BigQuery
クエリーの並列実行
概要
このブロックは、変数の内容によってBigQueryの複数のクエリーを並列に実行します。
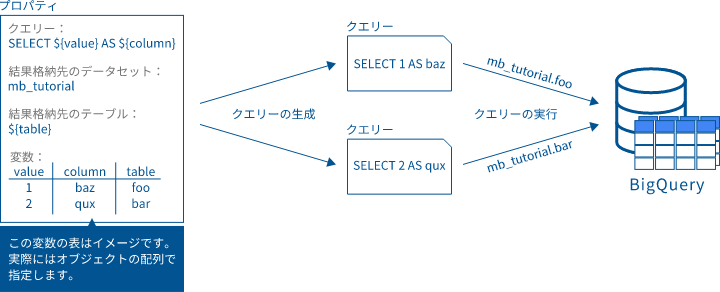
「複数パラメーターを参照する変数」で指定された配列の個数分のクエリーを並列に実行します。変数展開時は、この配列内のオブジェクトで指定されたものを優先的に参照します。なければ、フロー間共通変数およびフロー内実行変数を参照します。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| SQL文法 |
「クエリー」プロパティで使用するクエリーの文法を以下から選択します。 |
| クエリー |
実行するクエリーを指定します。 クエリ接頭辞( |
| クエリー内の%形式の文字列書式を有効にする |
クエリー内の%形式の文字列書式を有効にするかしないかを指定します。 チェックボックスにチェックを付けると、クエリー内の%形式の文字列書式が有効になります。チェックボックスのチェックを外すと、クエリー内の%形式の文字列書式が無効になります。 |
| 結果格納先のデータセット |
クエリー結果格納先のデータセットIDを指定します。 |
| 結果格納先のテーブル |
クエリー結果格納先のテーブルIDを指定します。 |
| 複数パラメーターを参照する変数 | 配列データを受け取る変数を指定します。指定内容が文字列のときはJSONとしてデコードしてから利用します。 |
| 空でないテーブルが存在したとき |
出力先のテーブルが存在したときの動作を選択します。 追加:追加で書き込みます。 |
| クエリーの優先度 |
クエリーの優先度を選択します。選択できる優先度は、次のいずれかです。
|
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 |
| 1000件以上の結果を許可する | 1000件以上の結果を含むクエリーの実行を許可します。「結果格納先のデータセット」および「結果格納先のテーブル」が省略された場合は、許可できません。 |
| フラットな結果を許可する | テーブルのネストしたフィールドを展開するかどうかを指定します。展開しないとした場合は、「1000件以上の結果を許可する」を許可にできません。 |
| クエリーキャッシュを有効にする | クエリーキャッシュを有効にするかしないかを指定します。 |
| ユーザー定義関数 | ユーザー定義関数(User Defined Function/UDF)機能を使用する場合に参照する関数定義を文字列で指定します。複数指定できます。 "gs://"で始まる文字列の場合は、URIとして解釈されて、対応するGCS上のオブジェクトから関数定義を読み込みます。 |
| 最大料金バイト数 | クエリーの料金を制限します。クエリーで処理するデータ量が、ここで指定されたバイト数を超える場合は、そのクエリーは実行されません(エラーとなり料金は発生しません)。 |
使用例
この例では、Googleスプレッドシートに保存されたキャンペーン情報を「スプレッドシートのデータ取得」ブロックで取得し、そのデータを「クエリーの並列実行」ブロックに渡すことで、各キャンペーンの分析を並列に実行します。分析結果は、キャンペーンごとに異なるBigQueryテーブルに格納されます。
まず、Googleスプレッドシートで以下のようなキャンペーン情報を準備します。
- Googleスプレッドシート名:キャンペーン情報
- シート名:パラメーター
