機械学習
音声認識(音声認識モデル選択)
概要
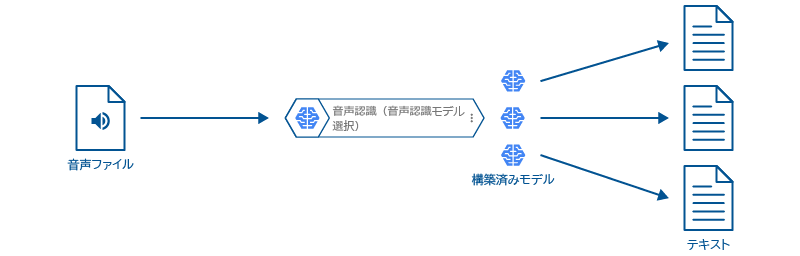
このブロックは、Cloud Speech-to-Textの構築済み音声認識モデルを利用して、通話や動画の音声をテキストに変換します。
情報
GoogleからCloud Speech-to-Textを効果的に使用するためのガイドライン「Best Practices」が公開されています。このブロックを使用する前に、一読されることをお薦めします。
注意
セルフサービスプランの場合は、このブロックを使用する前に、Cloud Speech-to-Text APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント>Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ブロック名 | ブロックの名前を指定します。ブロックに表示されます。 | ||||||||||||||||||
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 | ||||||||||||||||||
| 音声データのGCS上のURL |
音声データファイルが格納されているGCS上のURLを指定します。 |
||||||||||||||||||
| モデル |
構築済みの音声認識モデルを以下の中から選択します。
|
||||||||||||||||||
| 結果を格納する変数 |
音声を変換したテキストデータを格納する変数を指定します。 詳細については、「出力仕様>音声認識」を参照してください。 |
||||||||||||||||||
| 音声データのエンコーディング |
[音声データのGCS上のURL]プロパティで指定した音声データのエンコーディングを指定します。指定できるエンコーディングは、次のいずれかです。
音声認識で最良の結果を得るエンコーディングとして、FLACかLINEAR16の使用が推奨されています。詳しくは、基本操作ガイドの「Cloud Speech-to-Text APIの音声データのエンコーディングについて」を参照してください。各エンコーディングの説明と音声データの変換について解説しています。 |
||||||||||||||||||
| 音声データのサンプルレート |
[音声データのGCS上のURL]プロパティで指定した音声データのサンプルレートを8000から48000の間で指定します。単位は、ヘルツ(Hz)です。 最良の結果を得るための最適な値は、16000 Hzです。 |
||||||||||||||||||
| 音声データの言語コード |
[音声データのGCS上のURL]プロパティで指定した音声データの言語コードを指定します。例えば、日本語の場合は、[ja-JP]を指定します。 指定可能な言語コードのリストは、Language Supportで確認できます。 |
||||||||||||||||||
| ブロックメモ | ブロックに対するコメントを指定します。 | ||||||||||||||||||
