機械学習
テキスト分析(コンテンツ分類)
概要
このブロックは、英文テキストを分析し、そのテキストがどのような種類のコンテンツに属するかを推測できます。たとえば、あるテキストが気象に関する記事なのか、医療に関する記事なのか、またはスポーツに関する記事なのかなどを推測できます。

留意事項
- このブロックは、Cloud Natural Language APIの「コンテンツ分類」機能を使用しています。
- 推測できるコンテンツの種類は、Googleのドキュメント「コンテンツ カテゴリ」を参照願います。
- 分析可能なテキストは、20個以上の単語を含む英文のみです。
- セルフサービスプランの場合は、このブロックを使用する前に、Cloud Natural Language APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント> Google APIを有効にする」を願います。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| テキストを参照する変数 | コンテンツ分類させたいテキストデータを参照する変数を指定します。 |
| 結果を格納する変数 |
コンテンツ分類した結果を格納する変数を指定します。 結果の詳細については、Googleのドキュメントを参照願います。 |
| ブロックメモ |
本ブロックに関するメモが記載できます。本ブロックの処理に影響しません。 |
使用例
ここでは、「テキスト分析(コンテンツ分類)」ブロックを使って、Googleスプレッドシート上のテキストデータからコンテンツ分類するケースを取り上げます。
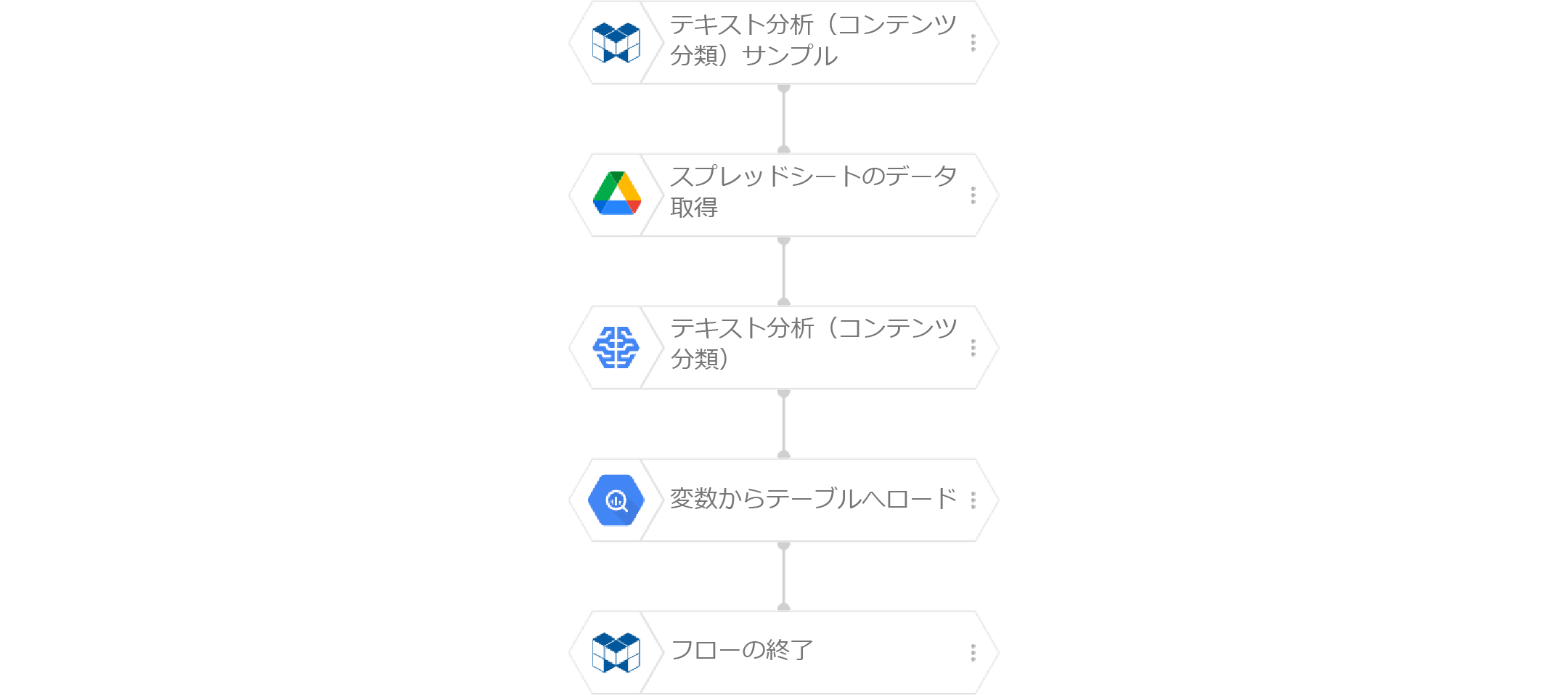
おおまかな流れは、以下のとおりです。
以下、上記流れに沿ってそれぞれについて解説します。
STEP1
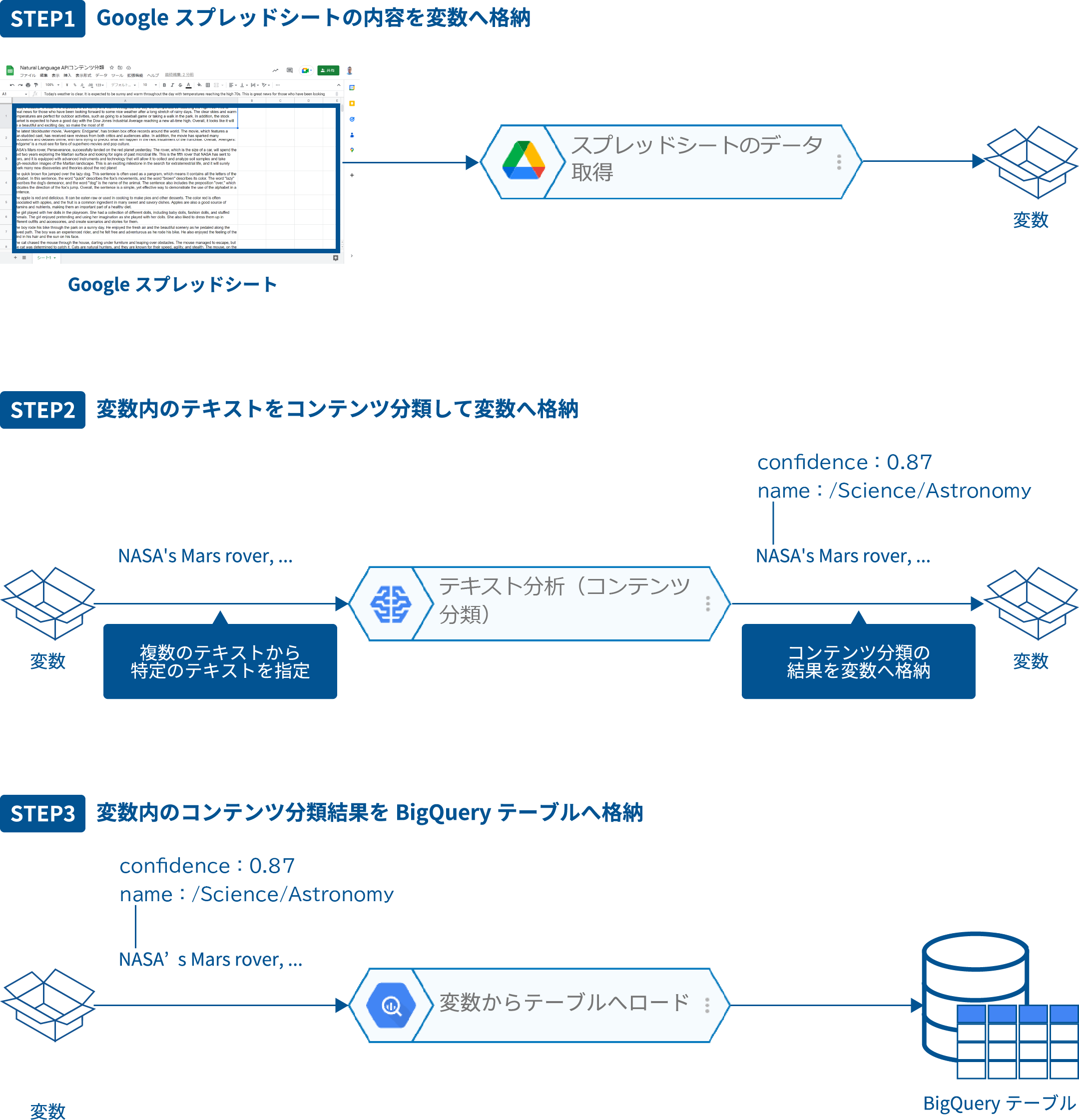
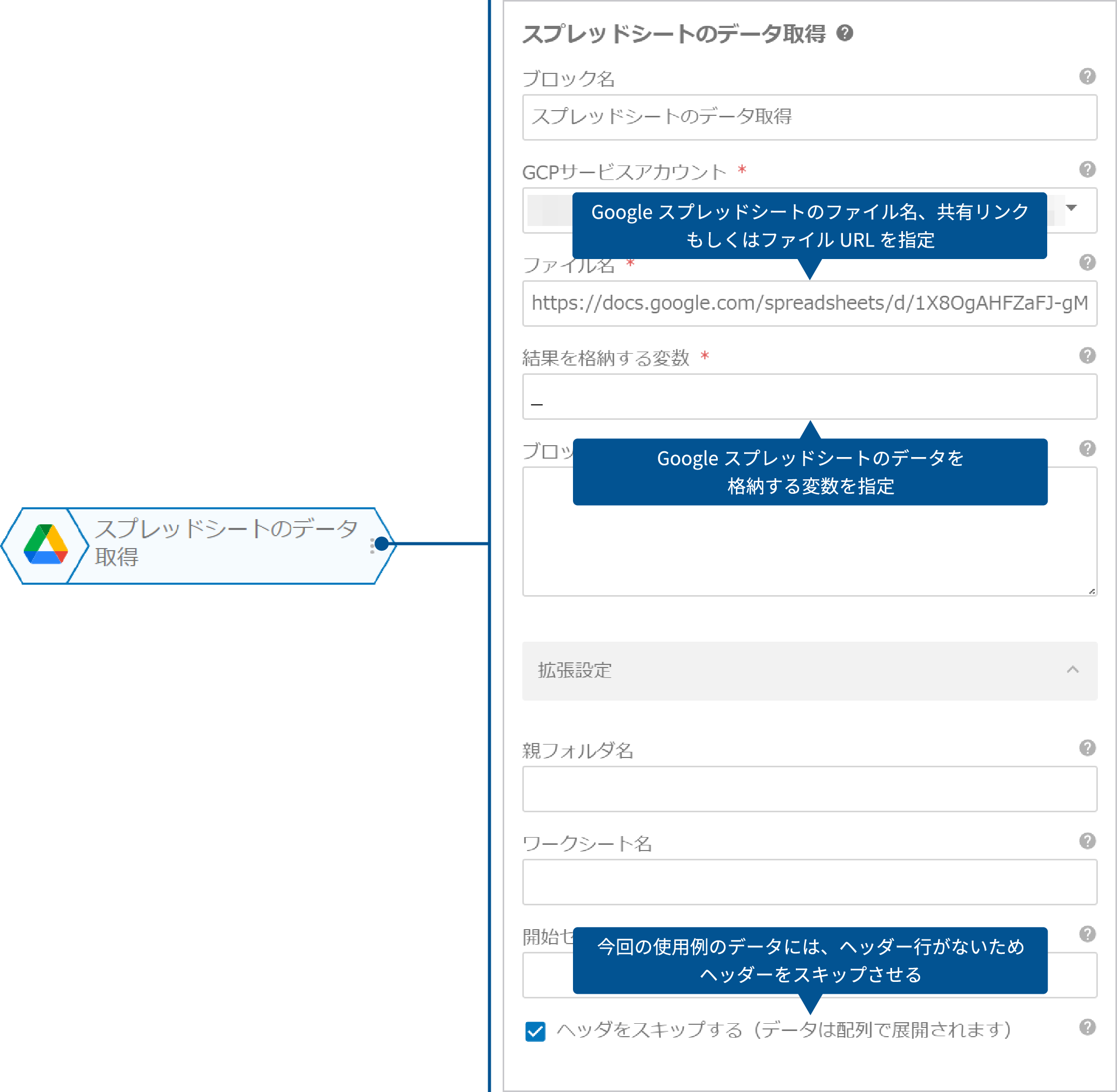