- シート内容:
campaign_id target_channel result_table CAMP1 Email email_campain_results CAMP2 Social social_campain_results CAMP3 TV tv_campain_results
次に、「スプレッドシートのデータ取得」ブロックを使って、Googleスプレッドシートのデータを変数に格納します。このブロックでデータを変数に格納することで、「クエリーの並列実行」ブロックで期待されるデータ形式を準備します。
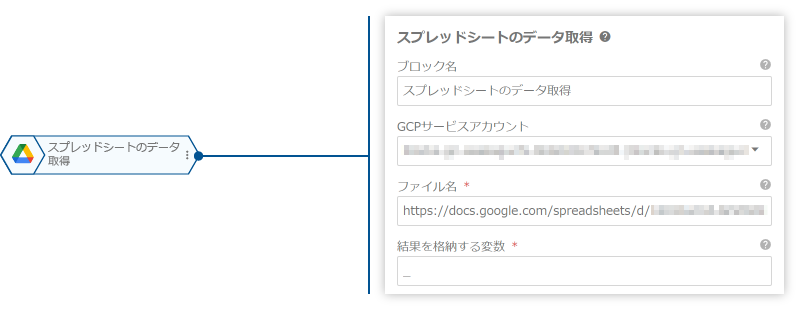
| プロパティ名 | 値 |
|---|---|
| ファイル名 | https://docs.google.com/spreadsheets/d/[キャンペーン情報のスプレッドシートID]
|
| 結果を格納する変数 | _ |
このブロックを実行すると、変数_には、スプレッドシートの各行がオブジェクトになった配列データが格納されます。
| [0] | [1] | [2] | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
最後に、「クエリーの並列実行」ブロックを使って、キャンペーンごとの分析を並列に実行します。各データは変数展開を使ってクエリーと格納先テーブルで参照することで、スプレッドシートの内容に応じて動的に処理できます。
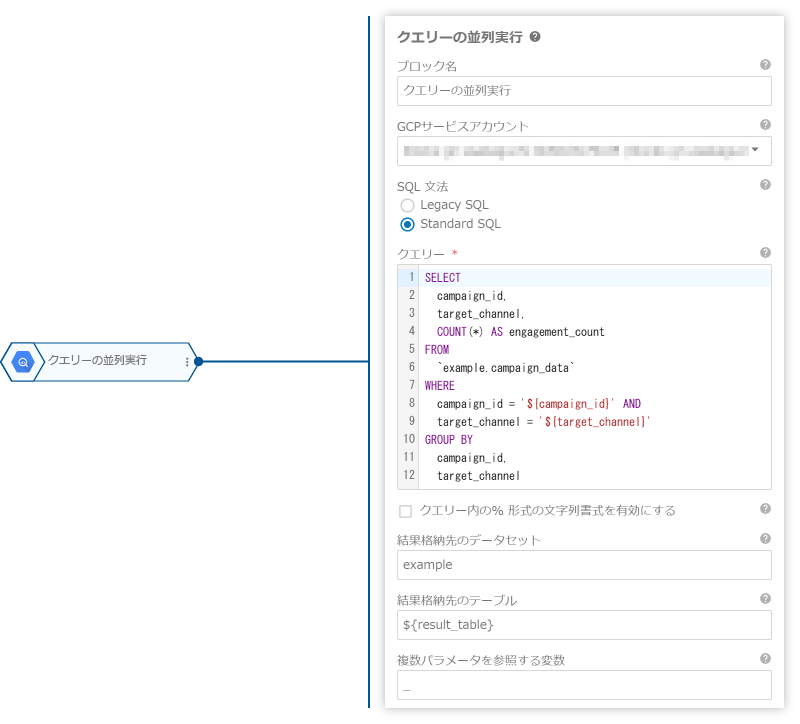
| プロパティ名 | 値 |
|---|---|
| クエリー |
SELECT
campaign_id,
target_channel,
COUNT(*) AS engagement_count
FROM
`example.campaign_data`
WHERE
campaign_id = '${campaign_id}' AND
target_channel = '${target_channel}'
GROUP BY
campaign_id,
target_channel
|
| 結果格納先のデータセット | example |
| 結果格納先のテーブル | ${result_table} |
| 複数パラメータを参照する変数 | _ |
このブロックを実行すると、以下のようにスプレッドシートの各行に対応したテーブルが作成されます。
- email_campain_results
campaign_id target_channel engagement_count CAMP1 Email 2 - social_campain_results
campaign_id target_channel engagement_count CAMP2 Social 2 - tv_campain_results
campaign_id target_channel engagement_count CAMP3 TV 2
この使用例は、「クエリーの並列実行」ブロックを活用してキャンペーンデータを自動的に集計・分析する一つの方法を示しています。このようなアプローチを応用することで、マーケティング施策の評価サイクルを迅速化し、PDCAを円滑に回せるようになる可能性があります。実際のビジネスでは、この例を参考にしつつ、各組織のデータ構造や分析ニーズに合わせて柔軟にカスタマイズしていくことが重要です。
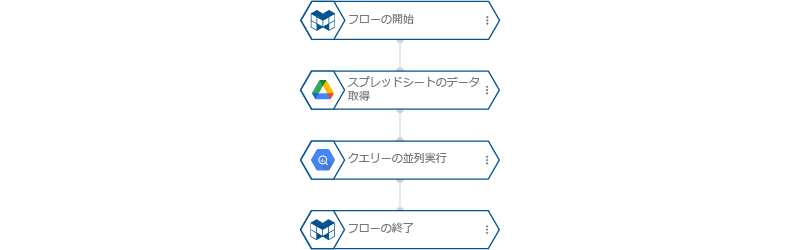
全体のフローは、下図の通りです。