文書(限定公開)
文書のクラスタリング(k平均法)
notificationsこのカテゴリーのブロックは限定公開です。利用にあたってはライセンス購入申請が必要です。このカテゴリーのブロックを使用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
概要
このブロックは、k平均法(k-means)open_in_new方式を使って、複数の文書を類似する特徴で自動的にグルーピングします。
info_outlineここで言う文書とは、[文書のベクトル化(TF-IDF)]ブロックや[文書のベクトル化(doc2vec)]ブロックで、ベクトル化されたデータを指します。
このブロックを使うことで、テキストマイニングopen_in_newにおける文書分類が容易になります。
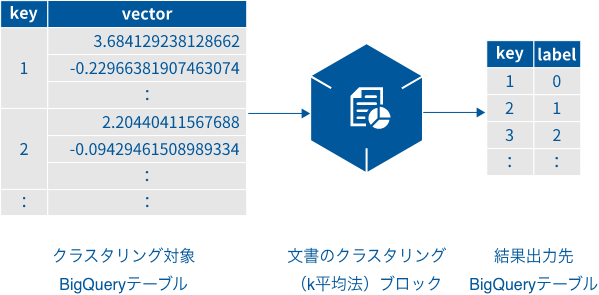
- 「クラスタリング対象BigQueryテーブル」には、文書を一意に特定するキーを持つ列と文書のベクトル値を持つ列が必要で、以下の列名を期待しています。
列名 説明 key 文書を一意に特定するキーを持つ列 vector 文書のベクトル値を持つ列 上記と異なる列名でも問題ありません。その場合は、「クラスタリング対象BigQueryテーブル」内のどの列がどの役割かを別途指定する必要があります(「キーの列名」プロパティと「ベクトルの列名」プロパティ)。
-
「結果出力先BigQueryテーブル」は、key列とlabel列で構成されます。
列名 説明 key 各文書を一意に特定するキーです。 label keyが示す文書のクラスタリング結果のラベルです。
セルフサービスプランの場合は、このブロックを使用する前に、Dataflow APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント> Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 | ブロックの名前を指定します。ブロックに表示されます。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| クラスタリング対象BigQueryデータセット |
[クラスタリング対象BigQueryテーブル]プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 warning「クラスタリング対象BigQueryデータセット」・「結果出力先BigQueryデータセット」・「一時フォルダーGCS URL」のロケーションは合わせる必要があります。BigQueryのデータセットがUSマルチリージョンの場合は、この限りではありません。 |
| クラスタリング対象BigQueryテーブル |
クラスタリングしたい文書(ベクトルデータ)が格納されているBigQueryテーブルのIDを指定します。 |
| 結果出力先BigQueryデータセット |
[結果出力先BigQueryテーブル]プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 warning「クラスタリング対象BigQueryデータセット」・「結果出力先BigQueryデータセット」・「一時フォルダーGCS URL」のロケーションは合わせる必要があります。BigQueryのデータセットがUSマルチリージョンの場合は、この限りではありません。 |
| 結果出力先BigQueryテーブル |
文書のクラスタリング結果のラベルを出力するBigQueryテーブルのIDを指定します。 空でないテーブルが存在する場合は、空にして上書きします。 |
| 一時フォルダーGCS URL |
このブロックの内部処理で一時的に使用するGCS上のフォルダーを指定します。 内部処理中に、このフォルダーに一時的なファイルが作成されますが、処理終了後は削除されます。 warning「クラスタリング対象BigQueryデータセット」・「結果出力先BigQueryデータセット」・「一時フォルダーGCS URL」のロケーションは合わせる必要があります。BigQueryのデータセットがUSマルチリージョンの場合は、この限りではありません。 |
| ブロックメモ | ブロックに対するコメントを指定します。 |
| キーの列名 |
[クラスタリング対象BigQueryテーブル]で各文書を一意に識別する値が格納された列名を指定します(初期値: |
| ベクトルの列名 |
[クラスタリング対象BigQueryテーブル]で文書のベクトル値が格納された列名を指定します(初期値: |