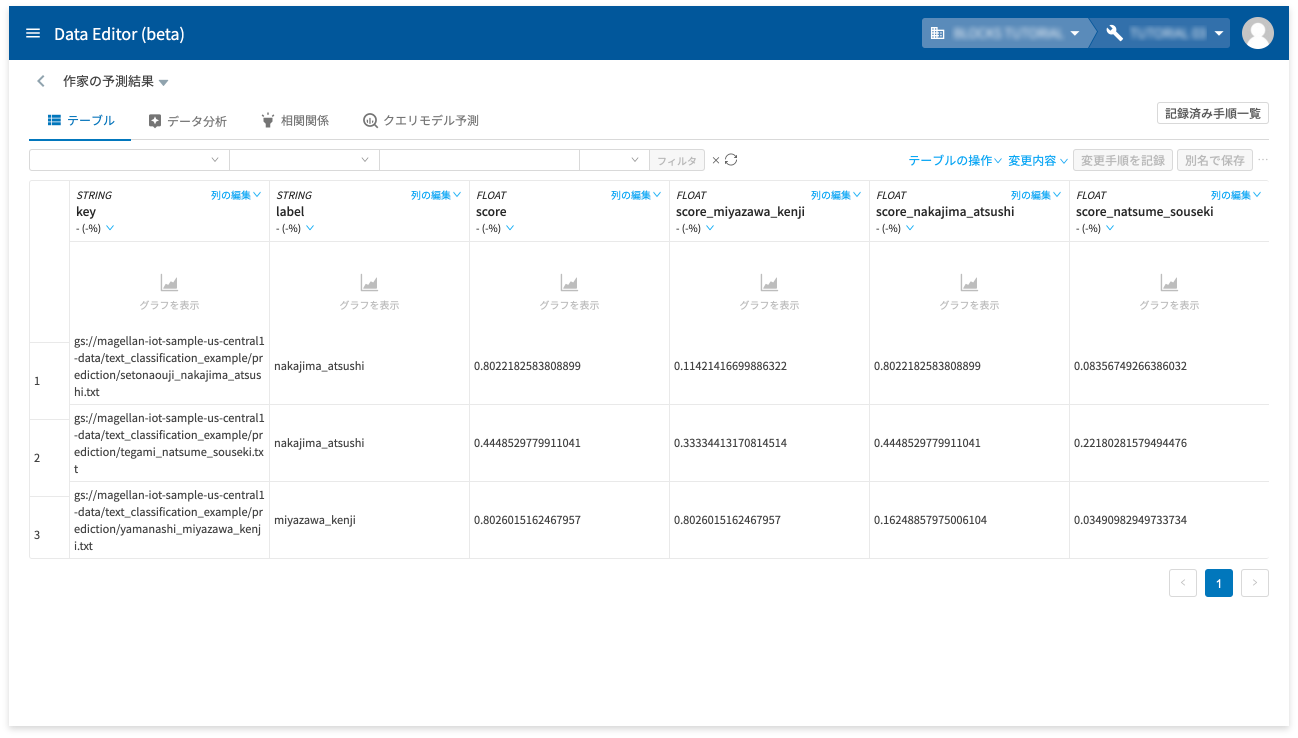
各列のそれぞれの意味は、以下のとおりです。
| 名前 | 説明 |
|---|---|
| key |
予測用テキストファイルの GCS URL です。 |
| label |
予測結果です。 今回の例では、各作家に対応した以下のいずれかが表示されます。
|
| score |
予測結果の確からしさです。数値は、0 から 1 の範囲で、1 が 100% を示します。 |
| score_miyazawa_kenji score_nakajima_atsushi score_natsume_souseki |
各分類ごとにどのくらいの可能性があるかを示す値です。数値は、0 から 1 の範囲で、1 が 100% を示します。 |
DataEditor のデータは、CSV ファイルに書き出せます(エクスポート)。CSV ファイルに書き出すことで、データをさまざまな形で取り扱うことができて便利です。
では、実際に CSV ファイルをエクスポートしてみます。
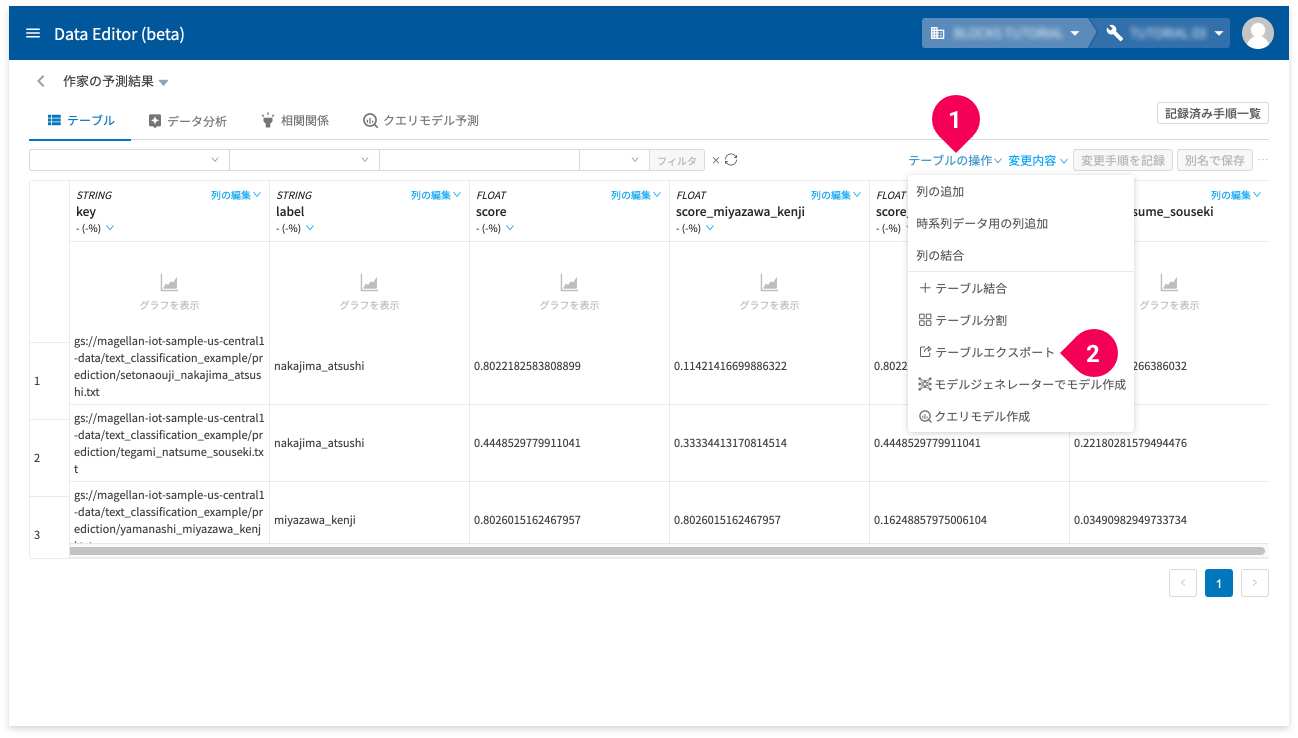
