機械学習
ARIMA+(時系列)モデルの作成【アルファ版】
このブロックはアルファ版です。利用にあたっては利用申請が必要です。提供している機能は完全でない場合があり、下位互換性のない変更を加える可能性もあります。このため、テスト環境での使用に適しています。利用申請/機能改善の要望/不具合の報告などは、MAGELLAN BLOCKSのお問い合わせ機能からお願いします。
概要
このブロックは、BigQuery MLを使い、BigQuery上のトレーニングデータで 時系列モデルを作成します。モデルは、BigQueryとDataEditorに登録されます。

このブロックを利用することで、時系列モデルを利用した以下のようなユースケースに対応できます。
- 蓄積されていくデータを用いた再学習
- モデル作成の試行錯誤
留意事項
- トレーニングデータには、時間経過を表すデータカラムと、推論/予測対象のデータカラムが必要です。
時間経過を表すデータカラムのデータ型は、日付型(DATE型)/日時型(DATETIME型)/タイムスタンプ型(TIMESTAMP型)のいずれかである必要があります。 - このブロックは、モデル作成の完了を待たずに終了します。
トレーニングの状態や結果は、DataEditorのモデル一覧で確認できます。 - 「Slack通知設定」プロパティを利用すると、モデル作成の完了をSlackで確認できます。
「Slack通知設定」プロパティで指定する内容は、あらかじめプロジェクト設定の通知設定で作成しておきます。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
| GCPサービスアカウント |
GCPサービスアカウントのリストから適切なGCPサービスアカウントを選択します。 |
| 入力BigQueryデータセット |
トレーニングデータを格納したBigQueryテーブルが属するBigQueryデータセットを指定します。 |
| 入力BigQueryテーブル |
トレーニングデータを格納したBigQueryテーブルを指定します。 |
| モデル名 |
DataEditorで参照する際のモデルの名前を指定します。 DataEditorに登録済の名前を指定するとモデルは更新されます。 |
| トレーニング完了時に付加するタグ名 |
トレーニングが完了した際に、タグも同時に付けたい場合に指定します。 タグは、別途「推論/予測に使用するタグの設定」ブロックを使って、後付けできます。 |
| 日付/日時/タイムスタンプのカラム名 |
時間経過を表すデータカラムを指定します。 指定できるカラムのデータ型は、以下のいずれかです。 |
| 推論/予測の対象に使用するカラム名 |
トレーニングデータの推論/予測の対象に使用するカラム名を指定します。 |
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 |
| トレーニング完了時からのモデル保持日数(0は制限なし) |
トレーニング完了時点からモデルを保持する日数を指定します。指定した日数を経過するとモデルは自動で削除されます。0日を指定すると、自動削除されません。 初期値は、0日です。 |
| 予測する期間の数 |
予測したい期間の長さを指定します。 単位は、日付/日時/タイムスタンプのカラムのデータ頻度の扱いによります。そのカラムのデータが、月ごとの扱いであれば月単位、日ごとの扱いであれば日単位となります。 |
| ARIMAモデルの最適な順序を自動的に検出する |
AIC(Akaike Information Criterion:赤池情報量規準)が最も低い最適なモデルを自動的に検出するかどうかを指定します。
|
| 非季節性の自己回帰係数(p)と移動平均係数(q)の合計の最大値 |
自己回帰係数(p)と移動平均係数(q)の合計の最大値を指定します。指定できる値は、1から5の整数です。 「ARIMAモデルの最適な順序を自動的に検出する」プロパティがオフ()の場合は、指定できません。 |
| 時系列の種類の列(複数の時系列の場合に指定) |
複数の時間経過を表すデータカラムがある場合は、その数分のカラムが指定できます。 |
| 非季節性の自己回帰係数(p) |
ARIMAモデルの最適な順序を自動的に検出しない場合は、非季節性の自己回帰係数(p)を指定します。 「ARIMAモデルの最適な順序を自動的に検出する」がオン()の場合は、指定できません。 |
| 非季節性の差分を取る回数(d) |
ARIMAモデルの最適な順序を自動的に検出しない場合は、非季節性の差分を取る回数(d)を指定します。 「ARIMAモデルの最適な順序を自動的に検出する」がオン()の場合は、指定できません。 |