| 最大変換候補数 |
音声データをテキストデータに変換する際、複数の変換候補を得ることができます。この[最大変換候補数]プロパティでは、この変換候補の最大数を0から30の間で指定します。 0か1を指定した場合、最大で1の変換候補補が得られます。 |
||||||||||||||||||
| 不適切な表現を取り除く | このプロパティを有効化すると、不適切な表現と思われるものを取り除きます。 | ||||||||||||||||||
| 音声認識のヒントとなる単語やフレーズ | 音声認識の精度を高めるための単語やフレーズを指定します。 |
使用例
GCSにアップロードされた音声データを処理し、結果を保存・出力するフローの一例を紹介します。
- 音声データをGCSにアップロード
- アップロードされた音声データを音声認識
- 音声認識の結果をBigQueryテーブルに保存
- BigQueryテーブルのデータをGoogleスプレッドシートに出力
情報
以下の使用例では、各ブロックのプロパティ設定について、デフォルト値をそのまま使用しているプロパティの説明は省略しています。明示的に値が指定されているプロパティは、デフォルト値から変更が必要な箇所です。
- 「フローの開始」ブロックでフローにIDを設定します。
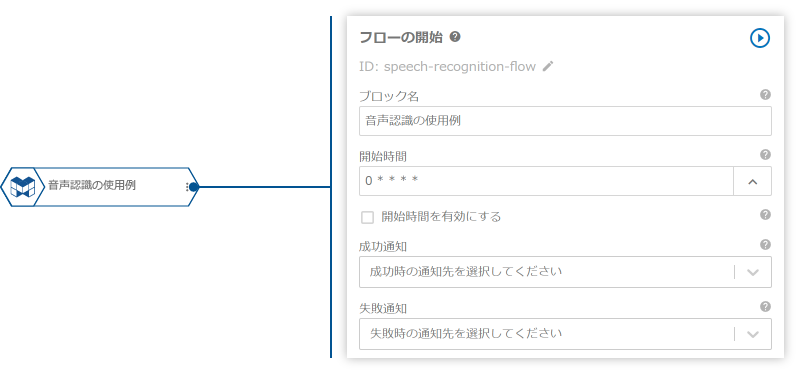
プロパティ名 値 ID speech-recognition-flowブロック名 音声認識の使用例ID設定時、GCSに音声データを配置するとフローが実行されるように設定します。
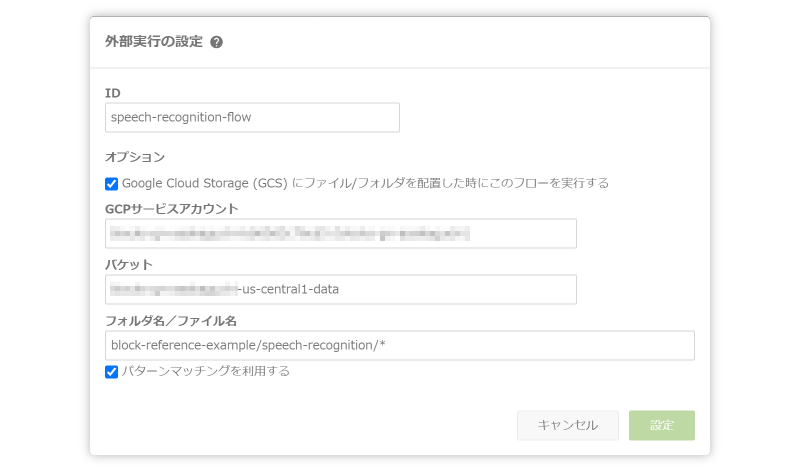
プロパティ名 値 Google Cloud Storage(GCS)上にファイル/フォルダを配置したときにフローを実行する GCSサービスアカウント デフォルトのGCSサービスアカウントを選択。複数ある場合は適切なものを選択。 バケット アップロード先のGCSバケットを設定 フォルダ名/ファイル名 block-reference-example/speech-recognition/* - 「音声認識(音声認識モデル選択)」ブロックで、GCS上の音声データを処理します。
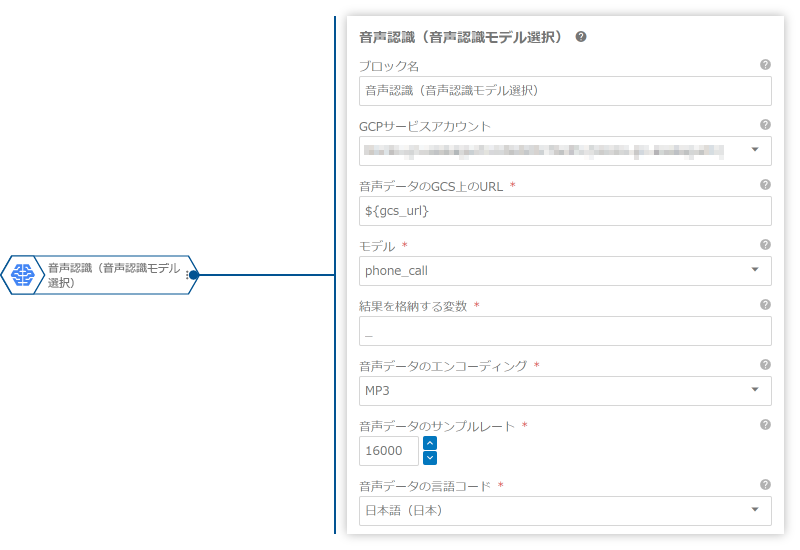
プロパティ名 値 音声データのGCS上のURL ${gcs_path}モデル phone_call音声データのエンコーディング MP3音声データの処理結果は、変数
_に格納されます。 - 「変数からテーブルへロード」ブロックを使って、処理結果をBigQueryのテーブルにロードします。
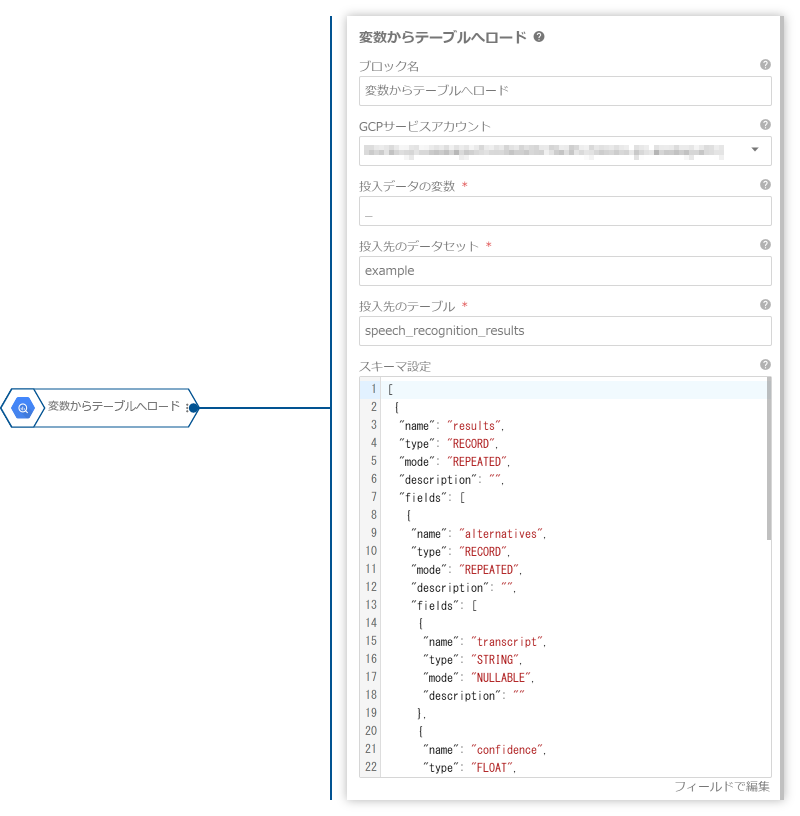
