Google Cloud
Pub/Subパブリッシュ
概要
このブロックは、Google Cloud Pub/Subサービスのトピックにメッセージを送信(パブリッシュ)するためのものです。Pub/Subパブリッシュブロックを使用することで、異なるシステムやサービス間で非同期にデータやイベントを共有できます。
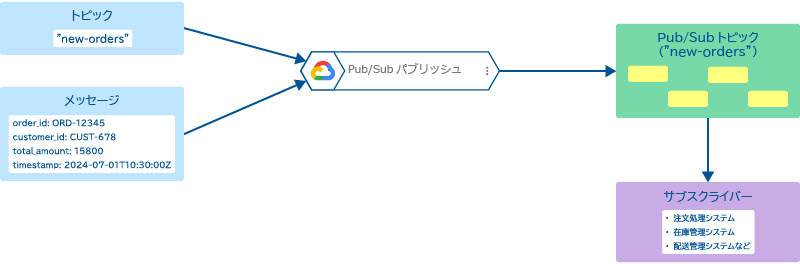
このブロックの主な特徴は、以下のとおりです。
- 指定されたPub/Subトピックへのメッセージのパブリッシュ
- フローで扱うデータと外部システムとの連携
- 大量メッセージの効率的な処理
これらの特徴により、フローデザイナー内で処理されたデータや情報を、柔軟かつ効率的に外部システムと共有することが可能になります。Pub/Subの非同期性と高いスケーラビリティを活かし、大規模なデータ処理や複雑なシステム間連携を実現できます。
フローデザイナーでのPub/Subパブリッシュブロックの活用例として、以下のようなシナリオが考えられます。
- 処理済みデータの外部データベースや分析システムへの送信
- 特定のステップ完了時の別システムでの処理開始
- 重要な処理ステップ完了のログシステムへの記録
これらは、実現可能なシナリオの一部です。実際の業務プロセスに合わせて、データの転送、システム間の連携、処理の自動化など、さまざまな用途でこのブロックを活用できます。
情報
このブロックはメッセージの送信のみを行います。メッセージの受信や処理には、別途Pub/Subと連携可能な他のシステムが必要です。
注意
セルフサービスプランの場合は、このブロックを使用する前に、Cloud Pub/Sub APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント>Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 | ブロックの名前を指定します。ブロックに表示されます。 |
| GCPサービスアカウント |
このブロックで使用するGCPサービスアカウントを選択します。 |
| トピック |
メッセージをパブリッシュするCloud Pub/SubのトピックのトピックIDを指定します。トピックIDは、トピックの一意の識別子で、トピック作成時に指定した名前です。 例: 補足 |
| メッセージを参照する変数 |
パブリッシュするメッセージを参照する変数を指定します。
|
| ブロックメモ | ブロックに対するコメントを指定します。 |
使用例
ここでは、「Pub/Subパブリッシュ」ブロックの使用例として、日次売上レポートの自動生成と配信のシナリオを紹介します。このシナリオは一例であり、「Pub/Subパブリッシュ」ブロックはさまざまな用途に応用できます。
このシナリオでは、毎日の売上データを自動的に集計し、レポートを生成して関係者に配信することを想定しています。具体的な流れは以下のとおりです。
- BigQueryで前日の売上データを集計
- 集計結果を加工してレポート形式に整形
- 「Pub/Subパブリッシュ」ブロックを使用してレポートデータを配信
- 配信されたデータを基に、メール配信システムが経営陣へレポートを送信(フロー外の処理)
- 同時に、ダッシュボードシステムがデータを受け取り、可視化を更新(フロー外の処理)
このフローは毎日午前5時に自動実行されるよう設定します。なお、4番目と5番目の処理はフローの実装範囲外であり、別途システムを構築する必要があります。
なお、この例では、以下のBigQueryテーブル構造を前提としています。実際の利用時には、お使いの環境に合わせてテーブル名やスキーマを適宜変更してください。
| order_id | order_date | customer_id | product_id | quantity | unit_price | total_price |
|---|---|---|---|---|---|---|