- [テーブルの操作]をクリック
- [テーブルエクスポート]をクリック
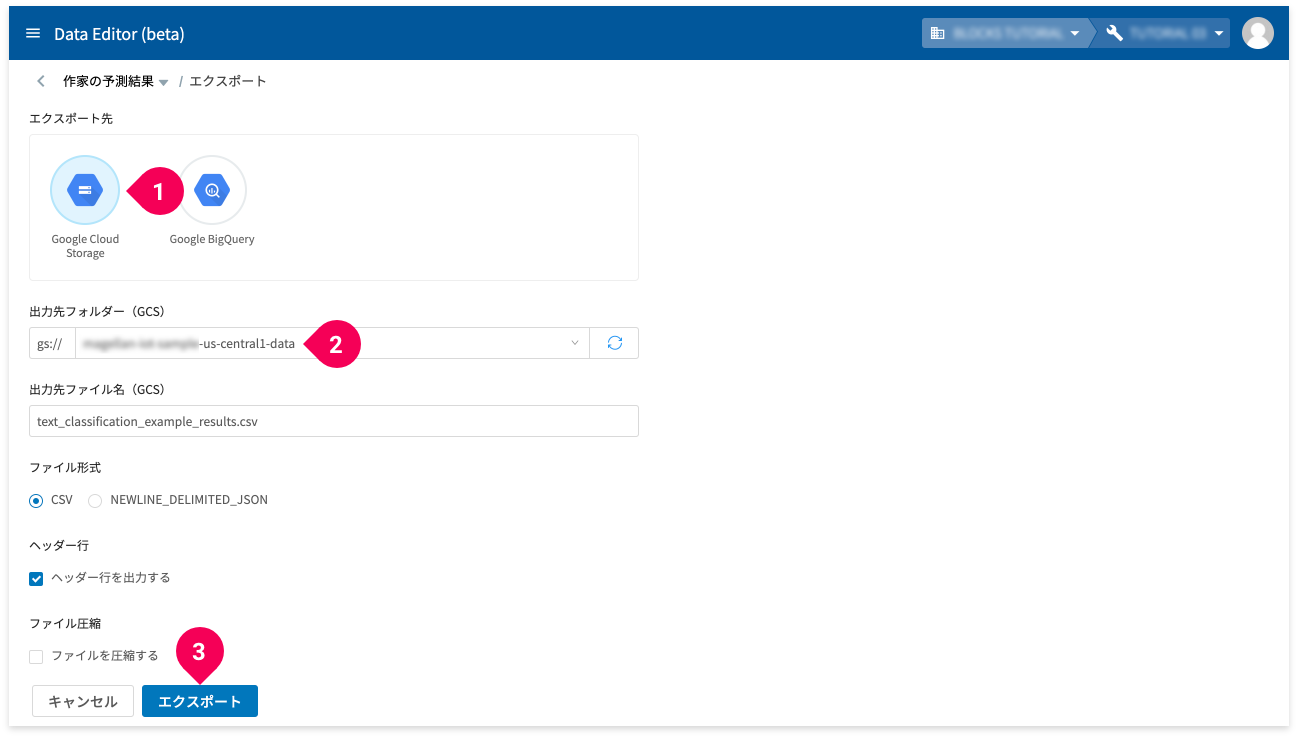
- エクスポート先から[Google Cloud Storage]をクリック
- 出力先フォルダー(GCS)から末尾が -data の項目をクリック
- [エクスポート]ボタンをクリック

- ファイル名をクリックして PC に CSV ファイルを保存
- [OK]ボタンをクリック
エクスポート機能は、データを Google Cloud Storage にファイルを保存する機能ですが、エクスポート完了の画面で表示されるリンクをクリックすることで PC にもファイルが保存できます。
操作中にエラーとなったら
エラー内容は、モデルジェネレーターの場合は、トレーニング詳細画面の「エラー内容」で確認できます。以下に、モデルジェネレーターでのエラー内容の確認方法を紹介します。
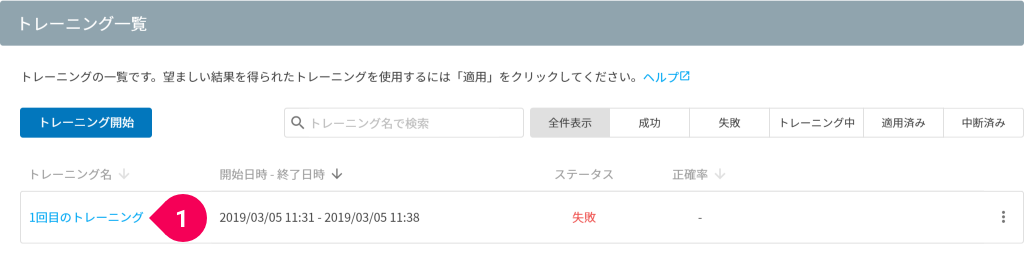
- ステータスが[失敗]と表示されているトレーニングのトレーニング名をクリック