「テキスト分析(コンテンツ分類)」ブロックを使って、Googleスプレッドシート上のテキストデータからエンティティ分析するためには、Googleスプレッドシート上のテキストデータを変数へ格納する必要があります。
これは、Google Driveカテゴリーの「スプレッドシートのデータ取得」ブロックを使うと簡単に実現できます。
STEP2
「スプレッドシートのデータ取得」ブロックで変数_に格納されたデータは、以下のような配列の配列形式で出力されています。

外側の配列の各要素は、要素数1の配列で、内側の配列の要素がテキストになっています。
「テキスト分析(コンテンツ分類)」ブロックは、複数のテキストは扱えないので、今回のケースでは複数のテキストから1つのテキストのみを渡してあげる必要があります。
例えば、この配列の3個目のテキストを渡すには、_.2.0のように指定する必要があります。この記法については、「配列とオブジェクト」の「配列やオブジェクト内の一部データの取得書式」を参照願います。
以下は、変数_内の配列3個目に格納されているテキストをコンテンツ分類する例です。

STEP3
最後に、コンテンツ分類した結果を蓄積し、さまざまな用途に応用できるようにBigQueryテーブルに格納します。
変数内のデータをBigQueryテーブルへ格納するには、「変数からテーブルへロード」ブロックを使うと簡単です。
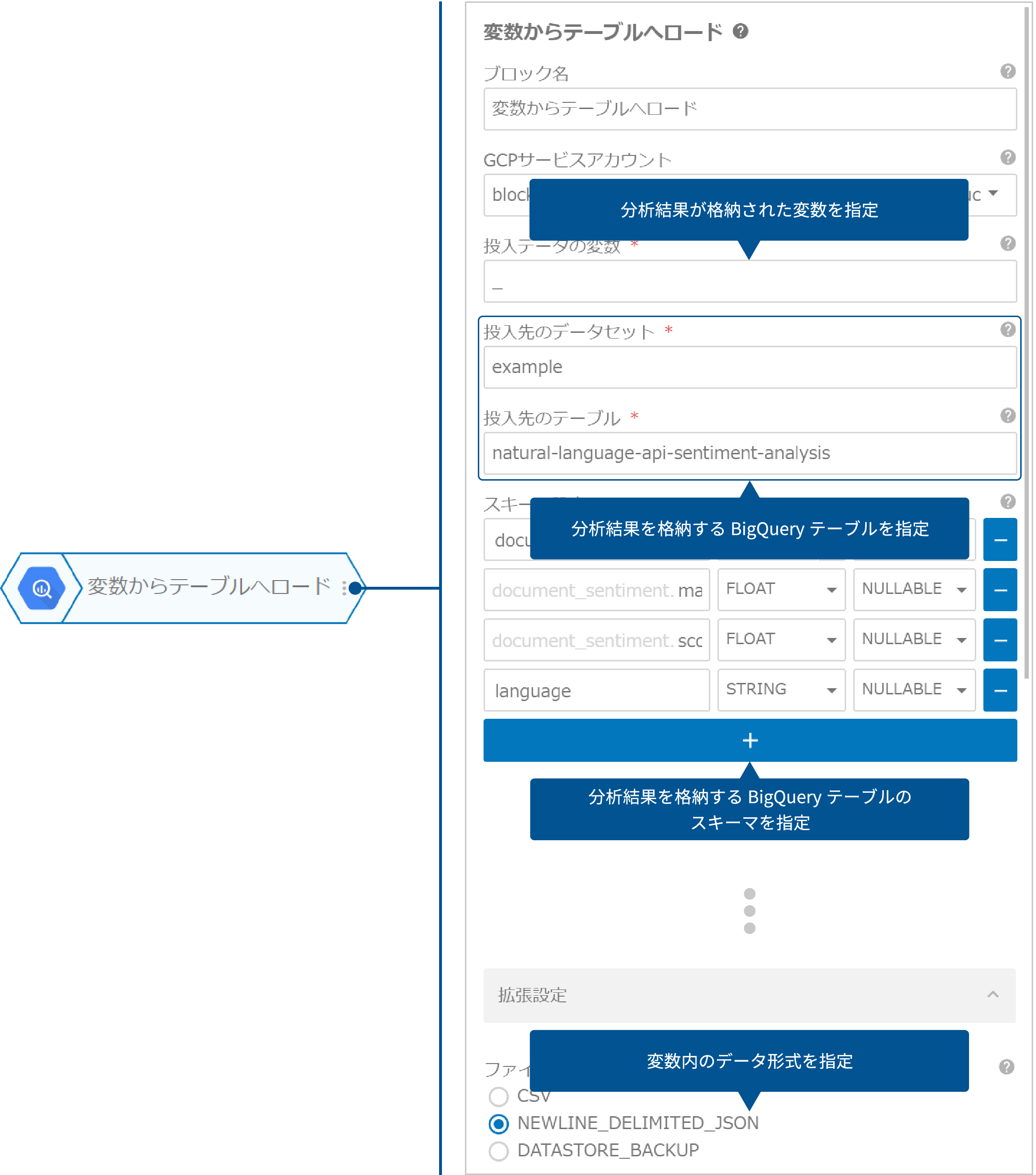
- スキーマ設定は、natural-language-api-content-classification-schema.jsonをダウンロードして、「JSONで編集」でJSONデータを貼り付けてください。
- ファイル形式は、変数内のデータ形式を指定します。「テキスト分析(コンテンツ分類)」ブロックの出力結果は、オブジェクトのためJSON形式(NEWLINE_DELIMITED_JSON)となります。
最後に
STEP1からSTEP3を順につなげるとフローの完成です。