| ORD001 | 2024-07-01 | CUST001 | PROD001 | 2 | 100.00 | 200.00 |
| ORD002 | 2024-07-01 | CUST002 | PROD002 | 1 | 150.00 | 150.00 |
| ORD003 | 2024-07-01 | CUST003 | PROD003 | 1 | 75.00 | 225.00 |
| 名前 | タイプ | モード | 説明 |
|---|---|---|---|
| order_id | STRING | REQUIRED | 注文ID |
| order_date | DATE | REQUIRED | 注文日 |
| customer_id | STRING | REQUIRED | 顧客ID |
| product_id | STRING | REQUIRED | 商品ID |
| quantity | INTEGER | REQUIRED | 数量 |
| unit_price | FLOAT | REQUIRED | 単価 |
| total_price | FLOAT | REQUIRED | 合計金額 |
| product_id | product_name | category |
|---|---|---|
| PROD001 | ノートPC | エレクトロニクス |
| PROD002 | スマートフォン | エレクトロニクス |
| PROD003 | ヘッドフォン | アクセサリー |
| 名前 | タイプ | モード | 説明 |
|---|---|---|---|
| product_id | STRING | REQUIRED | 商品ID |
| product_name | STRING | REQUIRED | 商品名 |
| category | STRING | REQUIRED | カテゴリー |
情報
この使用例は、「Pub/Subパブリッシュ」ブロックの活用方法を示すための想定シナリオです。実際の実装では、ビジネスニーズや既存システムの状況に応じて、適切なカスタマイズが必要になります。
それでは、このシナリオを実現するための具体的なフローの実装例を紹介します。
以下の例では、「クエリーの実行」ブロックによるBigQueryでのデータ集計から、「Pub/Subパブリッシュ」ブロックによるデータ配信までの流れを示します。
情報
この実装例は基本的な構成を示すものであり、実際の使用時には必要に応じてカスタマイズできます。
- 「フローの開始」ブロックで、毎日午前5時に自動実行されるように設定します。
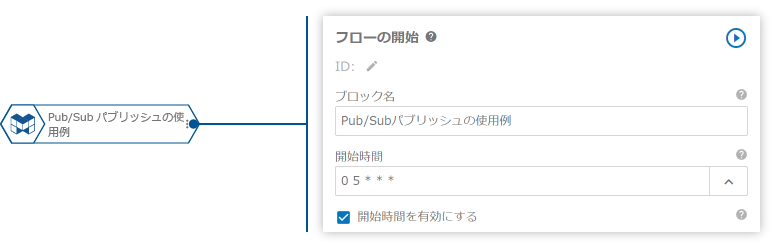
プロパティ名 値 ブロック名 Pub/Subパブリッシュの使用例開始時間 0 5 * * *開始時間を有効にする - 「クエリーの実行」ブロックで、「BigQueryで前日の売上データを集計」と「集計結果を加工してレポート形式に整形」をまとめて処理します。
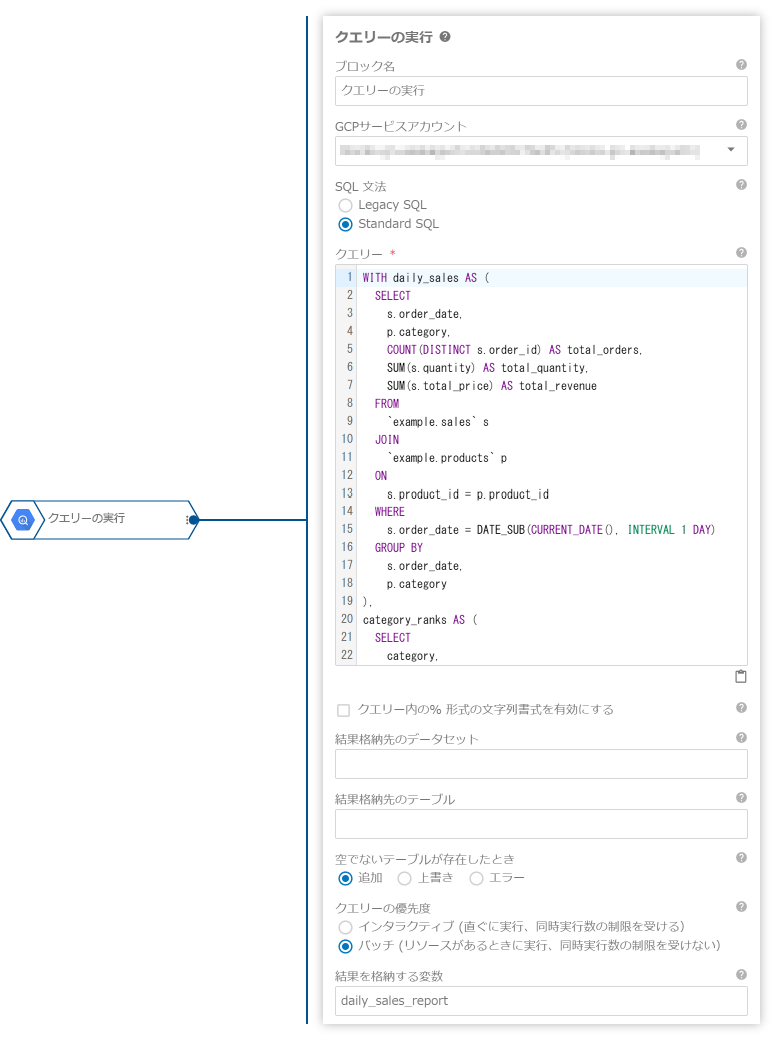
プロパティ名 値 クエリー WITH daily_sales AS ( SELECT s.order_date, p.category, COUNT(DISTINCT s.order_id) AS total_orders, SUM(s.quantity) AS total_quantity, SUM(s.total_price) AS total_revenue FROM `example.sales` s JOIN `example.products` p ON s.product_id = p.product_id WHERE s.order_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY) GROUP BY s.order_date, p.category ), category_ranks AS ( SELECT category, total_revenue, RANK() OVER (ORDER BY total_revenue DESC) AS revenue_rank FROM daily_sales ) SELECT ds.order_date, ds.category, ds.total_orders, ds.total_quantity, ds.total_revenue, cr.revenue_rank, ROUND(ds.total_revenue / SUM(ds.total_revenue) OVER(), 4) AS revenue_percentage FROM daily_sales ds JOIN category_ranks cr ON ds.category = cr.category ORDER BY cr.revenue_rank結果を格納する変数 daily_sales_reportこのクエリーを実行すると、
daily_sales_report変数に以下のようなデータが格納されます(実際にはオブジェクトの配列形式)。daily_sales_report変数の内容(例): order_date category total_orders total_quantity total_revenue revenue_rank revenue_percentage 2024-07-01 エレクトロニクス 2 3 350.00 1 0.6087 2024-07-01 アクセサリー 1 3 225.00 2 0.3913 - 「Pub/Subパブリッシュ」ブロックで、集計したデータを配信します。
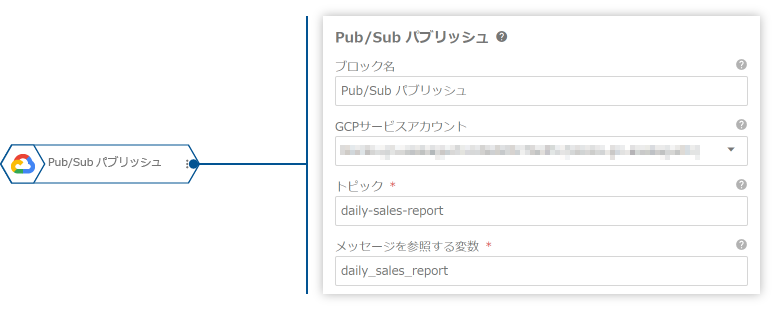
プロパティ名 値 トピック daily-sales-reportメッセージを参照する変数 daily_sales_report「Pub/Subパブリッシュ」ブロックでは、「メッセージを参照する変数」の内容がJSON形式のテキストに変換されて送信されます。この例では、
daily_sales_report変数の内容が以下のようなJSON形式で配信されます。[ { "order_date": "2024-07-01", "category": "エレクトロニクス", "total_orders": 2, "total_quantity": 3, "total_revenue": 350.00, "revenue_rank": 1, "revenue_percentage": 0.6087 }, { "order_date": "2024-07-01", "category": "アクセサリー", "total_orders": 1, "total_quantity": 3, "total_revenue": 225.00, "revenue_rank": 2, "revenue_percentage": 0.3913 } ]この形式で配信されたデータは、Pub/Subのサブスクライバーが容易に解析し、処理できます。
完成したフローは以下のとおりです。
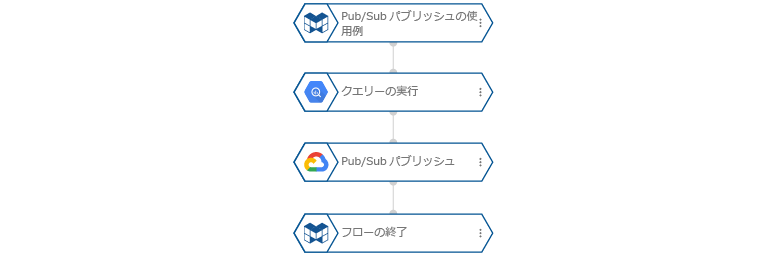
この使用例では、「Pub/Subパブリッシュ」ブロックを活用して、日次売上レポートの自動生成と配信を実現しました。このフローは以下の特徴を持っています。
- 毎日午前5時の自動実行による人手を介さないレポート生成
- 「クエリーの実行」ブロックによるBigQueryを使用した大量データの効率的処理と必要情報の抽出
- 「Pub/Subパブリッシュ」ブロックによる生成レポートデータの柔軟な配信
- Pub/Subの特性を活かした複数システム(メール配信、ダッシュボード更新など)への同時データ提供
この例は「Pub/Subパブリッシュ」ブロックの基本的な使用方法を示していますが、実際の業務においては、より複雑なデータ処理や、複数のデータソースの統合、さらには機械学習モデルの予測結果の配信など、さまざまな応用が可能です。ビジネスニーズに合わせて、このフローをカスタマイズし、より高度な自動化や意思決定支援システムを構築できます。