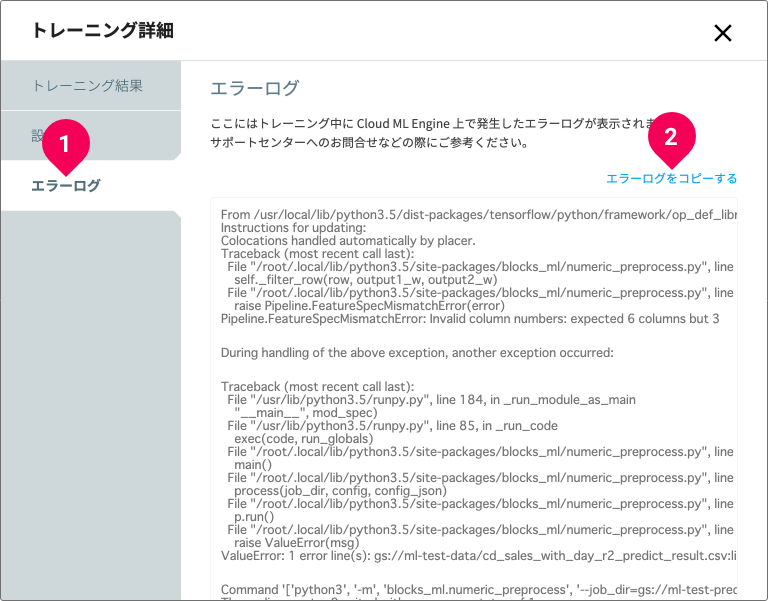
- [エラーログ]をクリック
- [エラーログをコピーする]をクリック(問い合わせをする場合)
フローデザイナーの場合は、先に紹介したログパネルで確認できます。
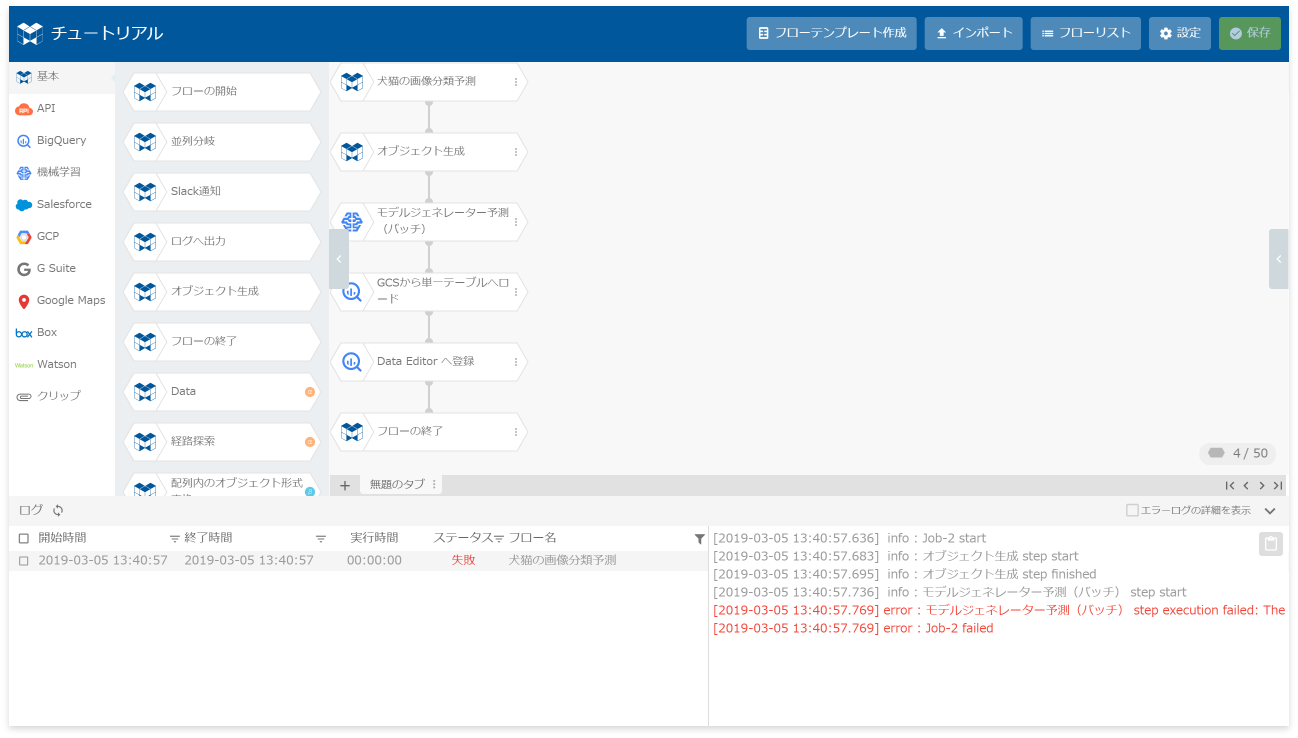
エラー部分が赤字で表示されます。
エラーの原因を特定するには、エラー部分を中心に前後のメッセージも含めて読み解くと良いです(フローデザイナーは、[エラーログの詳細を表示]チェックボックスをチェック)。
エラーが発生し、何度リトライしても失敗するようであれば、グローバルナビゲーション右端のユーザーアイコンをクリックして表示される[お問い合わせ]からエラー内容をテキストファイル化したファイルを添付してお問い合わせください。エラー内容をテキストファイル化する場合は、赤字のエラー部分だけではなく、すべてのエラーメッセージを含めてください(フローデザイナーは、[エラーログの詳細を表示]チェックボックスをチェック)。
フローデザイナーでエラーが発生する場合は、フローをエクスポートした JSON ファイルも添付してください。
info_outline お問い合わせについて詳しくは、基本操作ガイドの「お問い合わせ」を参考にしてください。
まとめ
このように、BLOCKS を使うと、テキストファイルをフォルダーごとに分けて準備するだけの手軽さで、機械学習によるテキスト分類が利用できます。
最後に、BLOCKS のテキスト分類用に準備するテキストファイルの留意事項をまとめておきます。
- トレーニングに使用するテキストファイルは、分類する種類ごとにフォルダーに分けて配置します。
- トレーニングで使用する文章は、ファイルの先頭から 2,000 文字までです。2,000 文字を超える文章を用意しても構いませんが、2,000 文字以降は無視されます。2,000 文字を超えるすべての文章をトレーニングで使用したい場合は、複数ファイルに分割してください(各ファイル 2,000 文字以内)。
- テキストファイルは、BOM なし UTF-8 で準備してください。
- テキストファイルの拡張子は、.txt で準備してください(大文字・小文字の区別なし)。