文書(限定公開)
文書間のコサイン類似度を計算
notificationsこのカテゴリーのブロックは限定公開です。利用にあたってはライセンス購入申請が必要です。このカテゴリーのブロックを使用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
概要
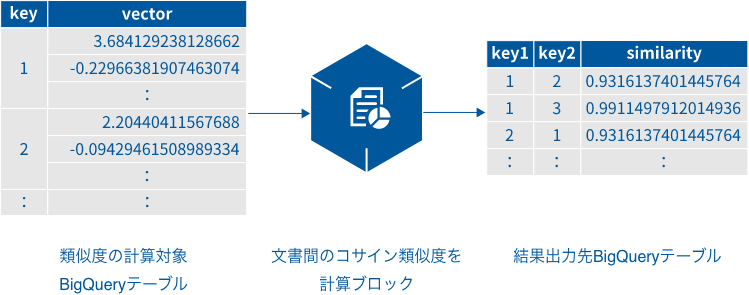
このブロックは、文書間のコサイン類似度を計算します。ここで言う文書とは、[文書のベクトル化(TF-IDF)]ブロックや[文書のベクトル化(doc2vec)]ブロックで、ベクトル化されたデータを指します。
info_outline「単語のベクトル化(word2vec)」ブロックでベクトル化されたデータもカラム名を変更することで、このブロックで単語間のコサイン類似度が計算できます。
対応する言語は、日本語と英語のみです。
-
「類似度の計算対象BigQueryテーブル」には、文書を特定するキーを持つkey列と文書のベクトルデータを持つvector列が必要です。
info_outline「単語のベクトル化(word2vec)」ブロックの出力を指定する場合は、事前にword列をkey列に名称変更してください。
下図は「クエリーの実行」ブロックで、word列をkey列に名称変更して、「文書間のコサイン類似度を計算」ブロックを利用する一例です。
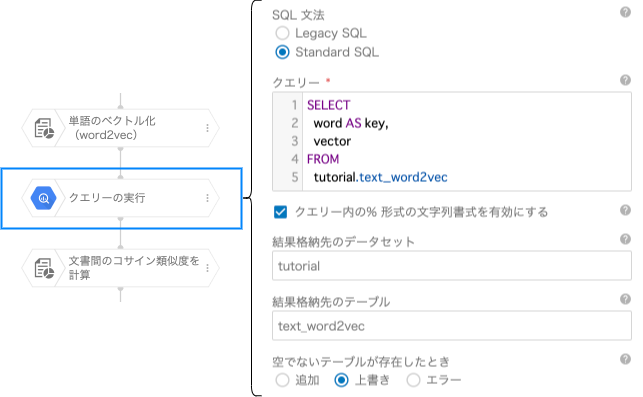
上図の「単語のベクトル化(word2vec)」ブロックの結果出力先BigQueryのデータセットとテーブルは、それぞれtutorialとtext_wotd2vecの想定です。
-
「結果出力先BigQueryテーブル」は、key1列・key2列・similarity列で構成されます。
- key1・key2列:各文書へのキーです。
- similarity列:key1・key2が示す文書間の類似度です。
- 文書内の組合せや同一キーの組み合せは類似度の算出対象外です。
セルフサービスプランの場合は、このブロックを使用する前に、Dataflow APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント> Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| 類似度の計算対象BigQueryデータセット |
[類似度の計算対象BigQueryテーブル]プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 |
| 類似度の計算対象BigQueryテーブル |
文書間の類似度を計算したい文書(ベクトルデータ)が格納されているBigQueryテーブルのIDを指定します。 |
| 結果出力先BigQueryデータセット |
[結果出力先BigQueryテーブル]プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 |
| 結果出力先BigQueryテーブル |
文書間のコサイン類似度を出力するBigQueryテーブルのIDを指定します。 空でないテーブルが存在する場合は、空にして上書きします。 |
| 類似度の計算対象BigQueryデータセット(CROSS JOINするテーブルのデータセット) |
[類似度の計算対象BigQueryテーブル(CROSS JOINするテーブル)]のデータセットのIDを指定します。 2つのテーブルに格納されたベクトルデータ同士をCROSS JOINして類似度計算をする場合に使用します。 |
| 類似度の計算対象BigQueryテーブル(CROSS JOINするテーブル) |
文書間の類似度を計算したい文書(ベクトルデータ)が格納されているBigQueryテーブルのIDを指定します。 2つのテーブルに格納されたベクトルデータ同士をCROSS JOINして類似度計算をする場合に使用します。 このテーブルが指定された場合は、[類似度の計算対象BigQueryテーブル]の文書との組合せの類似度のみ算出します(下図参照)。 
[類似度の計算対象BigQueryテーブル]の文書内の組合せ、このテーブルの文書内の組合せや同一キーの組み合せは算出対象外です(下図は同一キーが除外されている例)。 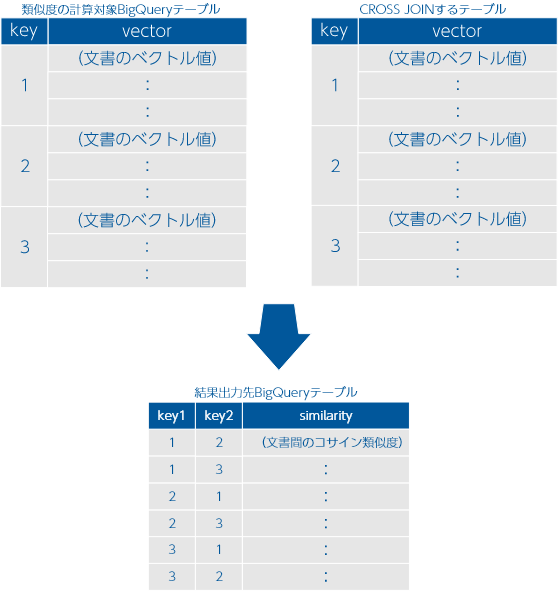
|
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 |