プロパティ名 値 投入先のデータセット example投入先のテーブル speech_recognition_resultsスキーマ設定 JSONで編集を使って、以下の内容を設定。[ { "name": "results", "type": "RECORD", "mode": "REPEATED", "description": "", "fields": [ { "name": "alternatives", "type": "RECORD", "mode": "REPEATED", "description": "", "fields": [ { "name": "transcript", "type": "STRING", "mode": "NULLABLE", "description": "" }, { "name": "confidence", "type": "FLOAT", "mode": "NULLABLE", "description": "" } ] }, { "name": "resultEndTime", "type": "STRING", "mode": "NULLABLE", "description": "" }, { "name": "languageCode", "type": "STRING", "mode": "NULLABLE", "description": "" } ] }, { "name": "gcs_url", "type": "STRING", "mode": "NULLABLE", "description": "" }, { "name": "timestamp", "type": "TIMESTAMP", "mode": "NULLABLE", "description": "" } ] - 「クエリーの結果からスプレッドシートを作成」ブロックを使って、BigQueryテーブルの内容をGoogleスプレッドシートに出力します。
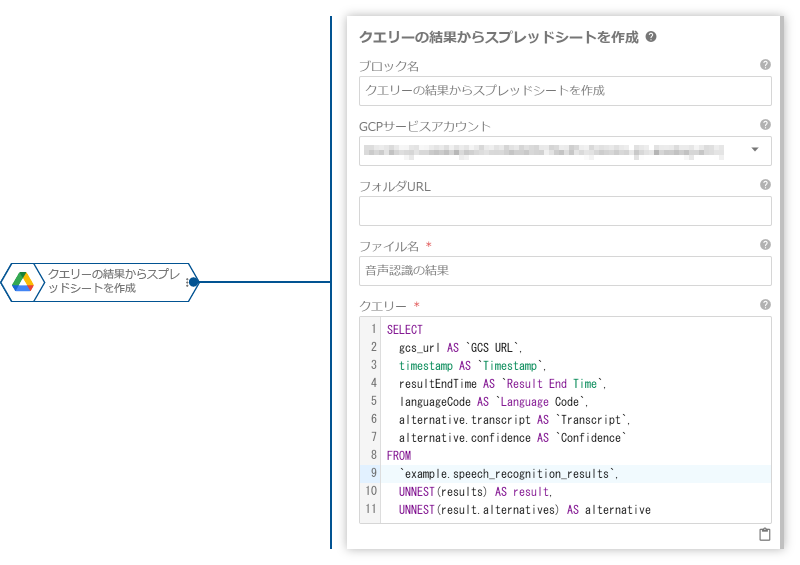
プロパティ名 値 ファイル名 音声認識の結果クエリー SELECT gcs_url AS `GCS URL`, timestamp AS `Timestamp`, resultEndTime AS `Result End Time`, languageCode AS `Language Code`, alternative.transcript AS `Transcript`, alternative.confidence AS `Confidence` FROM `example.speech_recognition_results`, UNNEST(results) AS result, UNNEST(result.alternatives) AS alternative
- 全体のフローは、以下のようになります。
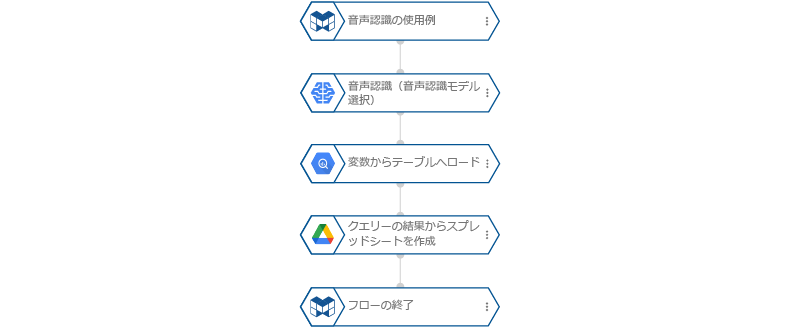
- これで、所定の場所に音声データを配置すると、フローが実行されます。以下は、Googleスプレッドシートの内容です。

注意
なお、この使用例で示したプロパティの設定値はあくまで一例です。実際にフローを作成する際は、ご自身の環境に合わせてGCPサービスアカウントやバケット名、データセット名、テーブル名などを適切な値に変更してください。