| 非季節性の移動平均係数(q) |
ARIMAモデルの最適な順序を自動的に検出しない場合は、非季節性の移動平均係数(q)を指定します。 「ARIMAモデルの最適な順序を自動的に検出する」がオン()の場合は、指定できません。 |
| モデルにドリフト項が含まれる |
モデルにドリフト項を含めるかどうかを指定します。 「ARIMAモデルの最適な順序を自動的に検出する」プロパティがオン()の場合は、自動的に決定されます。 |
| 時系列のデータ頻度 |
トレーニングデータの時間経過を表すデータカラムのデータ頻度を指定します。
|
| 休日効果を適用する |
休日効果を適用したい場合は、適用したい国や地域を選択します。 休日効果を有効にすると、休日中に見られる異常な増大と減少が異常として処理されなくなります。 |
| 時系列データの異常値を除去する |
時系列データの異常値を除去するかどうかを指定します。
|
| 時系列データの変化点を検知し自動調整する |
時系列データの変化点を検知し自動調整するかどうかを指定します。
|
| 時系列(履歴部分と予測部分)を分解し結果をモデルに保存する |
時系列(履歴部分と予測部分)を分解し結果をモデルに保存するかどうかを指定します。
|
| 時系列トレンドコンポーネントのモデル化に使用される、時系列の補間された長さの割合 |
時系列トレンドコンポーネント(成分)をモデル化するために使用される時系列の補間された長さの割合を指定します。時系列のすべての時点は、非トレンド成分をモデル化するために使用されます。たとえば、時系列に100個の時点がある場合、0.5を指定すると、モデリングに最新の50個の時点が使用されます。このパラメーターを使用すると、予測精度を犠牲にすることなくトレーニングが高速化できます。 値は0から1の範囲内でなければなりません。初期値(1.0)では、時系列内のすべての時点が使用されます。 このパラメーターは、「時系列のトレンドコンポーネントのモデル化に使用される時系列の最小時点数」と併用できますが、「時系列のトレンドコンポーネントのモデル化に使用される時系列の最大時点数」とは併用できません。 |
| 時系列のトレンドコンポーネントのモデル化に使用される時系列の最小時点数 |
時系列のトレンドコンポーネント(成分)をモデル化する際に使用される時系列の最小の時点数を指定します。 値は、4以上の数値を指定してください。 このパラメーターは、「時系列トレンドコンポーネントのモデル化に使用される、時系列の補間された長さの割合」と併用して使用します。 |
| 時系列のトレンドコンポーネントのモデル化に使用される時系列の最大時点数 |
時系列のトレンドコンポーネント(成分)のモデル化に使用される時系列の最大時点数を指定します。 値は、4以上の数値を指定してください。最初に試す数値としては、30をおすすめします。 このパラメーターは、「時系列トレンドコンポーネントのモデル化に使用される、時系列の補間された長さの割合」または「時系列のトレンドコンポーネントのモデル化に使用される時系列の最小時点数」と併用できません。 |
| Slack通知設定(省略可) |
モデル作成完了時に、Slackへその旨のテキストメッセージを送信したい場合に、プロジェクト設定の通知設定で設定したSlack通知の名称を指定します。 Slack通知のイメージ: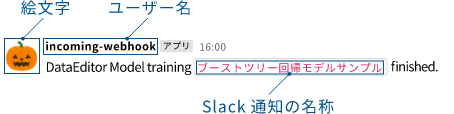
モデルの作成が完了したにも関わらずSlackに通知が来ない場合は、何らかの原因(指定したチャンネルがないなど)でSlackの通知に失敗している可能性があります。その場合は、プロジェクト設定の通知設定を確認してください。Slackの通知に失敗している場合は、失敗に関するメッセージが確認できます。 |
| Slack通知チャンネル設定(省略可) |
通知先のSlackチャンネルを指定します。 チャンネルを指定した場合は、プロジェクト設定の通知設定のチャンネルは無視されます。 省略した場合は、通知設定で指定されたチャンネルへ通知されます。 |
| Slack通知ユーザー名設定(省略可) |
通知する際のユーザー名を指定します。 ユーザー名を指定した場合は、プロジェクト設定の通知設定のユーザー名は無視されます。 省略した場合は、プロジェクト設定の通知設定で指定されたユーザー名が使われます。 |
| Slack通知アイコン絵文字設定(省略可) |
通知する際の絵文字を指定します。 絵文字を指定した場合は、プロジェクト設定の通知設定の絵文字は無視されます。 省略した場合は、プロジェクト設定の通知設定で指定された絵文字が使われます。 |